Forschende testen GPT-3.5 mit Fragen des US Bar Exams. Sie prognostizieren, dass GPT-4 und vergleichbare Modelle die Prüfung zeitnah bestehen werden.
In den USA verlangen fast alle Gerichtsbarkeiten eine Prüfung zur Berufszulassung, bekannt als das US "Bar Exam". Mit Bestehen dieser Prüfung erlangen Jurist:innen die Zulassung in eine Anwaltskammer eines amerikanischen Bundesstaats.
In den meisten Fällen müssen Bewerber:innen davor mindestens sieben Jahre eine weiterführende Ausbildung beenden, davon drei Jahre an einer anerkannten juristischen Fakultät.
Die Vorbereitung des Examens nimmt Wochen bis Monate in Anspruch und etwa eine von fünf Personen fällt beim ersten Versuch durch. Forschende des Chicago Kent College of Law, der Bucerius Law School Hamburg und des Stanford Center for Legal Informatics (CodeX) haben jetzt untersucht, wie sich OpenAIs GPT-3.5-Modell, das auch als Grundlage von ChatGPT dient, im Bar Exam schlägt.
OpenAIs GPT-3.5 ist nicht auf Rechtstexte spezialisiert
OpenAIs GPT-3.5 und ChatGPT zeigen in verschiedenen Szenarien der Verarbeitung natürlicher Sprache beeindruckende Leistungen und überholen oft Modelle, die explizit für bestimmte Domänen trainiert wurden. Die Trainingsdaten für die GPT-Modelle sind nicht komplett bekannt, die Modelle hätten jedoch mit hoher Wahrscheinlichkeit Rechtstexte aus öffentlichen Quellen gesehen, schreibt das Forschungsteam.
Angesichts der komplexen Natur juristischer Sprache und des eher offenen Trainings von GPT-3.5 sei es eine offene Frage, ob GPT oder vergleichbare Modelle erfolgreich juristische Aufgaben bewerten könnten.
Das Team testet OpenAIs großes Sprachmodell daher mit einem mehrstufigen Multiple-Choice-Teil des Bar Exams, bekannt als Multistate Bar Examination (MBE). Für die Tests verwenden die Forschenden ausschließlich Zero-Shot-Prompts.
Das MBE ist Teil des kompletten Exams, umfasst etwa 200 Fragen und soll juristisches Wissen und Leseverständnis testen. Laut der Forschenden erfordern die fiktiven Szenarien eine überdurchschnittliche semantische und syntaktische Beherrschung der englischen Sprache.
Ein Beispiel sieht so aus:

Question: A man sued a railroad for personal injuries suffered when his car was struck by a train at an unguarded crossing. A major issue is whether the train sounded its whistle before arriving at the crossing. The railroad has offered the testimony of a resident who has lived near the crossing for 15 years. Although she was not present on the occasion in question, she will testify that, whenever she is home, the train always sounds its whistle before arriving at the crossing.
Is the resident’s testimony admissible?
(A) No, due to the resident’s lack of personal knowledge regarding the
incident in question.
(B) No, because habit evidence is limited to the conduct of persons,
not businesses.
(C) Yes, as evidence of a routine practice.
(D) Yes, as a summary of her present sense impressions.
GPT-3.5 fällt durch, doch GPT-4 könnte das Bar Exam knacken
Für den Test nutzte das Team Vorbereitungsmaterial der National Conference of Bar Examiners (NCBE), der Organisation, die den Großteil der Bar Exams erstellt. GPT-3.5 konnte mit unterschiedlichen Prompts korrekte Antworten auf die Fragen geben, am erfolgreichsten war jedoch ein Prompt, der das Modell aufforderte, die Top-3 Antworten zu ordnen.
