GPT-5.2 dominiert OpenAIs neuen Wissenschafts-Test, scheitert aber an komplexen Forschungsaufgaben
OpenAI stellt mit FrontierScience einen neuen Benchmark vor, der KI-Modelle auf Olympiade- und Forschungsniveau testet. Das hauseigene GPT-5.2 schneidet dabei am besten ab, doch die Aufgaben offenbaren auch die Grenzen aktueller Systeme.
Bestehende Wissenschafts-Benchmarks sind laut OpenAI nahezu ausgereizt. Als das Unternehmen im November 2023 GPQA vorstellte, einen "Google-sicheren" Multiple-Choice-Test für Wissenschaftsfragen auf PhD-Niveau, erreichte GPT-4 noch 39 Prozent. Zwei Jahre später liegt GPT-5.2 bei 92 Prozent. Diese rasante Entwicklung macht neue, anspruchsvollere Evaluierungsmethoden notwendig, so das Unternehmen.
Mit FrontierScience legt OpenAI jetzt einen Benchmark vor, der aus zwei Teilen besteht: einem Olympiad-Set mit Aufgaben auf dem Niveau internationaler Wissenschaftsolympiaden und einem Research-Set mit offenen Forschungsteilproblemen auf PhD-Niveau. Das veröffentlichte Gold-Set umfasst 160 Fragen zu Physik, Chemie und Biologie, gefiltert aus über 700 ursprünglich erstellten Aufgaben. Die übrigen Fragen bleiben zurückgehalten, um mögliche Kontamination zu überwachen.
Medaillengewinner und Professoren als Aufgabensteller
Die 100 Olympiad-Fragen wurden von 42 ehemaligen internationalen Medaillengewinnern oder Nationaltrainern entwickelt, die zusammen 108 Olympiade-Medaillen gewonnen haben. Die Aufgaben orientieren sich an der Internationalen Physik-Olympiade, der Internationalen Chemie-Olympiade und der Internationalen Biologie-Olympiade. Alle Antworten lassen sich als einzelne Zahl, algebraischer Ausdruck oder eindeutiger Begriff verifizieren.
Die 60 Research-Fragen stammen von 45 Wissenschaftlern, deren Expertise von Quantenmechanik über Molekularbiologie bis zur Photochemie reicht. Jede Aufgabe soll laut OpenAI mindestens drei bis fünf Stunden zur Lösung benötigen. Statt einer einzelnen korrekten Antwort wird jede Research-Aufgabe anhand einer zehn Punkte umfassenden Rubrik bewertet. Die Bewertung erfolgt automatisiert durch GPT-5 bei hoher Reasoning-Intensität.
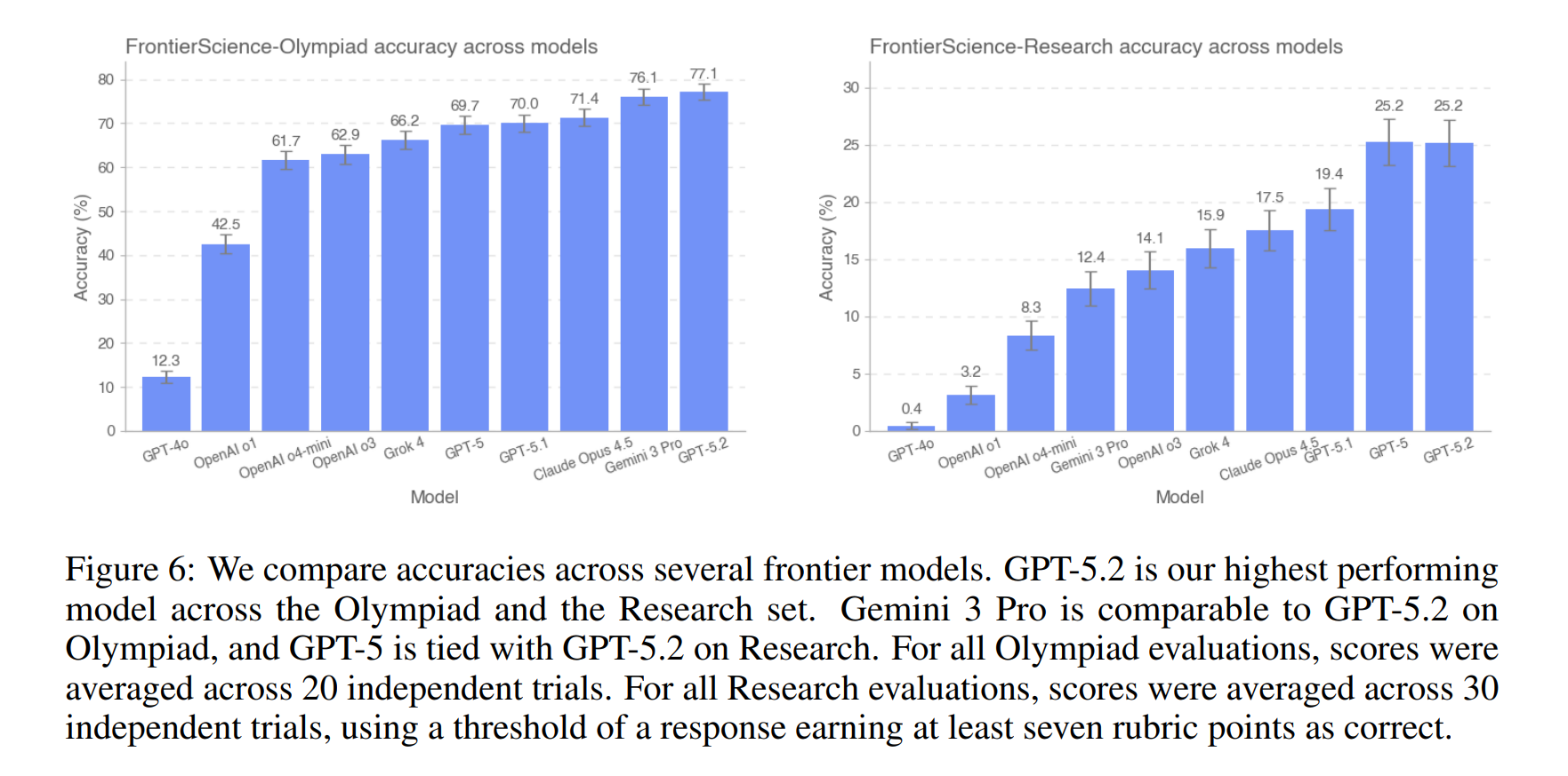
GPT-5.2 führt, doch Research bleibt schwierig
Alle Reasoning-Modelle wurden bei "high" Reasoning-Intensität getestet, GPT-5.2 zusätzlich bei "xhigh" – und ohne Browsing-Funktion. GPT-5.2 erreicht 77 Prozent auf dem Olympiad-Set und 25 Prozent auf dem Research-Set. Gemini 3 Pro liegt bei Olympiad mit 76 Prozent knapp dahinter. Bei Research teilen sich GPT-5.2 und GPT-5 den ersten Platz – "überraschenderweise" (OpenAI) übertrifft GPT-5 damit das neuere GPT-5.1, das nur 19 Prozent erreicht.
