KI-Agenten sind laut Anthropic bislang nur im Coding einigermaßen angekommen
Anthropic hat Millionen von Mensch-Agent-Interaktionen ausgewertet. Die Ergebnisse zeigen: KI-Agenten arbeiten zwar immer autonomer, doch fast die Hälfte aller agentischen Aktivität entfällt auf Software-Entwicklung. Andere Branchen experimentieren bestenfalls.
Wie viel Autonomie gewähren Menschen KI-Agenten tatsächlich? Und in welchen Bereichen kommen diese Agenten zum Einsatz? Anthropic hat diese Fragen nun mit einer umfangreichen Analyse von Millionen realer Interaktionen untersucht, sowohl aus dem eigenen Coding-Agenten Claude Code als auch aus der öffentlichen API. Die Ergebnisse zeichnen ein nuanciertes Bild: Agenten werden zwar autonomer, doch ihr Einsatz konzentriert sich bislang fast ausschließlich auf eine einzige Domäne.
Software Engineering macht laut der Studie knapp 50 Prozent aller agentischen Tool-Aufrufe über die öffentliche API aus. Dahinter folgen mit deutlichem Abstand Business Intelligence, Kundenservice, Vertrieb, Finanzen und E-Commerce, von denen keiner mehr als wenige Prozentpunkte des Traffics ausmacht.
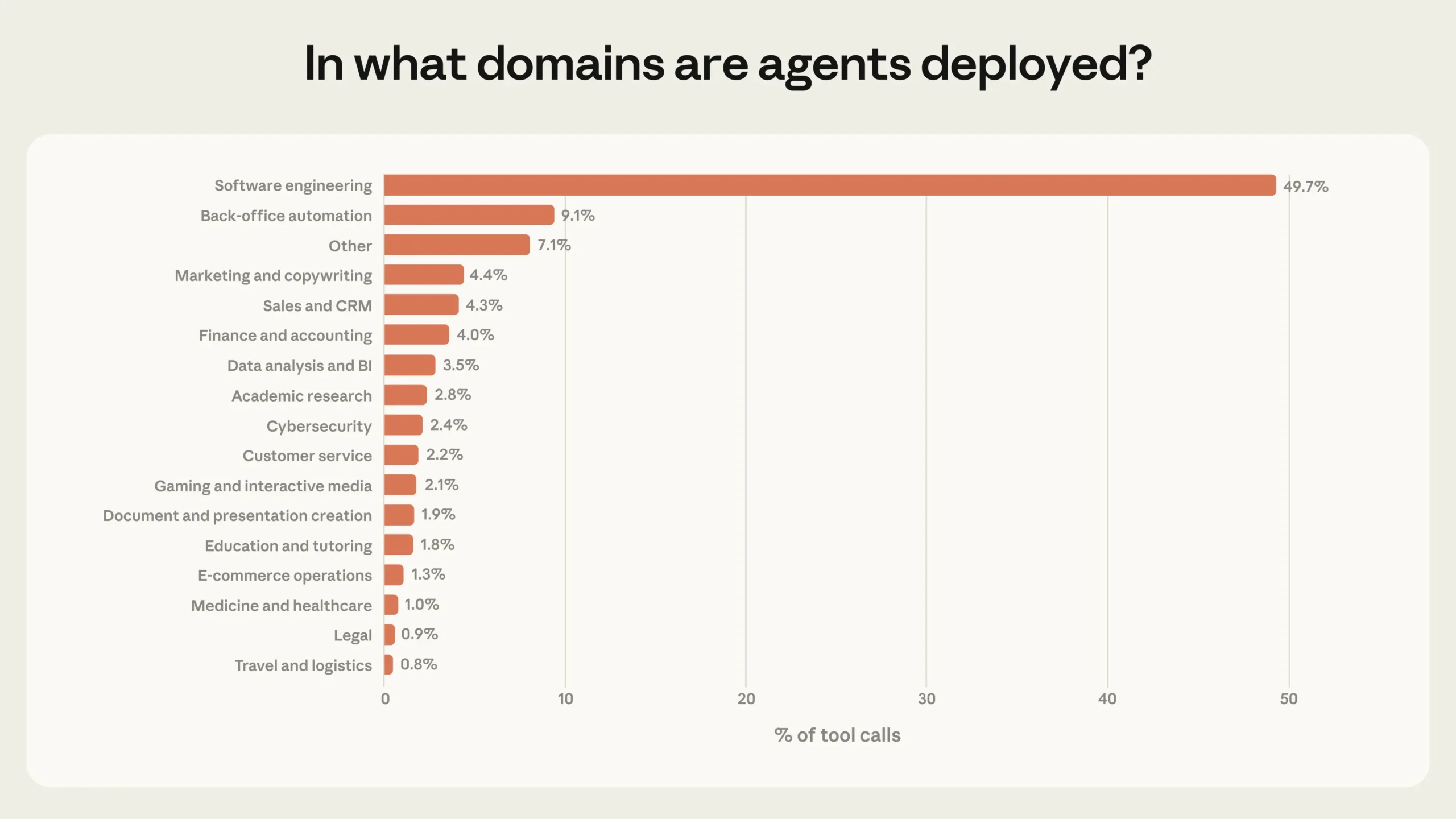
Anthropic spricht von den "frühen Tagen der Agenten-Adoption": Software-Entwickler hätten als Erste agentische Werkzeuge im großen Maßstab gebaut und genutzt, andere Branchen begännen erst zu experimentieren. Einen umfassenden Überblick über den Stand bei KI-Agenten gibt es in unserem KI-Radar zum Thema (nur TD+).
