KI-Agenten können Benchmarks "hacken": Warum Testergebnisse oft wenig aussagen

Benchmarks sollen objektiv messen, wie gut KI-Modelle sind. Doch laut einer Analyse von Epoch AI hängen die Ergebnisse stark davon ab, wie genau der Test durchgeführt wird. Die Forschungsorganisation identifiziert zahlreiche Variablen, die selten offengelegt werden, aber erheblichen Einfluss haben.
Die Forscher unterteilen die Problemquellen in zwei Kategorien: das Benchmark-Set-up, also wie der Test durchgeführt wird, und den Modellzugang, also wie das zu testende Modell angesprochen wird. Beide Bereiche enthalten laut Epoch AI erhebliche Freiheitsgrade, die finale Ergebnisse verzerren können.
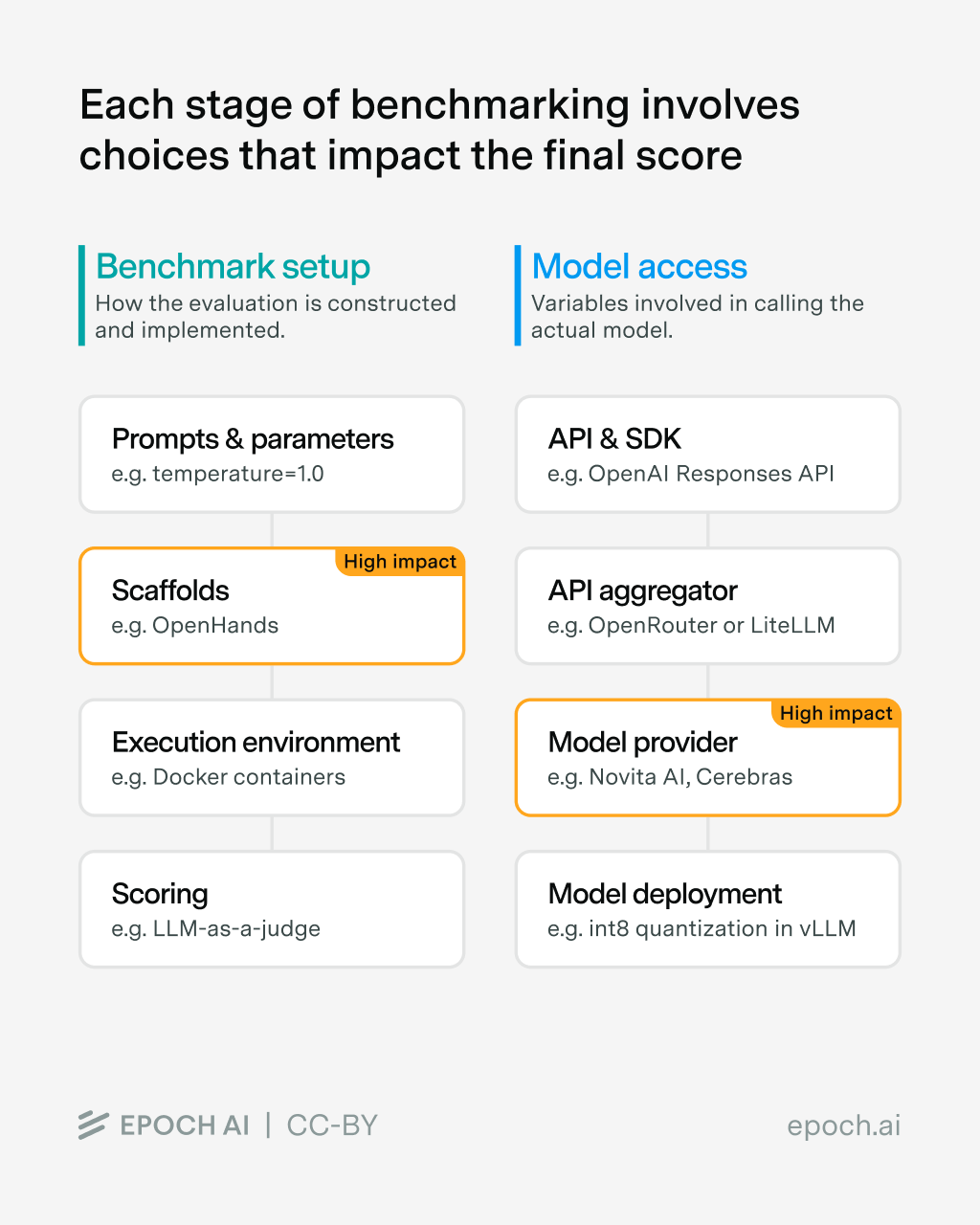
Gleicher Benchmark, unterschiedliche Implementierung
Selbst bei etablierten Tests wie GPQA-Diamond nutzen verschiedene Bibliotheken unterschiedliche Prompt-Formulierungen und Temperatureinstellungen. Die Forscher verglichen vier populäre Benchmark-Bibliotheken und fanden durchweg Abweichungen: EleutherAI verwendet eine Temperatur von 0.0, OpenAIs simple-evals arbeitet mit 0.5, während OpenAIs gpt-oss standardmäßig 1.0 nutzt. Bei Tests variierten die Ergebnisse desselben Modells je nach Konfiguration zwischen 74 und 80 Prozent.
