Googles "Cappy" macht große Sprachmodelle schlauer und effizienter

Google Research hat ein neues Verfahren namens Cappy entwickelt, um die Leistung und Effizienz von Large Language Models (LLMs) zu verbessern. Der leichtgewichtige, vortrainierte Scorer mit nur 360 Millionen Parametern ermöglicht die Anpassung von LLMs an spezifische Aufgaben ohne Feintuning.
Cappy ist eine Art Bewertungssystem, das mit vergleichsweise geringem Rechenaufwand die Qualität der von LLMs generierten Antworten bewertet und so deren Leistung steigern kann, wie die Google-Ingenieure Yun Zhu und Lijuan Liu in einem Blogbeitrag erläutern.
Das neue Verfahren ermöglicht es, LLMs an spezifische Aufgaben anzupassen, ohne dass eine Feinabstimmung der Modellparameter erforderlich ist. Das spart laut Google Speicher- und Rechenkapazität.
Cappy arbeitet als eine Art Schiedsrichter: Es bewertet, wie gut die Antworten eines LLMs zu einer bestimmten Fragestellung passen. Dazu vergibt Cappy Werte zwischen 0 und 1. Je höher der Wert, desto besser die Antwort.
Stellt ein Nutzer etwa die Frage "Welche Auswirkungen hatte die Industrielle Revolution auf die Gesellschaft?" und das LLM generiert verschiedene Ausgaben, so kann Cappy die Antwort, die die wichtigsten Aspekte wie Urbanisierung, Entstehung der Arbeiterklasse und soziale Umwälzungen abdeckt, besonders hervorheben und an den Nutzer ausgeben.
Weniger relevante Antworten mit niedriger Punktzahl werden ausgeblendet. Auf diese Weise stellt Cappy sicher, dass das LLM möglichst genaue, relevante und qualitativ hochwertige Antworten liefert.
Cappy arbeitet entweder eigenständig in Klassifikationsaufgaben oder als Hilfskomponente in Multi-Task LLMs, um deren Leistung zu steigern.
Schlanker "Scorer" optimiert LLM-Leistung
Um diese Bewertungen vornehmen zu können, wird Cappy zunächst mit einer großen Anzahl von Frage-Antwort-Paaren trainiert. Dabei lernt das System, gute von schlechten Antworten zu unterscheiden. Als Grundlage für diesen Lernprozess dient das bestehende Sprachmodell RoBERTa.
Cappy arbeitet auch mit LLMs, die nur über Schnittstellen angesprochen werden können. Im Gegensatz zu In-Context-Learning-Ansätzen, bei denen die Informationen direkt im Prompt bereitgestellt werden, ist Cappy nicht durch die Eingabelänge beschränkt und kann beliebig viele Trainingsbeispiele einbeziehen.
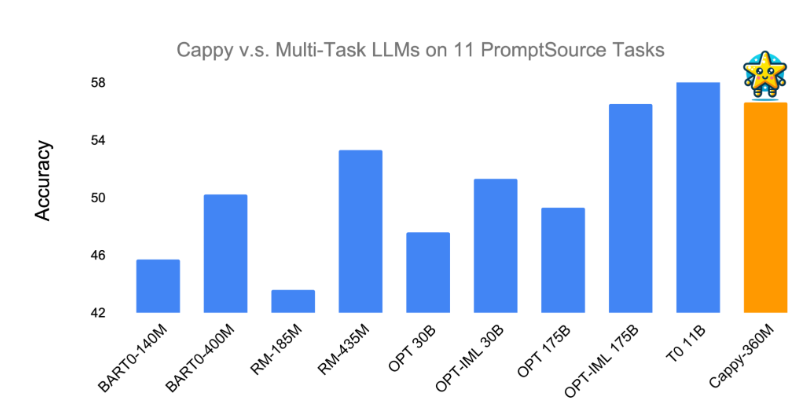
In Tests hat Cappy laut Google gezeigt, dass es die Leistung von Multi-Task LLMs verbessern kann. Bei elf Klassifikationsaufgaben aus PromptSource übertraf Cappy Metas Modelle OPT-175B und OPT-IML-30B und erreichte die Genauigkeit der besten existierenden Multi-Task LLMs (T0-11B und OPT-IML-175B).
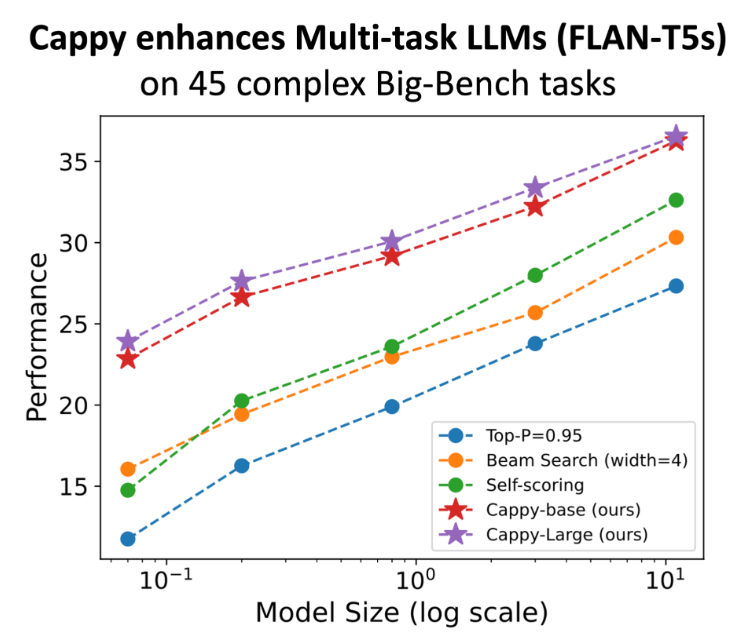
Bei 45 komplexen Generierungsaufgaben aus der BIG Benchmark, die als Herausforderung für viele LLMs gelten, konnte Cappy die Leistung der FLAN-T5 Modelle deutlich verbessern. Die Kombination aus Cappy und FLAN-T5 lieferte durchweg bessere Ergebnisse als das Standardverfahren, bei dem das Sprachmodell seine Antworten selbst bewertet.
Die Google-Forscher sehen in Cappy einen vielversprechenden Ansatz, um die Leistungsfähigkeit und Effizienz von KI-Sprachmodellen zu verbessern. Das Verfahren könnte es ermöglichen, LLMs schneller und mit weniger Aufwand für spezifische Anwendungen zu optimieren.
Dadurch könnten KI-Systeme in Zukunft flexibler und breiter einsetzbar werden, ohne dass extrem rechenintensive Neukonfigurationen der Modelle erforderlich sind. Langfristig könnte Cappy so den Weg für eine neue Generation von KI-Anwendungen ebnen, die effizienter, flexibler und leistungsfähiger sind als bisherige Systeme.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.