Claude Opus 4.5 kommt auf 71 Prozent bei Olympiad und 18 Prozent bei Research. Grok 4 erreicht 66,2 beziehungsweise 16 Prozent. Das ältere GPT-4o schneidet mit 12 Prozent bei Olympiad und unter einem Prozent bei Research deutlich schlechter ab. Ein großer Sprung kam mit OpenAIs erstem Reasoning-Modell o1 im vergangenen September.
Mehr Rechenzeit, bessere Ergebnisse
Die Leistung hängt auch von der eingesetzten Rechenzeit ab. GPT-5.2 verbessert sich von 67,5 Prozent bei niedriger Reasoning-Intensität auf 77 Prozent bei höchster Intensität im Olympiad-Set. Bei Research steigt die Leistung von 18 auf 25 Prozent. OpenAIs o3-Modell zeigt bei Research einen gegenläufigen Trend: Bei hoher Reasoning-Intensität schneidet es marginal schlechter ab als bei mittlerer. Einen Grund nennt das Unternehmen nicht, bezeichnet diese Erkenntnis aber auch hier als "überraschend".
Laut OpenAI zeigen die Ergebnisse substanziellen Fortschritt bei Expertenfragen, lassen aber insbesondere bei offenen Forschungsaufgaben noch Raum für Verbesserungen. Nach Fachgebiet aufgeschlüsselt schneiden die Modelle bei beiden Sets in Chemie am besten ab. Typische Fehlerquellen sind Logikfehler, Verständnisprobleme bei Nischenkonzepten, Rechenfehler und faktische Ungenauigkeiten.
Sprachmodelle werden besser mit Zahlen
In den vergangenen Monaten gab es einige Berichte, dass KI-Systeme Forschungsarbeit spürbar beschleunigen können. OpenAI präsentierte mit "GPT-5 Science Acceleration" eine Sammlung von Fallstudien, in denen Mathematiker:innen sich bei Beweisen helfen ließen, Physiker:innen bei Symmetrieanalysen und Immunolog:innen bei Hypothesen und Experimentplänen.
Der Physiker Steve Hsu veröffentlichte ein Paper, dessen zentrale Idee von GPT-5 stammte. Der Autor sieht darin den Beginn "hybrider Mensch-KI-Kollaborationen", die in Mathematik, Physik und anderen formal geprägten Wissenschaften zum Standard werden könnten. Das Ergebnis wird allerdings auch kritisiert.
OpenAI selbst hat angekündigt, bis 2028 autonome Forschungsagenten entwickeln zu wollen, die wissenschaftliche Prozesse fundamental beschleunigen sollen. Google Deepmind und OpenAI haben 2025 zudem gezeigt, dass KI-Modelle mit fortgeschrittenem Reasoning und Reinforcement Learning zunehmend in der Lage sind, komplexe mathematische Probleme über Stunden hinweg autonom zu lösen, ohne symbolische Hilfsmittel. Auch der Mathematiker Terence Tao berichtete, dass ihm KI bei der Lösung von Aufgaben half.
Gleichzeitig warnen Experten vor Risiken: Der unkritische Einsatz von KI in der Wissenschaft könne zu großen Mengen an inhaltlich fehlerhaften, aber schwer erkennbaren Ergebnissen führen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.