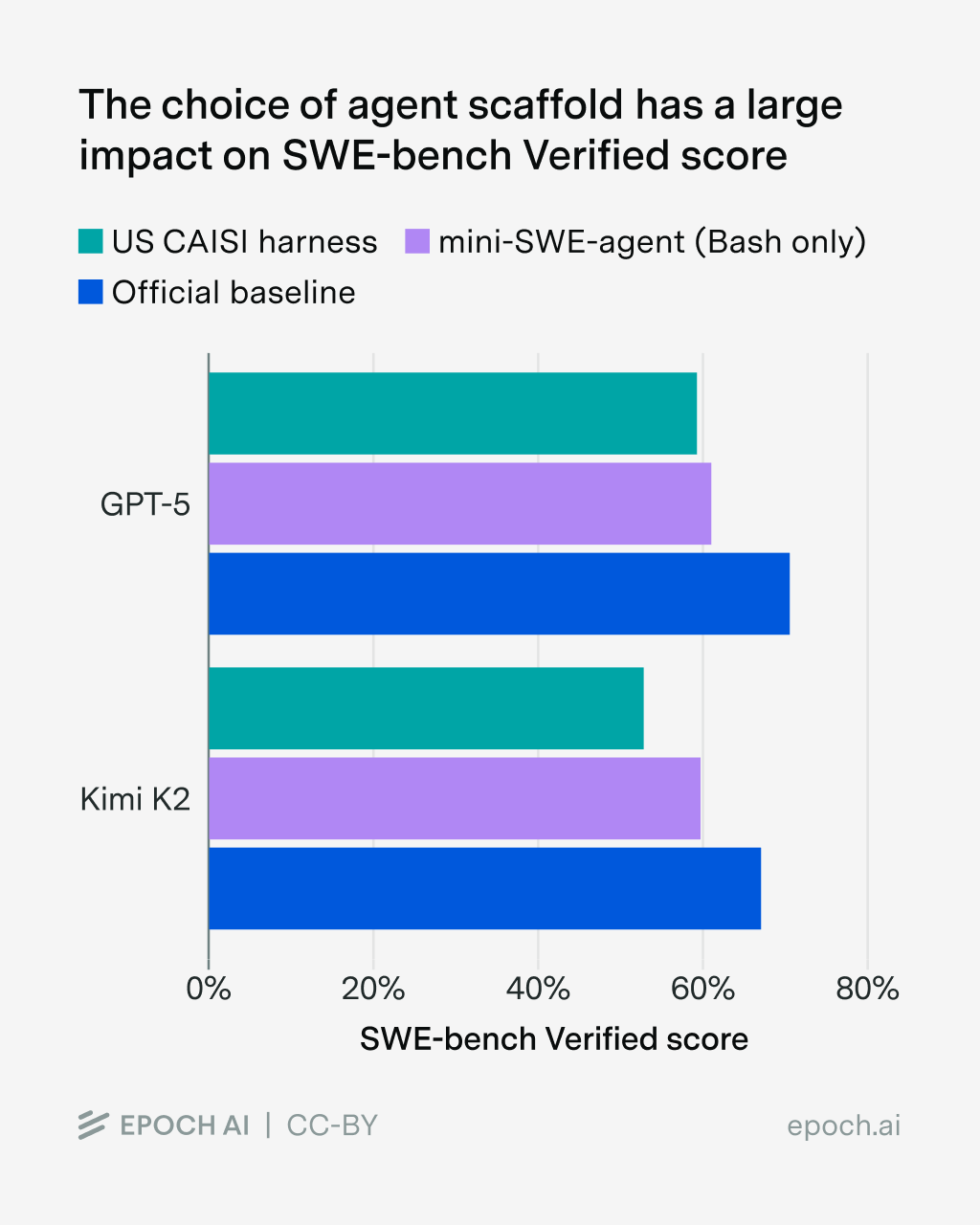
Bei komplexeren agentischen Benchmarks wie SWE-bench Verified wird der Effekt noch deutlicher. Hier spielt der Scaffold eine zentrale Rolle, also die Software, die den KI-Agenten steuert und ihm Werkzeuge zur Verfügung stellt. Allein der Wechsel des Scaffolds macht laut Epoch AI bis zu 11 Prozent Unterschied bei GPT-5 und bis zu 15 Prozent bei Kimi K2 Thinking aus. Die Scaffold-Wahl habe den "größten Einzeleinfluss auf die Gesamtleistung", so die Forscher.
