Hugging Face veröffentlicht kleines Sprachmodell, das Qwen und Llama meistens schlägt
Ein Forschungsteam von Hugging Face hat mit SmolLM2 ein neues Sprachmodell vorgestellt. Allerdings setzt es keine neuen Maßstäbe, sondern gehört in gewisser Weise zum Pflichtprogramm.
Der Schlüssel zum Erfolg von SmolLM2 liegt laut Hugging Face in der geschickten Kombination verschiedener Quellen für den 11 Billionen Token großen Datensatz und einem stufenweisen Trainingsprozess.
In der ersten Phase verwendeten die Forscher:innen eine ausgewogene Mischung aus informativen und abwechslungsreichen Webtexten sowie Programmierbeispielen. In späteren Phasen fügten sie spezialisierte Datensätze mit hochwertigen Mathematik- und Programmieraufgaben hinzu.
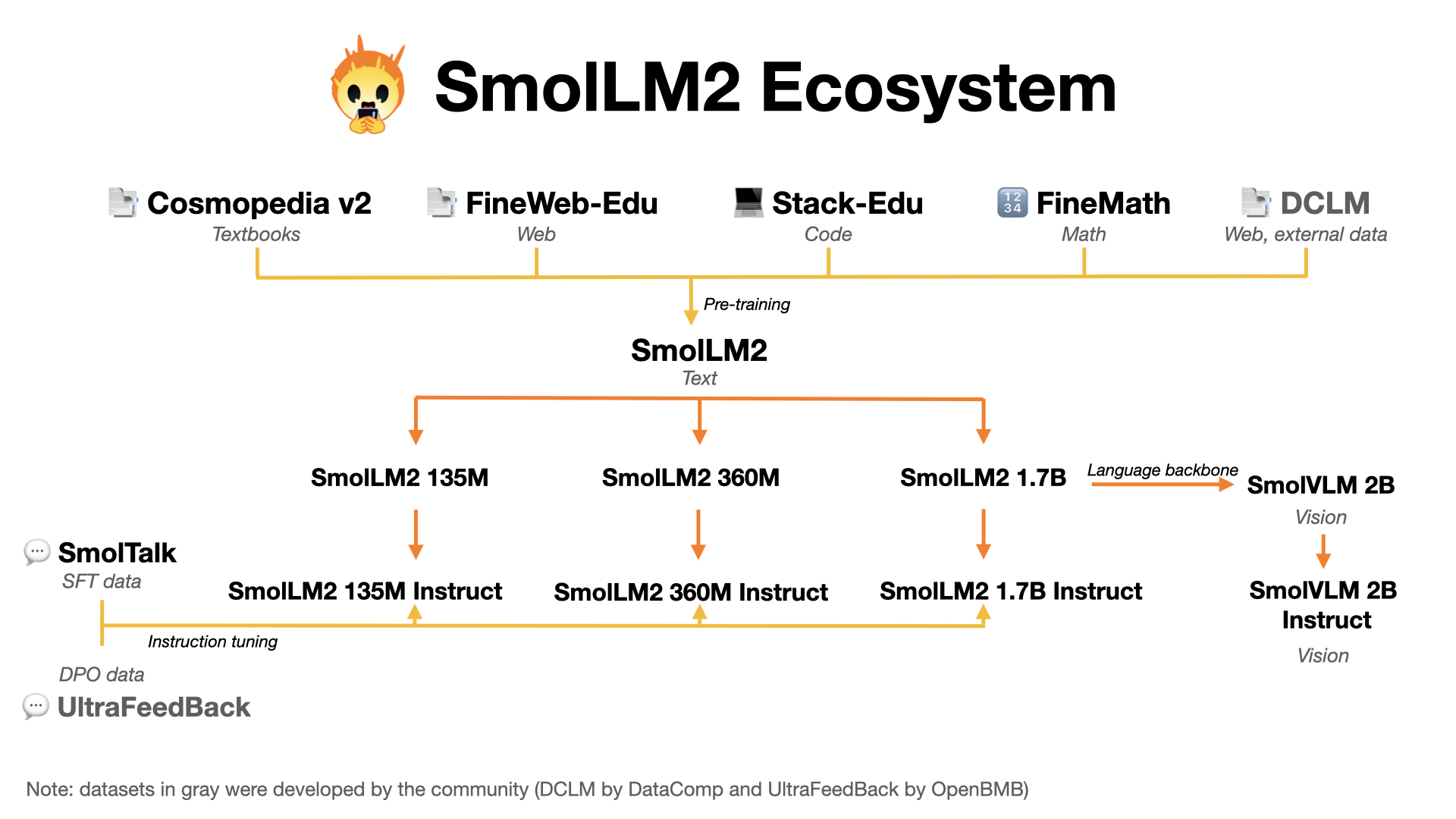
Nach jeder Trainingsphase evaluierten die Wissenschaftler die Leistung des Modells und identifizierten Schwachstellen. Anschließend passten sie die Zusammensetzung der Trainingsdaten an, um diese Lücken zu schließen.
