Google veröffentlicht Gemini 3.1 Pro und verspricht stärkere Reasoning-Leistung
Kurz & Knapp
- Google hat Gemini 3.1 Pro vorgestellt, ein Upgrade seiner Modellfamilie, das vor allem beim logischen Schlussfolgern deutlich zulegt.
- Auf dem ARC-AGI-2-Benchmark für abstrakte Logikaufgaben erreicht das Modell 77,1 Prozent – mehr als doppelt so viel wie der Vorgänger Gemini 3 Pro (31,1 Prozent) und laut Google auch deutlich mehr als Anthropics Opus 4.6 (68,8 Prozent) und OpenAIs GPT-5.2 (52,9 Prozent).
- Das Modell ist ab sofort als Preview über die Gemini API, Google AI Studio, Vertex AI, die Gemini-App und NotebookLM verfügbar.
Mit Gemini 3.1 Pro will Google die Kernintelligenz seiner Modellfamilie deutlich verbessern. Auf einem anspruchsvollen Reasoning-Benchmark hat sich die Leistung im Vergleich zum Vorgänger mehr als verdoppelt. Allerdings sind Benchmarks nur eben diese.
Google hat Gemini 3.1 Pro vorgestellt, ein Upgrade der Gemini-3-Serie, das laut dem Unternehmen einen deutlichen Sprung bei der Problemlösungsfähigkeit markieren soll. Das Modell werde ab sofort als Preview für Entwickler, Unternehmen und Endnutzer ausgerollt.
Gemini 3.1 Pro sei für Aufgaben konzipiert, "bei denen eine einfache Antwort nicht ausreicht", schreibt das Gemini-Team im offiziellen Blogpost. Google beschreibt das Modell als die verbesserte Basisintelligenz, die auch den Durchbrüchen des eine Woche zuvor aktualisierten Gemini 3 Deep Think zugrunde liege. Deep Think ziele auf komplexe Aufgaben in Wissenschaft, Forschung und Ingenieurwesen ab; 3.1 Pro solle diese Fortschritte nun in alltägliche Anwendungen bringen.
Mehr als doppelte Reasoning-Leistung auf ARC-AGI-2
Den deutlichsten Leistungssprung zeigt Google anhand des ARC-AGI-2-Benchmarks für abstrakte Logikaufgaben: Gemini 3.1 Pro erreicht dort laut Google 77,1 Prozent, mehr als das Doppelte der 31,1 Prozent von Gemini 3 Pro. Auch Anthropics Opus 4.6 (68,8 Prozent) und OpenAIs GPT-5.2 (52,9 Prozent) liegen nach Googles Angaben deutlich dahinter. Allerdings haben andere KI-Systeme noch höhere Punktzahlen erreicht, ohne die KI-Welt grundlegend zu verändern.
Auch in weiteren Benchmarks soll 3.1 Pro überwiegend führen, darunter GPQA Diamond für wissenschaftliches Wissen (94,3 Prozent), SWE-Bench Verified für agentisches Coding (80,6 Prozent, fast gleichauf mit Opus 4.6 bei 80,8 Prozent) und mehrere agentische Benchmarks wie MCP Atlas (69,2 Prozent) und BrowseComp (85,9 Prozent). Bei LiveCodeBench Pro, einem Wettbewerbs-Coding-Benchmark, erreicht das Modell einen Elo-Wert von 2887 und übertrifft damit sowohl Gemini 3 Pro (2439) als auch GPT-5.2 (2393).
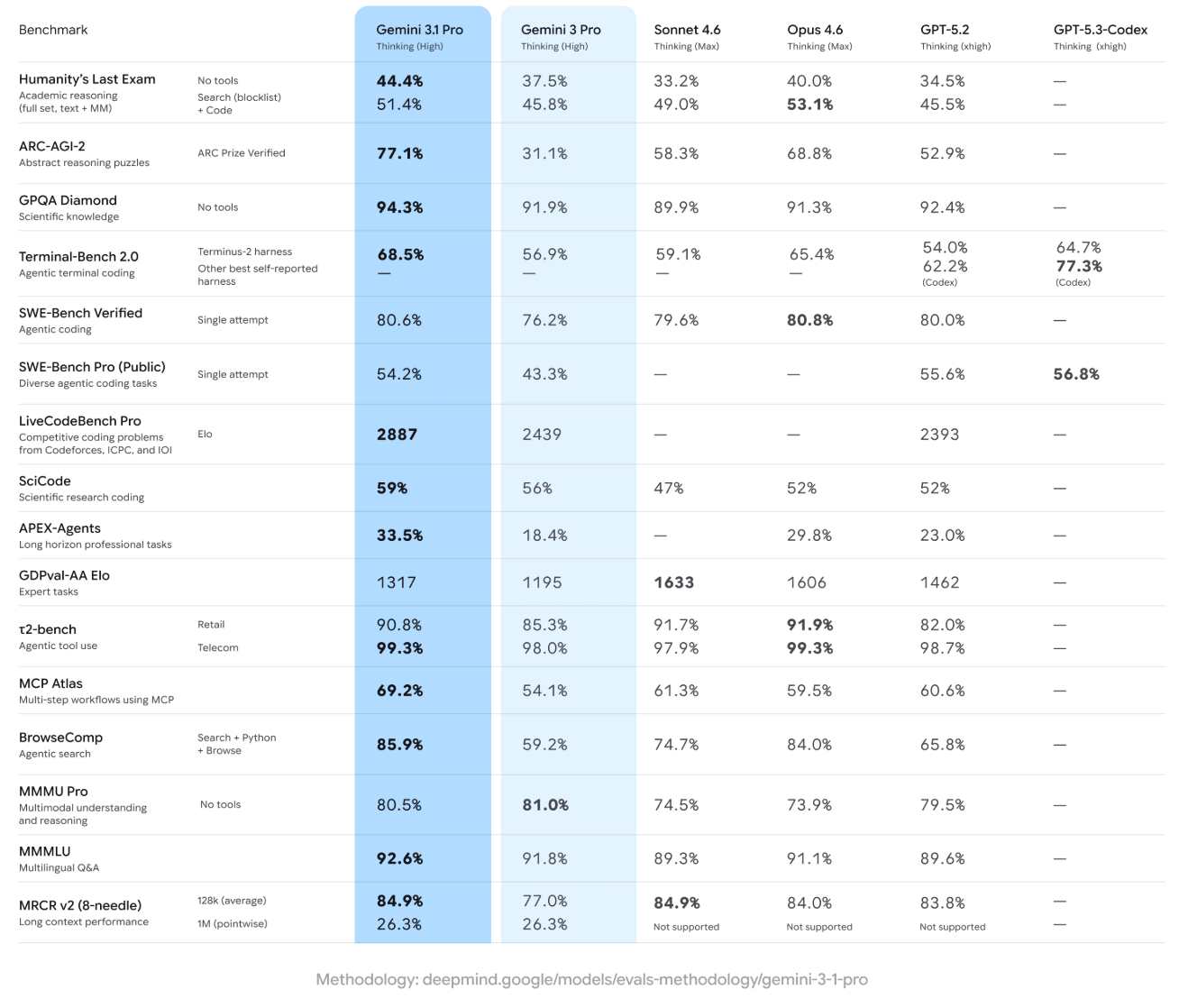