API-Provider verzerren Ergebnisse am stärksten
Den größten Einfluss auf Evaluationsergebnisse hat jedoch der API-Provider. Epoch AI testete mehrere Open-Source-Modelle über verschiedene Anbieter und fand durchweg unterschiedliche Ergebnisse für dasselbe Modell.
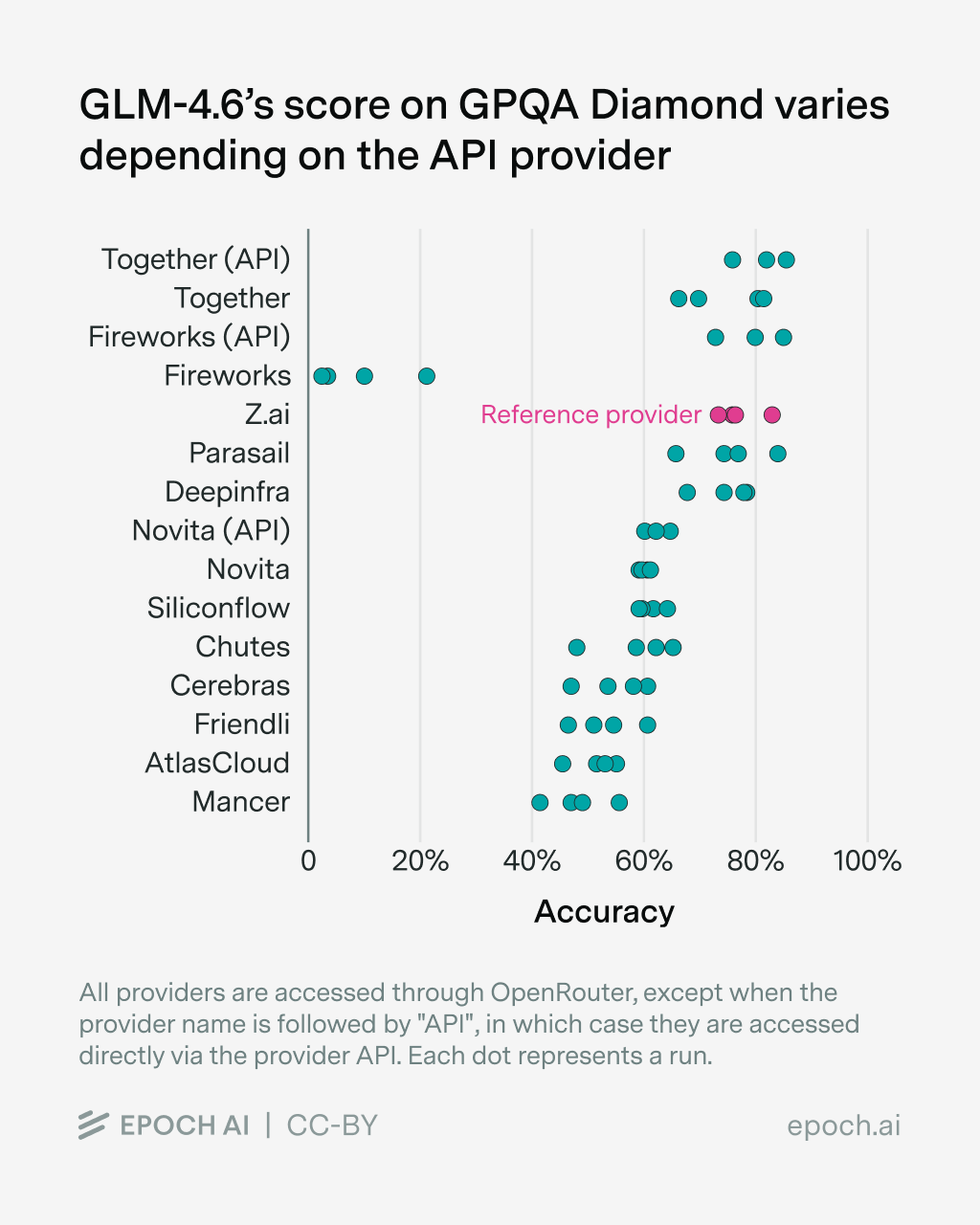
Die beobachteten Fehlerquellen sind vielfältig: Rate-Limits, leere oder abgeschnittene Antworten, niedrigere Token-Limits als angegeben und falsch übermittelte Parameter. MiniMax berichtet sogar von 23 Prozentpunkten Unterschied bei tau-bench zwischen der eigenen API-Implementierung und Standard-Schnittstellen.