Claude Code arbeitet autonom immer länger, schöpft seine Fähigkeiten aber nicht aus
Die vielleicht auffälligste Erkenntnis betrifft die Dauer, die Claude Code ohne menschliches Eingreifen arbeitet. Während der Median bei rund 45 Sekunden pro Arbeitsschritt liegt und relativ stabil geblieben ist, hat sich das 99,9-Perzentil zwischen Oktober 2025 und Januar 2026 fast verdoppelt: von unter 25 Minuten auf mehr als 45 Minuten.
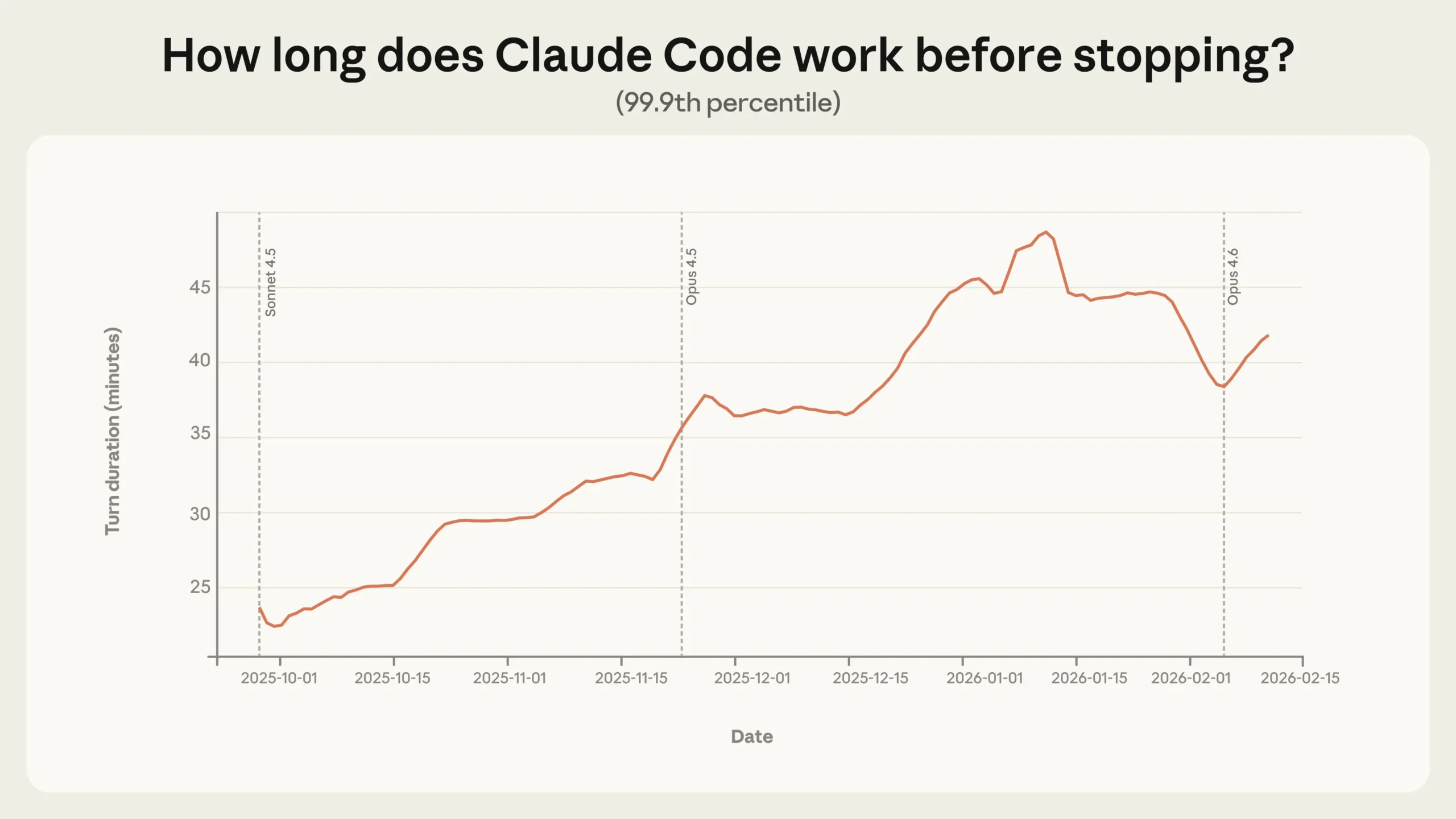
Dieser Anstieg verläuft gleichmäßig über verschiedene Modell-Releases hinweg. Wäre die wachsende Autonomie rein eine Funktion besserer Modellfähigkeiten, würde man laut Anthropic scharfe Sprünge bei neuen Versionen erwarten. Stattdessen deutet der stetige Trend darauf hin, dass mehrere Faktoren zusammenwirken: Erfahrene Nutzer bauen Vertrauen auf, stellen ambitioniertere Aufgaben und das Produkt selbst verbessert sich kontinuierlich.
