
Gleich drei neue Methoden zeigen, wie Stable Diffusion oder Imagen für das Robotik-Training eingesetzt werden können.
Große Sprachmodelle wurden im letzten Jahr immer häufiger in der Robotik eingesetzt, besonders Google zeigte gleich mehrere Beispiele, darunter etwa SayCan oder Inner Monologue. Die Modelle bringen umfangreiches Wissen über die Welt, rudimentäre Logikfähigkeiten oder Übersetzungen von Sprache in Code in die Robotik und erlauben so bessere Planung mit Feedback oder eine Steuerung per Sprachanweisung.
Mit den Diffusionsmodellen wenden die Forschenden nun die nächste Klasse großer KI-Modelle auf die Robotik an. Mit dem generativen Bildmodell versuchen sie, eines der zentralen Probleme des Robotertrainings zu lösen: den Mangel an Trainingsdaten.
Datenmultiplikation mit generativen Bildmodellen
Das Sammeln von Daten ist in der Robotik extrem zeitaufwändig: Ein Datensatz von Google mit 130.000 Interaktionen von Roboterarmen wurde mit 13 Robotern über einen Zeitraum von 17 Monaten aufgezeichnet. Die Forschung sucht daher nach Möglichkeiten, diesen Prozess zu beschleunigen. Eine davon ist Sim2Real, also das Training in einer Simulation. Allerdings gelten reale Trainingsdaten nach wie vor als Goldstandard.
Unendliche Trainingsdatendank Diffusionsmodell? Google zeigt, wie das möglich sein könnte. | Video: Google
Können diese Daten mit generativen KI-Modellen erweitert werden? Diese Frage stellen sich mehrere Forschungsgruppen und zeigen in verschiedenen Arbeiten, dass die Erweiterung der Trainingsdaten mit Diffusionsmodellen tatsächlich zu besseren Robotern führt. Dazu nutzen die Teams die bereits vorhandenen Aufnahmen und erstellen zahlreiche Varianten mit unterschiedlichen Details: Mal verändern sie das Waschbecken, ein Tisch wird zur Küchenablage, neben einer Dose steht ein nie gesehener Gegenstand oder das Objekt, das ein Roboterarm in der Szene greift, verändert sich.
ROSIE, GenAug, CACTI und DALL-E-Bot zeigen vielversprechende Ergebnisse
Eine der ersten Arbeiten, die Diffusionsmodelle für die Robotik nutzt, heißt DALL-E-Bot und wurde bereits im November 2022 vorgestellt. Forschende des Imperial College London modifizierten einfache Küchenbilder mit OpenAI DALL-E 2, um einen Roboterarm zu trainieren. Dabei wurde DALL-E 2 verwendet, um aus einer vorhandenen Szene, zum Beispiel einem Teller und Besteck, per Textbeschreibung eine neue gewünschte Anordnung der Objekte zu erzeugen, die dem Roboter dann als Vorlage für seine Aufgabe diente.
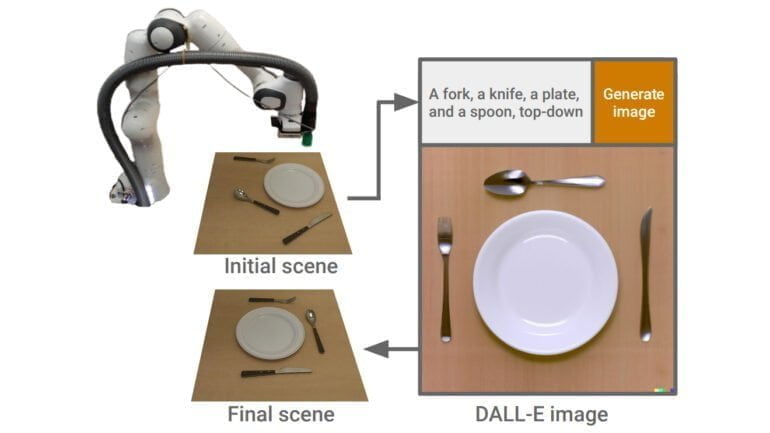
Nun haben drei weitere Gruppen verschiedene Methoden vorgestellt. Zwei davon - "Robot Learning with Semantically Imagined Experience" (ROSIE) von Google und CACTI von Forschenden der Columbia University, Carnegie Mellon University und Meta AI - nutzen Diffusionsmodelle, um Trainingsdaten fotorealistisch zu erweitern.
Das dritte Projekt - GenAug von der University of Washington und ebenfalls von Meta - basiert auf einer ähnlichen Idee, nutzt aber Tiefeninformationen, um bestehende und neue Objekte in Szenen mit einem tiefengeführten Diffusionsmodell zu verändern oder neu zu generieren. Das Team verspricht sich davon eine genauere Darstellung der ursprünglichen Szene.

Video: Meta
Alle Methoden zeigen, dass die Erweiterung der Daten zu robusteren Robotern führt, die auch mit vorher ungesehenen Objekten besser umgehen können. CACTI setzt für die Erweiterung auf Stable Diffusion. Google hingegen nutzt das eigene Imagen-Modell und den riesigen Datensatz von 130.000 Demonstrationen, um ein RT-1 Robotermodell zu trainieren. Google zeigt auch in Versuchen in der realen Welt, dass die Roboter Aufgaben ausführen können, die sie nur durch die Linse der Bildsynthese gesehen haben, z.B. das Aufheben von Objekten, die sie vorher nur in den von Imagen manipulierten Bildern gesehen haben.
Die "Bitter Lesson 2.0" und Foundation Models
Einschränkungen sieht z.B. Google darin, dass Diffusionsmodelle relativ viel Rechenleistung benötigen, was die Anzahl der Erweiterungen einschränkt. Zudem verändern die vorgestellten Methoden zwar das Aussehen von Objekten oder ganzen Szenen, erzeugen aber keine neuen Bewegungen - diese müssen weiterhin über menschliche Demonstrationen gesammelt werden. Google sieht hier Potenzial in Simulationsdaten als Quelle für umfangreiche Datensätze von Roboterbewegungen. Zudem könnten die anspruchsvollen Diffusionsmodelle durch Modelle wie Muse ersetzt werden, die etwa zehnmal effizienter sind.
Der Google-Robotikforscher und Stanford-Professor Karol Hausman sieht in den drei vorgestellten Methoden ein Beispiel für die von ihm ausgerufene "Bitter Lesson 2.0", nach der die Robotik auf der Suche nach neuen Methoden zum Bau von Allzweckrobotern auf Trends außerhalb der Robotik zurückgreifen sollte. Die "Bitter Lesson" geht auf einen Aufsatz des KI-Pioniers Richard Sutton zurück.
Bitter lesson by @RichardSSutton is one of the most insightful essays on AI development of the last decades.
Recently, given our progress in robotics, I’ve been trying to predict what the next bitter lesson will be in robotics and how can we prevent it today.
Let me explain 🧵 pic.twitter.com/0TeiRykOlU
— Karol Hausman (@hausman_k) January 9, 2023
Laut Hausman ist dieser Trend "Foundation Models", also große KI-Modelle wie GPT-3, PaLM oder Stable Diffusion. Er fasst seine Überzeugung wie folgt zusammen: "Die wichtigste Lehre aus weiteren 70 Jahren KI-Forschung wird sein, dass generische Methoden, die Foundation Modelle verwenden, letztlich am effektivsten sind".
Die bisherigen Experimente mit Sprach- und Bildmodellen scheinen ihm recht zu geben. In Zukunft könnten zudem weitere Modelle entstehen, die neue Datenmodalitäten für das Robotertraining liefern.