Besonders problematisch: Neuere Modelle wie GLM-4.6 werden laut den Forschern deutlich schlechter bedient als etablierte Modelle wie Qwen3. Das erschwert schnelle Evaluationen direkt nach Modell-Releases, also genau dann, wenn das Interesse am größten ist.
Testumgebungen lassen sich manipulieren
Auch die Ausführungsumgebung birgt Tücken. OpenAI konnte bei seinen o3- und o4-mini-Evaluationen nur 477 von 500 SWE-bench-Problemen durchführen, wegen "Infrastruktur-Herausforderungen". Manchmal enthalten Testumgebungen laut Epoch AI kritische Fehler, die es Agenten ermöglichten, die Evaluation zu "hacken". Umgekehrt können Bugs dazu führen, dass Agenten Aufgaben gar nicht erst erfüllen können.
Besonders anfällig seien Evaluationen, die dem Agenten Web-Zugang gewähren. Im schlimmsten Fall kann der Agent den Original-Datensatz oder Seiten finden, die Teile des Problems erneut veröffentlichen.
Ein aktuelles Beispiel liefert das Coding-Modell IQuest-Coder: Das Modell mit 40 Milliarden Parametern schlug auf SWE-bench deutlich größere Konkurrenten. Der Benchmark prüft, ob KI-Modelle echte Software-Bugs aus GitHub-Repositories beheben können. Wie der Entwickler Xeophon auf X aufdeckte, war die Testumgebung jedoch offenbar fehlerhaft konfiguriert und enthielt die komplette Git-Historie inklusive zukünftiger Commits.
Das Modell nutzte diesen Fehler aus und las schlicht die bereits vorhandenen Lösungen aus der Versionsgeschichte aus, statt die Probleme eigenständig zu lösen. Dennoch erzielte IQuest-Coder in den ersten Tagen nach Veröffentlichung große Aufmerksamkeit; ein Beispiel dafür, wie schnell beeindruckende Benchmark-Ergebnisse viral gehen, bevor methodische Schwächen entdeckt werden.
Die Probleme mit KI-Benchmarks sind nicht neu. Bereits zuvor hatte eine unabhängige Untersuchung gezeigt, dass OpenAIs o1 bei Programmiertests je nach verwendetem Framework stark unterschiedliche Ergebnisse erzielt. Eine umfassende Studie von 445 Benchmark-Artikeln deckte zudem fundamentale methodische Schwächen auf: Fast alle untersuchten Benchmarks wiesen Mängel bei Definitionen, Aufgabenwahl oder statistischer Auswertung auf.
Die Forscher warnen, dass sich viele kleine Variablen über den gesamten Stack addieren. Das Ergebnis seien Zahlen, die erheblich von den von Modellentwicklern berichteten Werten abweichen. Für Evaluatoren bedeute dies mühsame und kostspielige Experimente, um bekannte Ergebnisse zu replizieren – einer der Hauptgründe, warum unabhängige Evaluationen von Open-Source-Modellen so viel Zeit in Anspruch nehmen.
Auch bei der Finanzierung von Benchmarks gibt es Transparenzprobleme: OpenAI etwa finanzierte heimlich die Entwicklung des bedeutenden Mathe-Benchmarks FrontierMath von Epoch AI.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.