In-Context-Learning von Sprachmodellen braucht sich vor Fine-Tuning nicht zu verstecken

Wissenschaftler der École Polytechnique Fédérale de Lausanne (EPFL) haben eine umfassende Analyse zum Vergleich von In-Context-Learning (ICL) und Instruction Fine-Tuning (IFT) bei der Anpassung großer Sprachmodelle (LLMs) durchgeführt.
Für ihre Untersuchung nutzten die Forscher den etablierten MT-Bench-Benchmark, der die Fähigkeit von Modellen zur Anweisungsbefolgung misst. Überraschenderweise zeigte die Studie, dass ICL und IFT bei der Verwendung weniger Trainingsbeispiele (bis zu 50) im ersten Durchgang des MT-Bench-Tests ähnliche Leistungen erbringen.
"Unsere Ergebnisse deuten darauf hin, dass ICL mit qualitativ hochwertigen Daten eine praktikable Alternative zu IFT sein kann, wenn nur eine begrenzte Anzahl von Demonstrationen zur Verfügung steht", erklären die Autoren der Studie.
Unterschiede bei komplexeren Aufgaben
Trotz der Ähnlichkeiten bei einfachen Aufgaben zeigten sich bei komplexeren Szenarien deutliche Unterschiede zwischen den beiden Methoden. Bei Konversationen mit mehreren Runden schnitt IFT signifikant besser ab als ICL.
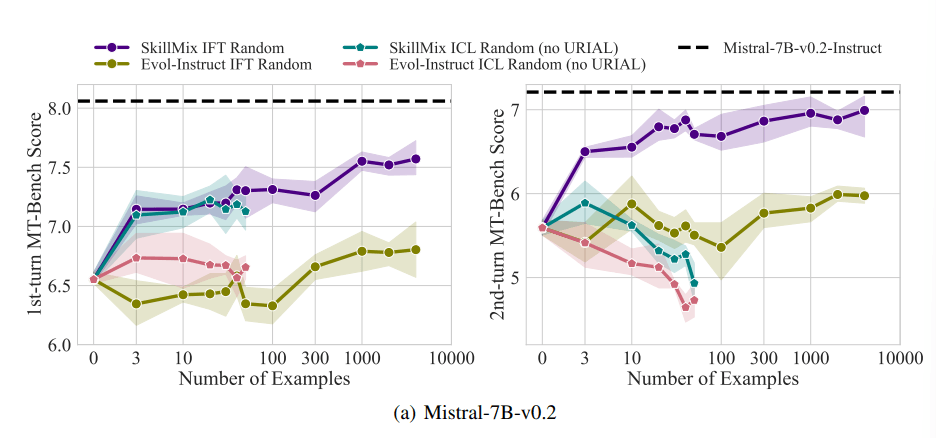
Die Forscher vermuten, dass dies daran liegt, dass ICL-Modelle zu stark an den Stil einzelner Beispiele angepasst werden und Schwierigkeiten haben, auf komplexere Gespräche zu reagieren.
Ein weiterer Aspekt der Studie war die Untersuchung der URIAL-Methode, die Basis-Sprachmodelle mit nur drei Beispielen und Regeln zur Anweisungsbefolgung trainiert. Obwohl URIAL gute Ergebnisse lieferte, blieb die Methode hinter Modellen zurück, die durch Instruction Fine-Tuning angepasst wurden.
Die EPFL-Forscher konnten die Leistung von URIAL an die von Instruct annähern, indem sie zusätzliche Beispiele wie eine Greedy-Suche für die In-Context-Alignment-Modelle auswählten. Das zeige, wie wichtig qualitativ hochwertige Trainingsdaten für beide Methoden sind.
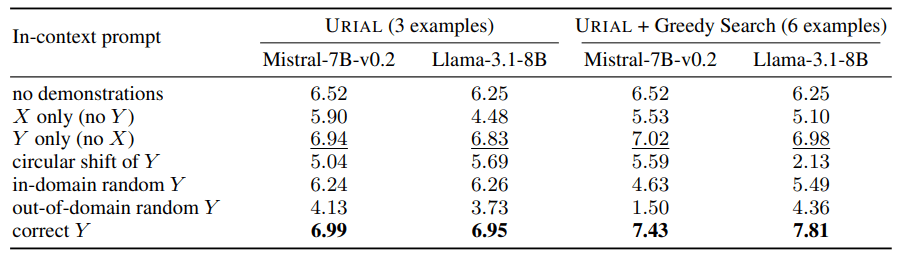
Ein weiteres Ergebnis der Studie war der große Einfluss der Dekodierungsparameter auf die Modellleistung. Diese Parameter, die bestimmen, wie das Modell Texte erzeugt, spielten sowohl bei Basis-LLMs als auch bei Modellen, die URIAL verwenden, eine entscheidende Rolle. Mit den richtigen Dekodierungsparametern können sogar Basismodelle bereits Instruktionen befolgen.
Implikationen für die Praxis
Die Ergebnisse zeigen, dass In-Context-Learning eine effektive Methode zur schnellen Anpassung von Sprachmodellen sein kann, insbesondere wenn nur wenige Trainingsbeispiele zur Verfügung stehen.
Allerdings bleibt Fine-Tuning die überlegene Methode, wenn es um die Generalisierung auf komplexere Aufgaben wie mehrstufige Konversationen geht. Zudem kann IFT bei größeren Datensätzen kontinuierlich bessere Ergebnisse erzielen, während ICL ab einer gewissen Anzahl von Beispielen stagniert.
Die Forscher betonen, dass die Wahl zwischen ICL und IFT von verschiedenen Faktoren abhängt, darunter die verfügbaren Ressourcen, die Datenmenge und die spezifischen Anforderungen der Anwendung. In jedem Fall unterstreicht die Studie die Bedeutung hochwertiger Trainingsdaten für beide Ansätze.
Die Studie mit dem Titel "Is In-Context Learning Sufficient for Instruction Following in LLMs?" wurde im Rahmen der NeurIPS 2024 vorgestellt. Der Code ist bei Github verfügbar.
ICL und IFT können natürlich auch kombiniert werden. Der Goldstandard könnte hier weiterhin sein, mit Beispielen im Prompt möglichst schnell eine hohe Qualität zu erreichen, die dann durch Feintuning weiter optimiert und stabilisiert wird.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.