OpenAI veröffentlicht SimpleQA-Benchmark für Faktentreue-Tests von KI-Modellen
Update –
- Korrektur der Methodik ergänzt.
Update vom 01. November 2024:
In diesem Artikel habe ich einen wichtigen methodischen Aspekt der OpenAI-Studie falsch interpretiert.
Die im Artikel genannten Prozentzahlen der korrekten Antworten sind nicht repräsentativ für die allgemeine Leistung der KI-Modelle. Der SimpleQA-Benchmark wurde speziell so konstruiert, dass nur Fragen aufgenommen wurden, bei denen mindestens eines der bei der Datensatz-Erstellung genutzten Modelle eine falsche Antwort gab. Das war Teil der Methodik, um einen herausfordernden Benchmark zu erstellen.
Die niedrigen Prozentwerte sind also eine direkte Folge dieser Auswahlmethode und können nicht als absolute Leistungsindikatoren der Modelle verstanden werden. Ich bedauere diese irreführende Darstellung. Der Artikel wurde entsprechend aktualisiert.
Ursprünglicher Artikel vom 30. Oktober 2024:
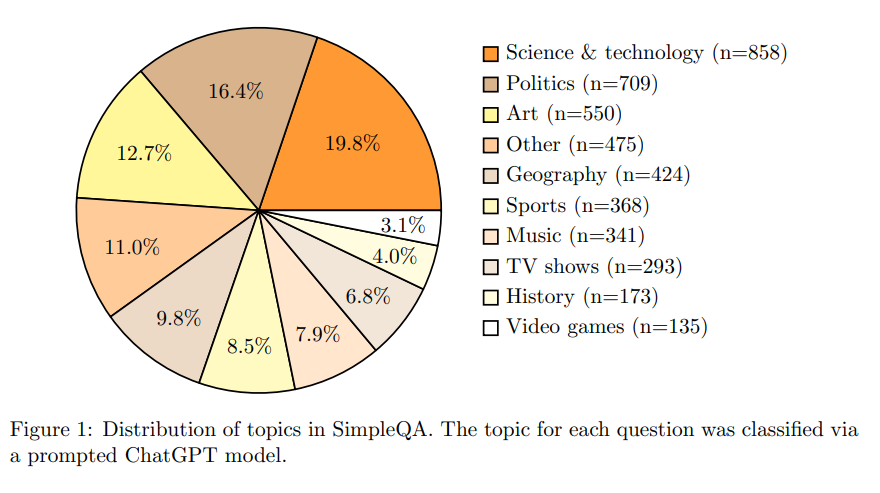
Der SimpleQA-Test umfasst 4.326 Fragen aus verschiedenen Bereichen wie Wissenschaft, Politik und Kunst. Jede Frage wurde so konzipiert, dass es nur eine eindeutig richtige Antwort gibt. Die Korrektheit der Antworten wurde von zwei unabhängigen Prüfern verifiziert.
Die niedrigen Prozentwerte der korrekten Antworten müssen im Kontext der speziellen Methodik des SimpleQA-Tests betrachtet werden: Die Forscher nahmen nur solche Fragen in den Benchmark auf, bei denen mindestens eines der getesteten Modelle eine falsche Antwort gab.
Laut der OpenAI-Studie war dies ein bewusstes Auswahlkriterium, um einen anspruchsvollen Test zu entwickeln. Die genannten Prozentzahlen spiegeln also nicht die allgemeine Leistungsfähigkeit der Modelle wider, sondern ihre Performance bei besonders schwierigen Fragen.
