Höherer Token-Verbrauch kann die Effizienz offener Sprachmodelle reduzieren
Sogenannte "Reasoning-Modelle" generieren deutlich mehr Wörter (Token), bevor sie antworten. Offene KI-Modelle benötigen dabei mitunter drei- bis viermal mehr Token als geschlossene Modelle wie Grok-4 oder OpenAI, zeigt eine Analyse von Nous Research. Besonders bei einfachen Wissensfragen produzieren offene Modelle unnötige Gedankenschritte, was trotz niedrigerer Tokenpreise zu höheren Gesamtkosten führen kann.
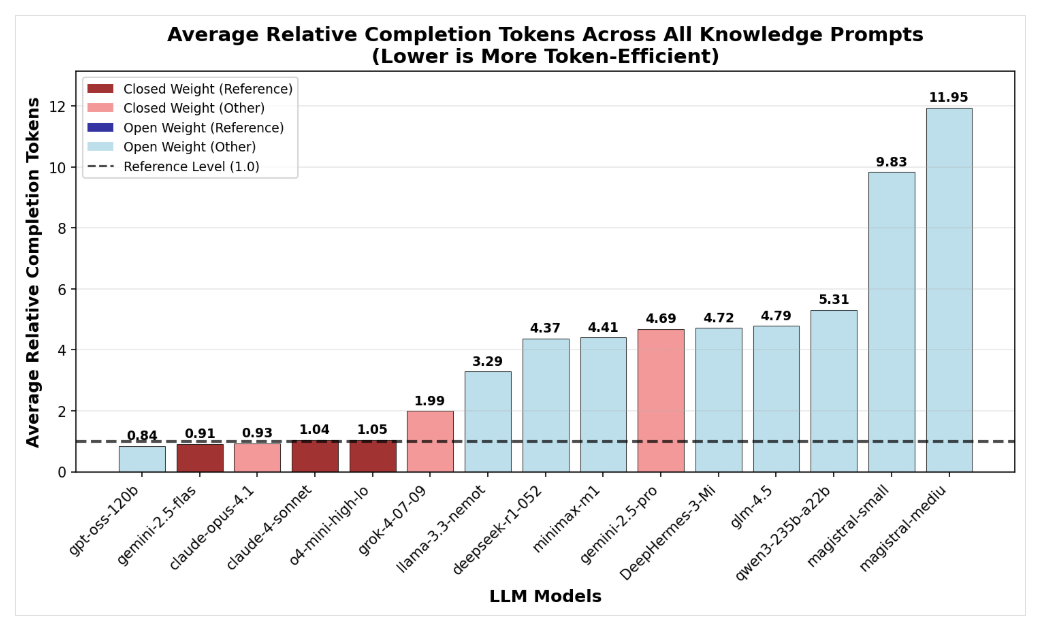
OpenAIs gpt-oss-120b zeige jedoch, dass auch Open-Source-Modelle mit sehr kurzen Denkpfaden effizient arbeiten können, insbesondere bei Mathematikaufgaben. Mistrals Magistral-Modelle hingegen fallen durch hohen Tokenverbrauch auf. Die Token-Effizienz hängt stark vom Aufgabentyp ab.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.