KI-Agenten im Finanztest: Studie zeigt Lücke zwischen Versprechen und Wirklichkeit

Ein neuer Benchmark zeigt: Selbst autonome KI-Agenten scheitern an komplexen Finanzaufgaben. Trotz intensiver Tool-Nutzung und hoher Kosten bleiben die Ergebnisse hinter den Anforderungen zurück.
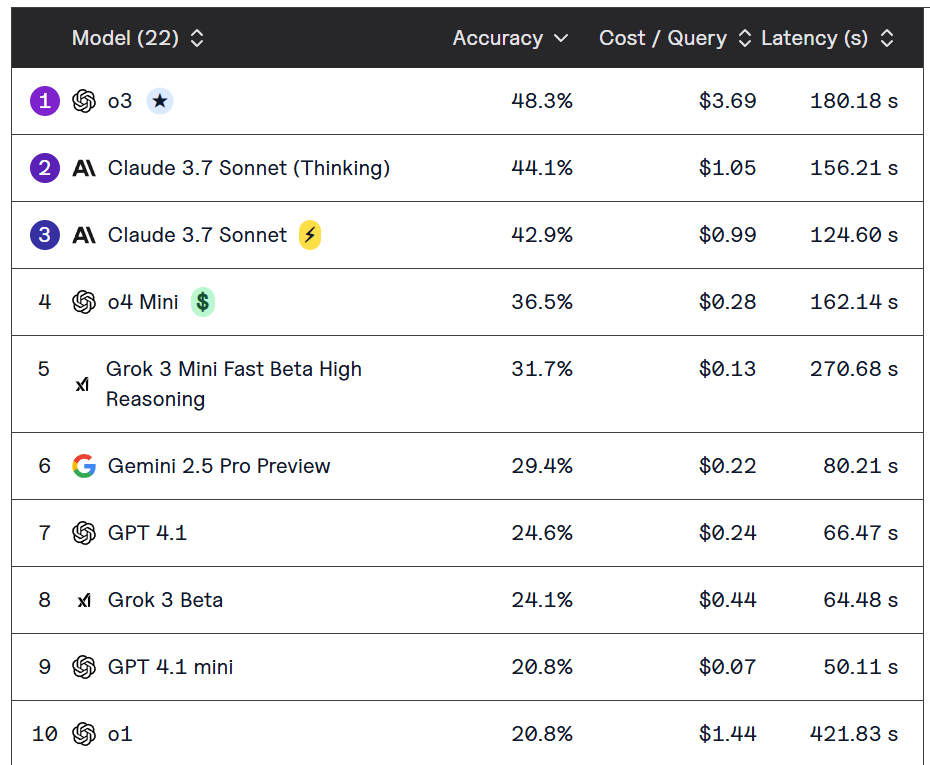
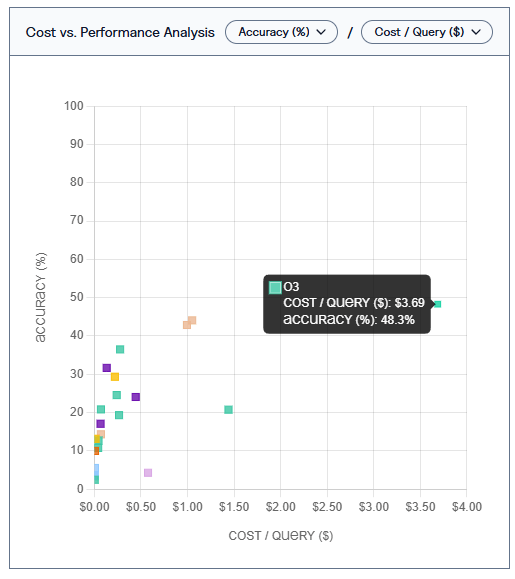
Laut einem neuen Benchmark von Vals.ai sind selbst die fortschrittlichsten KI-Agenten derzeit ungeeignet für den zuverlässigen Einsatz bei Finanzanalysen. Das beste getestete Modell, OpenAIs o3, erreichte lediglich 48,3 Prozent Genauigkeit – bei durchschnittlichen Kosten von 3,69 US-Dollar pro Antwort.