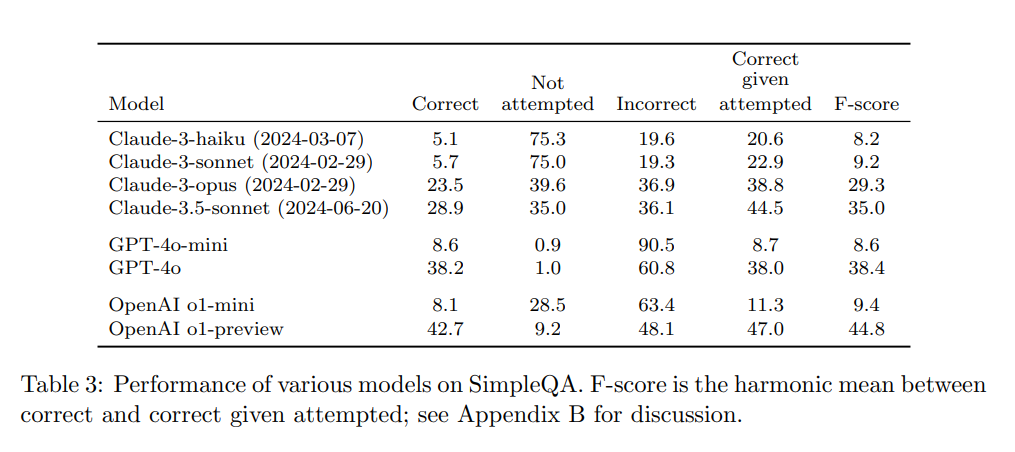
Der Studie zufolge erreicht das beste getestete Modell, OpenAIs o1-preview, nur eine Trefferquote von 42,7 Prozent. GPT-4o kommt auf 38,2 Prozent richtige Antworten, während das kleinere GPT-4o-mini nur 8,6 Prozent der Fragen richtig beantwortet.
Noch schlechter schneiden die Modelle Claude von Anthropic ab: Das beste Modell Claude-3.5-sonnet erreicht 28,9 Prozent richtige und 36,1 Prozent falsche Antworten. Allerdings verweigern insbesondere die kleineren Claude-Modelle im Zweifelsfall häufiger die Antwort - ein erwünschtes Verhalten, bei dem die Modelle zugeben, dass sie nicht über das Wissen verfügen.
Wichtig: Der Test bezieht sich auf das Abrufen von Wissen, das die Modelle während des Trainings erworben haben. Es bezieht sich nicht auf die generelle Fähigkeit der Modelle, in bestimmten Szenarien richtige Antworten zu geben, etwa wenn Quellen und Kontext bereitgestellt, aus dem Internet geladen oder in einer Datenbank zur Verfügung gestellt werden.
KI-Modelle überschätzen sich
Die Studie zeigt auch, dass KI-Modelle ihre eigenen Fähigkeiten deutlich überschätzen. Auf die Frage nach ihrem Selbstvertrauen, also dem Vertrauen in die eigene Antwort, geben sie systematisch zu hohe Werte an. Größere Modelle sind zwar besser kalibriert als kleinere, aber immer noch weit von einer realistischen Selbsteinschätzung entfernt. Das deckt sich mit der generellen Kritik an Sprachmodellen, dass sie sehr überzeugend völlig falsche Antworten geben.
Die Forscher testeten dies, indem sie die Modelle hundertmal dieselbe Frage beantworten ließen. Je öfter ein Modell dieselbe Antwort gab, desto wahrscheinlicher war sie richtig - aber auch hier blieben die Trefferquoten unter den Erwartungswerten.

OpenAI hat den SimpleQA-Test öffentlich zugänglich gemacht. Damit will das Unternehmen nach eigenen Angaben die Entwicklung von vertrauenswürdigeren und zuverlässigeren Sprachmodellen fördern.
Die Ergebnisse zeigen, so die Forscher, dass es bei der sachlichen Korrektheit von KI-Antworten noch erheblichen Verbesserungsbedarf gibt. Ob die Fähigkeit, kurze Antworten mit Fakten zu geben, mit der Fähigkeit korreliert, ausführliche Antworten mit vielen Fakten zu schreiben, bleibe eine offene Forschungsfrage.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.