Anthropic spricht in diesem Zusammenhang von einem "Deployment Overhang": Die Autonomie, die Modelle bewältigen könnten, übersteige das, was sie in der Praxis ausüben. Auch OpenAI und Microsoft-Chef Nadella benutzen das Narrativ, dass KI-Modelle schon mehr leisten können, als Menschen ihnen abverlangen. Als Vergleich zieht Anthropic eine Evaluation von METR heran, die schätzt, dass Claude Opus 4.5 Aufgaben mit 50-prozentiger Erfolgsrate lösen kann, für die ein Mensch fast fünf Stunden bräuchte.
Erfahrene Nutzer geben mehr Freiheit, greifen aber kaum häufiger ein
Je erfahrener die Nutzer, desto mehr Autonomie gewähren sie Claude Code. Bei neuen Nutzern liegt die Rate der vollständigen Auto-Freigabe bei rund 20 Prozent der Sitzungen. Nach etwa 750 Sitzungen steigt dieser Wert auf über 40 Prozent.
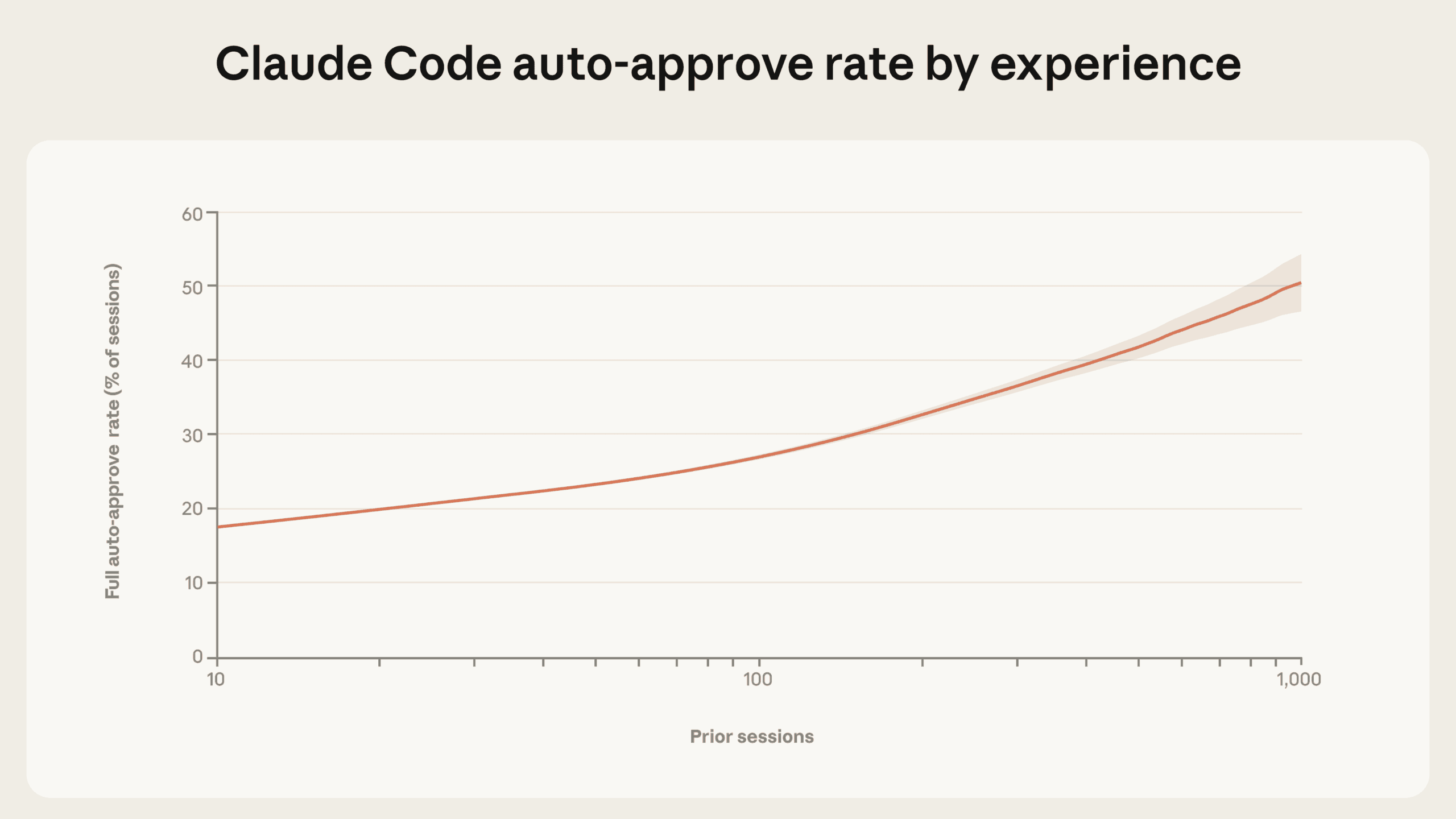
Gleichzeitig steigt die Unterbrechungsrate leicht an: von etwa 5 Prozent der Arbeitsschritte bei Neulingen auf rund 9 Prozent bei erfahrenen Nutzern. Anthropic interpretiert das als Strategiewechsel: Neue Nutzer geben jeden Schritt einzeln frei und müssen Claude deshalb seltener während der Ausführung unterbrechen.
Erfahrene Nutzer lassen Claude autonom arbeiten und greifen gezielt ein, wenn etwas schiefläuft. Allerdings sind beide Werte generell niedrig: Auch erfahrene Nutzer greifen in mehr als 90 Prozent der Arbeitsschritte nicht ein.
Ein ähnliches Muster zeigt sich auf der öffentlichen API: Bei einfachen Aufgaben wie dem Bearbeiten einer Codezeile haben 87 Prozent der Tool-Aufrufe eine Form menschlicher Beteiligung. Bei komplexen Aufgaben wie dem autonomen Finden von Zero-Day-Exploits oder dem Schreiben eines Compilers sinkt dieser Wert auf 67 Prozent.
Claude bremst sich selbst öfter als Menschen es tun