Für diesen Zweck entwickelten sie auch eigene Datensätze: FineMath für anspruchsvolle Mathematikaufgaben, Stack-Edu für gut dokumentierten Programmcode und SmolTalk für Konversation und verwandte Aufgaben.
Spitzenwerte in manchen Benchmarks
Nach dem Vortraining unterzogen die Forschenden SmolLM2 noch weiteren Optimierungsschritten. Durch Finetuning anhand von Anleitungen und Beispielen verbesserten sie die Fähigkeit des Modells, Aufgaben präzise zu verstehen und zu lösen. Mithilfe von Reinforcement Learning trainierten sie es darauf, Antworten zu generieren, die den Präferenzen der Nutzer:innen optimal entsprechen.
In Benchmarks zu Wissens- und Verständnisaufgaben übertrifft SmolLM2 ähnlich große Konkurrenzmodelle wie Qwen2.5-1.5B und Llama3.2-1B – in vielen, aber nicht in allen Bereichen.
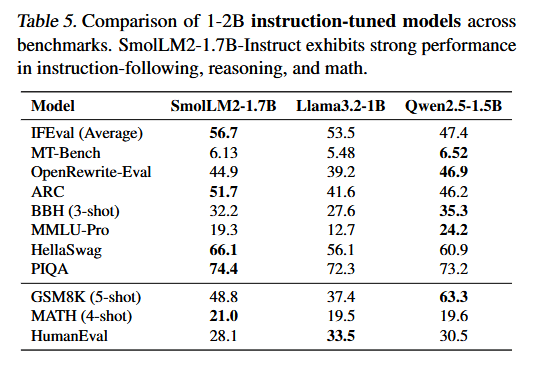
Zusätzlich zu SmolLM2 mit 1,7 Milliarden Parametern trainierte das Forschungsteam zwei kleinere Varianten mit 360 und 135 Millionen Parametern, die in ihrer Größenklasse ebenfalls ordentliche Ergebnisse erzielen.
Hugging Face hat sich mit seinem riesigen Archiv für Modellgewichte als unersetzlicher Bestandteil der quelloffenen KI-Entwicklung etabliert. Doch das Start-up will nicht nur Daten für andere aufbewahren, sondern die Forschung aktiv vorantreiben.
SmolLM2 ist Pflicht, aber keine Kür
Kürzlich hat das US-Unternehmen, das unter anderem von Google unterstützt wird, eine Bibliothek für KI-Agenten und eine Open-Source-Alternative zu OpenAIs Deep Research veröffentlicht.
SmolLM2 nutzt mit dem hochwertigen Datenmix und dem mehrstufigen Trainingsverfahren bewährte Bausteine für effiziente Sprachmodelle. Es kann ähnlichen Modellen von Meta und Qwen zwar das Wasser reichen, setzt aber nicht völlig neue Maßstäbe. Mit dieser Größenordnung wäre es in der realen Anwendung wahrscheinlich am ehesten für kleinere Aufgaben auf leistungsschwachen Geräten wie Smartphones interessant.
Nichtsdestotrotz gehörte die Entwicklung gewissermaßen zum Pflichtprogramm für einen wichtigen KI-Player wie Hugging Face. Immerhin: Im Gegensatz zu Meta und Qwen, die lediglich die Modellgewichte freigegeben haben, fährt Hugging Face eine konsequente Open-Source-Strategie und stellt anderen auch die genutzten Trainingsdaten zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.