Die Studie wurde gemeinsam mit einem Stanford-Labor und einer global systemrelevanten Bank entwickelt. Sie basiert auf 537 Aufgaben, die typische Tätigkeiten von Finanzanalyst:innen abbilden, wie SEC-Dokumentenrecherche, Marktanalysen oder Prognosen. Insgesamt wurden 22 führende Foundation-Modelle getestet.
Einfaches funktioniert, Analyse nicht
Die Modelle konnten einfache Aufgaben wie das Extrahieren von Zahlenwerten oder das Zusammenfassen von Absätzen mit durchschnittlich 30 bis 38 Prozent Genauigkeit lösen. Anspruchsvollere Aufgaben, etwa Trendanalysen oder Finanzmodellierung, überforderten die Systeme fast vollständig. In der Kategorie "Trends" erzielten zehn Modelle null Prozent. Die beste Leistung stammte von Claude 3.7 Sonnet mit nur 28,6 Prozent.
Die Benchmark-Umgebung stellte den KI-Agenten Tools wie EDGAR-Zugriff, Google-Suche und HTML-Parser zur Verfügung. Modelle wie o3 oder Claude 3.7 Sonnet (Thinking), die diese Tools umfangreich nutzten, schnitten besser ab. Andere Modelle, etwa Llama 4 Maverick, verzichteten weitgehend auf Tool-Nutzung und gaben Antworten ohne Recherche – mit entsprechend schwachen Resultaten.
Allerdings zeigt das Beispiel von GPT-4o Mini, dass auch intensive Tool-Nutzung nicht automatisch zu besseren Ergebnissen führt: Das Modell führte zwar die meisten Tool-Aufrufe durch, machte dabei aber systematisch Fehler in Format und Reihenfolge – und schnitt letztlich schlecht ab.
Einige komplexe Abfragen verursachten Kosten von mehr als fünf Dollar pro Abfrage. OpenAIs o1 war besonders ineffizient: teuer, aber wenig genau. Letztlich müssten diese Kosten mit den Kosten für menschliche Arbeitskraft in einem realen Szenario verglichen werden.
Die Modellantworten zeigen zudem eine große Bandbreite an Leistungen, obwohl die zugrunde liegende Technologie ähnlich ist. Bei einer Aufgabe zu den Aktienrückkäufen von Netflix im vierten Quartal 2024 lieferten Claude 3.7, Sonnet (Thinking) und Gemini 2.5 Pro korrekte, quellenbasierte Antworten. GPT-4o und Llama 3.3 hingegen fanden keine oder falsche Informationen.
Das wiederum deutet darauf hin, dass Prompt Engineering, die System-Implementierung und insbesondere das interne Benchmarking weiter relevante menschliche Aufgaben beim KI-Einsatz bleiben.
Lücke zwischen Anspruch und Realität
Die Ergebnisse zeigen laut Vals.ai, dass heutige KI-Agenten zwar in der Lage sind, einfache, aber zeitintensive Aufgaben zu übernehmen. Für den Einsatz in stark regulierten Branchen wie dem Finanzwesen seien sie aber bisher nicht zuverlässig genug. Insbesondere bei Aufgaben mit hoher Komplexität oder Kontextsensitivität sei ein Einsatz als alleinige Entscheidungsgrundlage derzeit nicht vertretbar.
Das Urteil der KI-Bewerter fällt eindeutig aus: Trotz erheblicher Investitionen in autonome KI-Agenten für das Finanzwesen offenbare ihr Benchmark eine deutliche Lücke zwischen Marktversprechen und tatsächlicher Einsatzreife.
Die Modelle seien zwar in der Lage, einfache Daten aus Dokumenten zu extrahieren, scheitern aber an dem tiefgreifenden finanziellen Reasoning, das notwendig wäre, um Analystenarbeit wirklich zu ergänzen – oder zu ersetzen.
Vals.ai stellt das Benchmark-Framework quelloffen zur Verfügung. Die Testdaten bleiben privat, um gezieltes Training darauf zu verhindern. Eine detaillierte Auswertung der Benchmark-Resultate gibt es hier.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.