Claude Code pausiert bei komplexen Aufgaben häufiger von sich aus, um Rückfragen zu stellen, als dass Menschen es unterbrechen. Bei den anspruchsvollsten Aufgaben fragt Claude mehr als doppelt so oft nach wie bei minimaler Komplexität.
| Warum stoppt Claude sich selbst? | Warum unterbrechen Menschen Claude? |
|---|---|
| Um dem Nutzer eine Auswahl zwischen vorgeschlagenen Ansätzen zu präsentieren (35%) | Um fehlenden technischen Kontext oder Korrekturen zu liefern (32%) |
| Um diagnostische Informationen oder Testergebnisse zu sammeln (21%) | Claude war zu langsam, hing fest oder arbeitete exzessiv (17%) |
| Um vage oder unvollständige Anfragen zu klären (13%) | Sie hatten genug Hilfe erhalten, um selbstständig weiterzumachen (7%) |
| Um fehlende Zugangsdaten, Tokens oder Berechtigungen anzufordern (12%) | Sie wollten den nächsten Schritt selbst übernehmen (z.B. manuelles Testen, Deployment, Commit usw.) (7%) |
| Um eine Freigabe oder Bestätigung einzuholen, bevor eine Aktion ausgeführt wird (11%) | Um Anforderungen mitten in der Aufgabe zu ändern (5%) |
Anthropic sieht darin einen wichtigen Sicherheitsmechanismus: Modelle darauf zu trainieren, die eigene Unsicherheit zu erkennen und proaktiv nachzufragen, ergänze externe Schutzmaßnahmen wie Berechtigungssysteme und menschliche Freigaben.
Anthropic erwartet, dass Agenten an den Extremen von Risiko und Autonomie künftig häufiger werden, insbesondere wenn sich der Einsatz über Software-Engineering hinaus in Branchen mit höheren Einsätzen ausweitet.
Für Modellentwickler, Produktentwickler und politische Entscheidungsträger empfiehlt Anthropic den Ausbau von Post-Deployment-Monitoring, warnt aber ausdrücklich davor, spezifische Interaktionsmuster vorzuschreiben: Die Pflicht, jede einzelne Agenten-Aktion manuell zu genehmigen, erzeuge Reibung, ohne zwingend Sicherheitsvorteile zu bringen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.