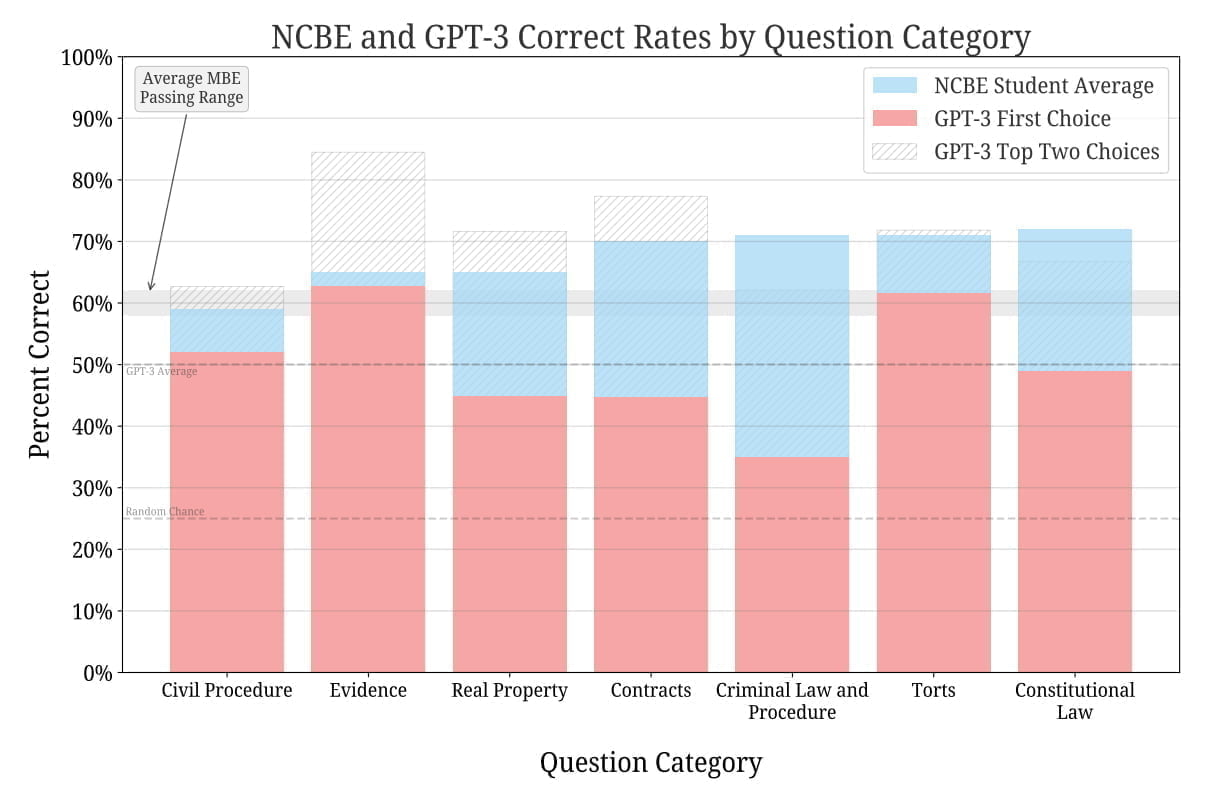
Im Schnitt liegt GPT-3.5 etwa 17 Prozent hinter menschlichen Teilnehmenden, die Unterschiede reichen jedoch von wenigen Prozenten bis zu 36 Prozent in der Kategorie Strafrecht. In der Kategorie Beweise schafft es GPT-3.5 über die durchschnittlich notwendigen 60 Prozent.
Mit der Top-3-Methode findet sich dagegen die richtige Antwort in fast allen Kategorien vielfach unter den ersten zwei Antworten. Laut des Teams überschreitet das Modell dabei deutlich die Baseline Zufall von 50 Prozent.
Bei allen Prompts und Hyperparametern übertraf GPT-3.5 die Basisrate des Zufalls deutlich. Ohne jegliche Feinabstimmung erreicht es derzeit eine Bestehensrate in zwei Kategorien des Bar Exams und erreicht in einer Kategorie die gleiche Rate wie menschliche Testteilnehmer. Die Rangfolge der möglichen Antworten korreliert stark mit der Korrektheit und übertrifft die Zufallsrate, was ein allgemeines Verständnis des juristischen Bereichs durch das Modell bestätigt.
Aus dem Paper
GPT-3.5 übertreffe deutlich die erwartete Leistung, schreiben die Autoren: "Trotz Tausender von Stunden, die wir in den vergangenen zwei Jahrzehnten mit ähnlichen Aufgaben verbracht haben, haben wir nicht erwartet, dass GPT-3.5 eine derartige Leistungsfähigkeit in einem Zero-Shot-Szenario mit minimalem Modellierungs- und Optimierungsaufwand zeigen würde."
Die Geschichte der Entwicklung großer Sprachmodelle suggeriere daher stark, dass solche Modelle den getesteten Teil des Bar Exam bestehen könnten. Aufgrund von Erfahrungsberichten von GPT-4 und der Bloom-Modellfamilie von LAION halten die Forschenden dieses Szenario innerhalb der nächsten 18 Monate für realistisch.
Im nächsten Schritt will das Team die Abschnitte Essay (MEE) und situative Leistung (MPT) des Bar Exams testen.
Google Brain zeigte kürzlich eine mit medizinischen Daten optimierte Version des großen Sprachmodells PaLM, das Laien-Fragen zu Medizinthemen auf Augenhöhe mit menschlichen Expert:innen beantworten kann. Es übertrifft die Leistung des nativen PaLM-Sprachmodells deutlich.