Allerdings führt 3.1 Pro nicht überall: Beim multimodalen MMMU Pro liegt der Vorgänger Gemini 3 Pro mit 81,0 Prozent knapp vor den 80,5 Prozent des neuen Modells. Und bei Humanity's Last Exam mit Werkzeugunterstützung erzielt Anthropics Opus 4.6 mit 53,1 Prozent den Bestwert. Ein häufiger Kritikpunkt an Googles aktuellen Modellen ist, dass sie Werkzeuge nicht so effizient einsetzen wie OpenAIs oder Anthropics Modelle.
Wie üblich gilt, dass Benchmarks nur begrenzte Aussagekraft über tatsächliche Leistung haben, insbesondere bei größtenteils eher inkrementellen Verbesserungen wie dem 3.0-auf-3.1-Update. Am besten testet man diese neuen Modelle mit den eigenen Prompts, im Optimalfall solchen, bei denen man eine klare Erwartung an den Output hat und diesen von früheren Modellen kennt. So kann man leicht eine Verbesserung feststellen.
Laut Google soll 3.1 Pro fortgeschrittenes Reasoning nutzen, um die Lücke zwischen komplexen APIs und nutzerfreundlichem Design zu schließen. Als konkretes Beispiel nennt Google ein Live-Aerospace-Dashboard: Das Modell habe eigenständig einen öffentlichen Telemetrie-Stream konfiguriert, um die Umlaufbahn der Internationalen Raumstation zu visualisieren.
Ein weiteres Anwendungsbeispiel ist die Fähigkeit, direkt aus Textprompts animierte SVGs zu generieren, die auf Websites eingebettet werden können, oder direkt die Erstellung besagter Websites; eben Aufgaben, die in Code gelöst werden.
Breite Verfügbarkeit und gestaffelte Preise
Google rollt 3.1 Pro parallel über mehrere Plattformen aus. Entwickler erhalten Zugang über die Gemini-API in Google AI Studio, die Gemini-CLI, die agentische Entwicklungsplattform Google Antigravity sowie Android Studio. Unternehmen können das Modell über Vertex AI und Gemini Enterprise nutzen. Endnutzer erhalten Zugang über die Gemini-App und NotebookLM, wobei letzteres exklusiv Pro- und Ultra-Abonnenten vorbehalten ist.
Die API-Preise staffeln sich nach Prompt-Länge und entsprechen jenen von Gemini 3 Pro. Im Vergleich zu Anthropics Opus-Modellen ist Gemini deutlich günstiger.
| Kategorie | Bis 200.000 Token | Über 200.000 Token |
|---|---|---|
| Input | 2,00 USD / 1M Token | 4,00 USD / 1M Token |
| Output | 12,00 USD / 1M Token | 18,00 USD / 1M Token |
| Caching | 0,20 USD / 1M Token | 0,40 USD / 1M Token |
| Cache-Speicher | 4,50 USD / 1M Token pro Stunde | 4,50 USD / 1M Token pro Stunde |
| Suchfunktion | 5.000 Prompts/Monat kostenlos, danach 14,00 USD / 1.000 Anfragen |
Das Modell befindet sich allerdings noch im Preview-Status. Google will auf Basis von Nutzerfeedback weitere Verbesserungen vornehmen, insbesondere bei "ambitionierten agentischen Workflows", bevor eine allgemeine Verfügbarkeit folgt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren