Kann selbstüberwachtes Lernen die menschliche Sprachverarbeitung erklären? Eine neue Studie vergleicht den Wav2Vec-Algorithmus mit fMRT-Aufnahmen.
Selbstüberwacht trainierte KI-Modelle nähern sich menschlicher Leistungsfähigkeit an oder haben diese schon erreicht, etwa in der Objekterkennung, Übersetzung oder Spracherkennung. Mehrere Studien belegen außerdem, dass zumindest einzelne Repräsentationen dieser Algorithmen mit denen menschlicher Gehirne korrelieren.
Ein Beispiel: Die neuronale Aktivität mittlerer Schichten von GPT-Modellen lässt sich auf das Gehirn während des Konsums von Text oder gesprochener Sprache abbilden. Dabei können Aktivitäten aus einer tieferen Schicht des neuronalen Netzes in synthetischen fMRI-Bilder (Funktionelle Magnetresonanztomografie) verwandelt und mit echten Aufnahmen von Menschen verglichen werden.
In einer Arbeit zeigten Forschende von Meta, dass sie die Reaktionen des Gehirns auf Sprache anhand der Aktivierungen von GPT-2 als Reaktion auf dieselben Geschichten vorhersagen konnten.
"Je besser die Versuchspersonen eine Geschichte verstehen, desto besser sagt GPT-2 ihre Gehirnaktivität voraus", so Jean-Remi King, CNRS-Forscher an der Ecole Normale Supérieure und Forscher bei Meta AI.
GPT-Modelle können Spracherwerb nicht erklären
Modelle wie GPT-2 unterscheiden sich jedoch in mehreren Punkten deutlich vom Gehirn. So benötigen sie etwa extrem großen Datenmengen für das Training und setzen auf Text statt rohe Sensordaten. Um die 40 Gigabyte reinen Text, mit denen GPT-2 trainiert wurde, zu lesen, benötigten die meisten Menschen mehrere Leben.
Die Modelle sind daher nur bedingt geeignet, mehr über das menschliche Gehirn zu lernen - ein erklärtes Ziel des Forschungsteams um King bei Meta. So gewonnene Erkenntnisse sollen auch bessere Künstliche Intelligenz ermöglichen.
Im Zentrum der Bemühungen stehen aktuell die Grundlagen des Spracherwerbs: „Menschen und speziell Kinder lernen Sprache sehr effizient. Sie lernen schnell und anhand extrem weniger Daten. Dafür benötigen sie eine spezielle Fähigkeit, die wir derzeit nicht kennen“, so King.
In einer neuen Forschungsarbeit untersuchen King und sein Team nun, ob der Wav2Vec-Algorithmus ein Licht auf diese spezielle Fähigkeit werfen kann.

Wav2Vec wird mit 600 Stunden Audio trainiert
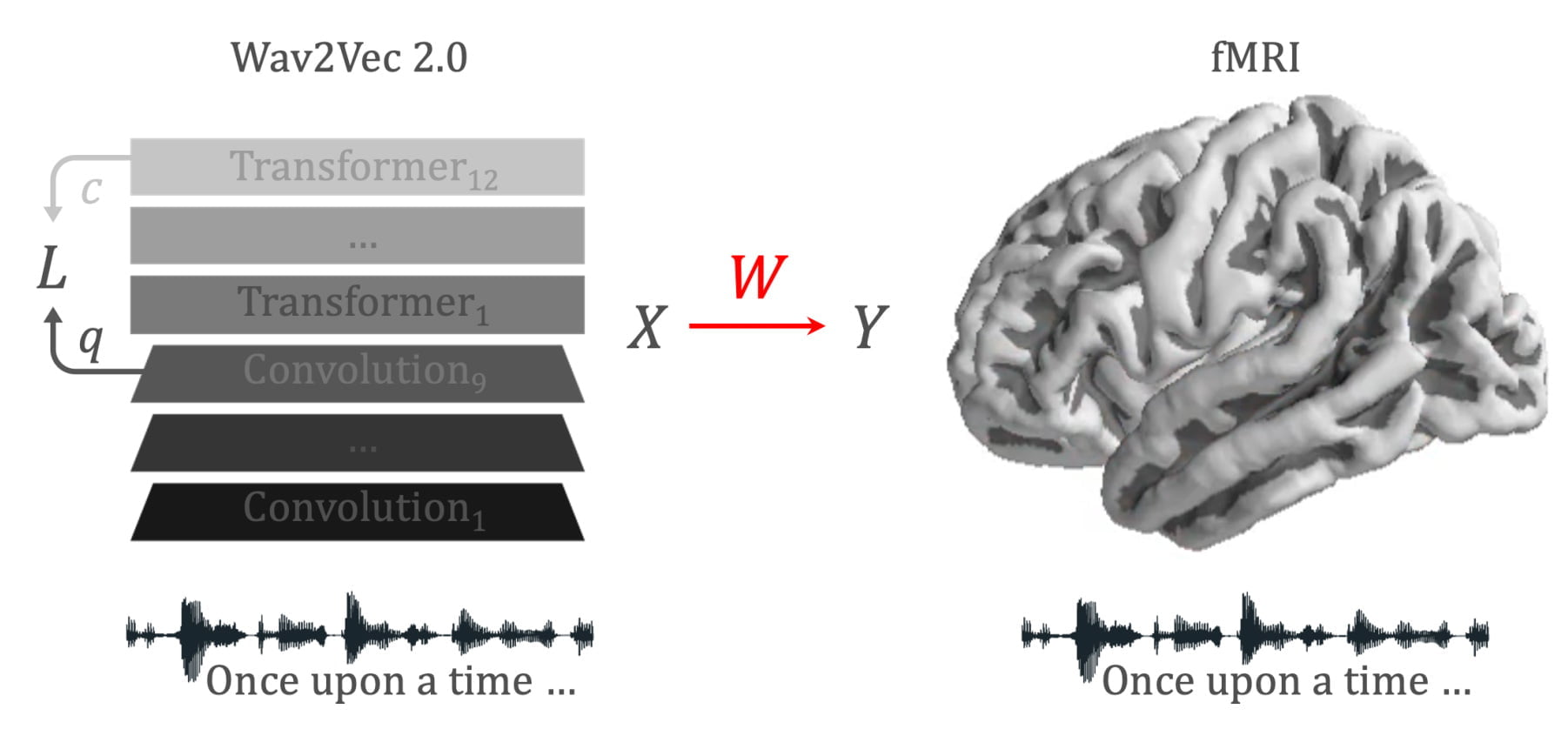
Wav2Vec 2.0 ist ein hybrides Transformer-Modell mit vorgelagerten Convolutional-Schichten, das selbstüberwacht mit Audiodaten trainiert wird und dabei eine latente Repräsentation der Wellenformen der Sprachaufnahmen lernt. Meta setzt das System und seinen Vorgänger Wav2Vec für selbstüberwacht erlernte Spracherkennung, Übersetzung oder Sprachgenerierung ein.
In der neuen Arbeit von Meta vergleichen King und sein Team ein mit 600 Stunden Sprachaufnahmen trainiertes Wav2Vec-Modell mit fMRT-Aufnahmen von 417 Personen, die Hörbücher hören. Die 600 Stunden entsprechen laut Forschenden in etwa der Menge gesprochener Sprache, die Kleinkinder während des frühen Spracherwerbs hören.
?Preprint out:
`Toward a realistic model of speech processing in the brain with self-supervised learning’:https://t.co/rJH6t6H6sm
by J. Millet*, @c_caucheteux* and our wonderful team:
The 3 main results summarized below ? pic.twitter.com/mdrJpbrb3M
— Jean-Rémi King (@JeanRemiKing) June 6, 2022
Das Experiment zeige, dass selbstüberwachtes Lernen ausreiche, damit ein KI-Algorithmus wie Wav2Vec gehirnähnliche Repräsentationen lerne, so King.
In der Arbeit weisen die Forschenden nach, dass die meisten Hirnareale signifikant mit den Aktivierungen des Algorithmus als Reaktion auf denselben Sprachinput korrelieren.
Zusätzlich entspreche die vom Algorithmus gelernte Hierarchie derjenigen des Gehirns. So sei etwa der auditorische Kortex am besten auf die erste Transformerschicht abgestimmt, während der präfrontale Kortex am besten auf die tiefsten Schichten abgestimmt sei.
KI-Forschung ist auf dem richtigen Weg
Mit den fMRT-Daten weiterer 386 Versuchspersonen, die Geräusche ohne Sprachbezug in einer fremden und in ihrer Sprache auseinanderhalten mussten, zeigen die Forschenden außerdem, dass die vom Modell erlernten hör-, sprech- und sprachspezifischen Repräsentationen mit denen des menschlichen Gehirns korrelieren.
Die Modellierung von Intelligenz auf menschlichem Niveau sei zwar ein noch weit entferntes Ziel, so King. Doch das Auftauchen gehirnähnlicher Funktionen in selbstüberwachten Algorithmen deute darauf hin, dass die KI-Forschung auf dem richtigen Weg sei.
King richtet sich damit wohl auch an Kritiker:innen des Deep-Learning-Paradigmas, die den Fokus auf tiefe Netze für eine Sackgasse halten. Kürzlich äußerte sich etwa Gary Marcus kritisch zur durch Deepminds Multitalent Gato angestoßenen Debatte über die Rolle von Skalierung auf dem Weg zu Künstlicher Intelligenz auf menschlichem Niveau.
Marcus bezeichnete diesen "Scaling-Uber-Alles"-Ansatz als Hybris und Teil einer "Alt Intelligence"-Forschung: „Bei Alt Intelligence geht es nicht darum, Maschinen zu bauen, die Probleme auf eine Weise lösen, die mit menschlicher Intelligenz zu tun hat. Es geht darum, riesige Datenmengen – oft aus dem menschlichen Verhalten abgeleitet – als Ersatz für Intelligenz zu nutzen.“


