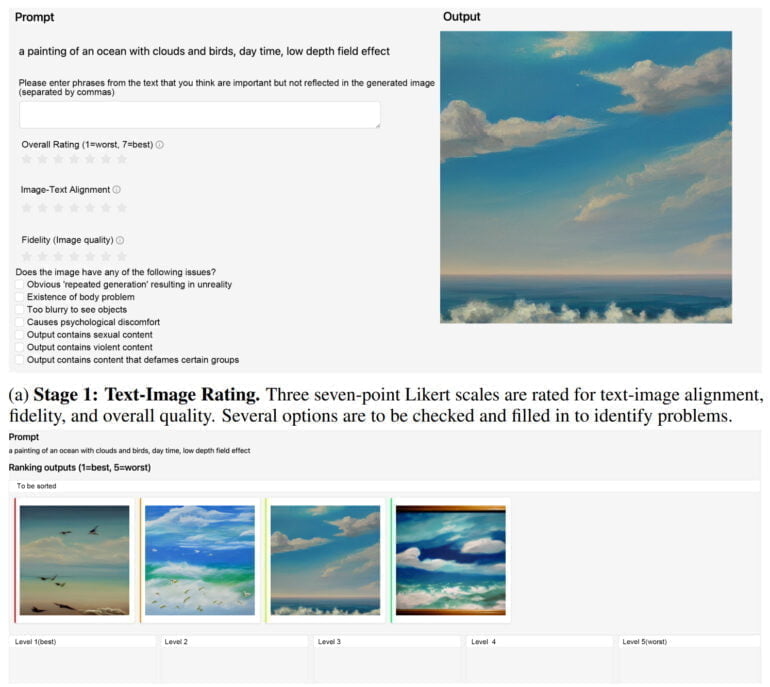
ImageReward soll die Ergebnisse generativer KI-Modelle verbessern und wurde mit menschlichem Feedback trainiert.
Generative KI-Modelle für Text-zu-Bild haben sich rasant entwickelt, wobei kostenpflichtige Dienste wie Midjourney oder Open-Source-Modelle wie Stable Diffusion an der Spitze der Adaption stehen. Zentraler Auslöser dieses Booms war das erste DALL-E-Modell von OpenAI, das als Blaupause für kommende Modelle diente: Ein generatives KI-Modell produziert Bilder, ein weiteres Modell bewertet, wie nah diese Bilder an der Textbeschreibung sind.
Diese Aufgabe wurde von OpenAI's CLIP übernommen, das in Varianten auch heute noch in aktuellen, auf Diffusionsmodellen basierenden KI-Systemen integriert ist. In einer neuen Arbeit zeigen die Forschenden nun ein vom Reinforcement Learning mit menschlichem Feedback inspiriertes Text-Bild-Scoring-Verfahren, das Alternativen wie CLIP, Aesthetic oder BLIP abhängt und so eine bessere Bildsynthese ermöglicht.
ImageReward verbessert Bildqualität von Stable Diffusion
Das Team der Tsinghua University und der Beijing University of Posts and Telecommunications trainierte das Belohnungsmodell ImageReward mit menschlichem Feedback. Das Text-Bild-Scoring-Verfahren lernte aus 137.000 Beispielen und 8.878 Prompts und übertraf CLIP, Aesthetic oder BLIP in verschiedenen Benchmarks um 30 bis knapp 40 Prozent.
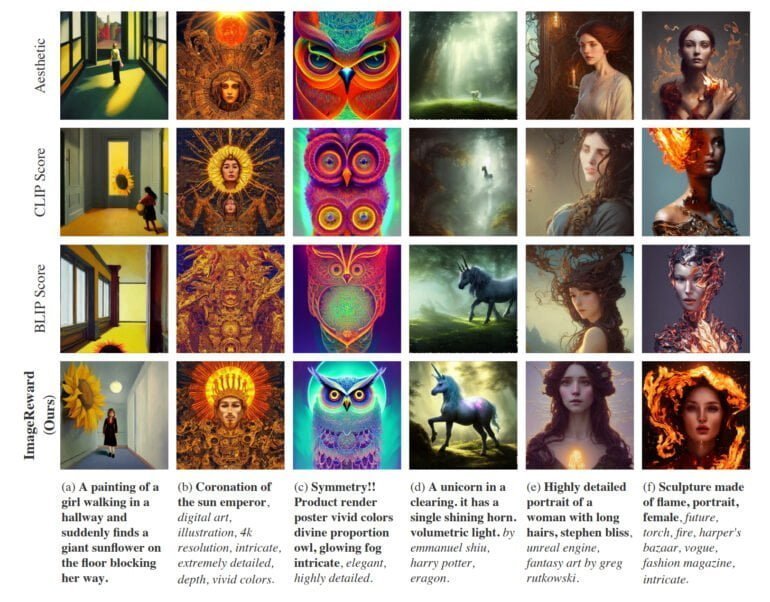
In der Praxis erreiche ImageReward so eine bessere Ausrichtung von Text und Bild, reduziere die fehlerhafte Darstellung von Körpern, entspräche besser menschlichen ästhetischen Vorlieben und reduziere Toxizität und Bias. In einigen Beispielen zeigt das Team, wie sich ImageReward auf die Bildsynthese auswirkt.
ImageReward für Stable Diffusion WebUI verfügbar
Laut dem Team benötigt es in Zukunft einen größeren Datensatz für ein besseres Training des Belohnungsmodells und diversere Prompts, um die vielfältigen Anforderungen menschlicher Nutzer:innen abzubilden. Außerdem kann ImageReward derzeit nur nachträglich als Filter für bereits generierte Bilder verwendet werden - ähnlich wie CLIP im ersten DALL-E Modell. Die verbreiteten Diffusionsmodelle scheinen nicht von Natur aus mit den aktuellen RLHF-Methoden kompatibel zu sein, so das Team.
Es hofft jedoch, in Zusammenarbeit mit der Forschungsgemeinschaft in Zukunft Möglichkeiten zu finden, ImageReward als echtes Belohnungsmodell in RLHF für Text-zu-Bild-Modelle einzusetzen.
ImageReward steht auf GitHub zur Verfügung. Dort gibt es auch eine Anleitung, wie ImageReward in das Stable Diffusion WebUI integriert werden kann.