KI-Diagnostik: Verbreitete Methode schneidet in Benchmark schlecht ab
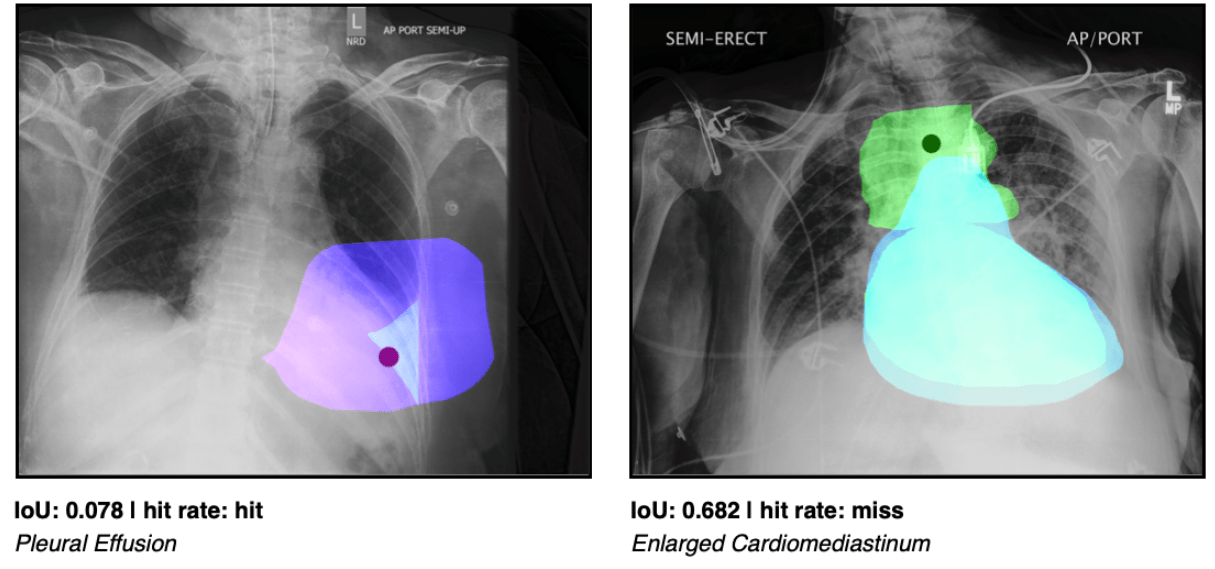
Salienz-Methoden sollen in der Medizin Licht in die Black Box KI werfen. In einem Benchmark zeigen Forschende jetzt, dass die weit verbreitete Methode unzuverlässiger ist, als angenommen.
Erklärbarkeit spielt in vielen Einsatzbereichen Künstlicher Intelligenz eine entscheidende Rolle, besonders dort, wo die Vorhersagen tiefer neuronaler Netze direkte Auswirkungen auf das Leben von Menschen haben. Es gibt zahlreiche Methoden, die die Black Box KI verständlich machen sollen. In der medizinischen Diagnostik, in der ein Großteil der Daten Bilddaten sind, werden vermehrt sogenannte Saliency-Maps (in Form von Heatmaps) genutzt, die etwa auf Röntgenbildern Zonen oder Punkte visualisieren, die die Interpretation eines KI-Systems beeinflusst haben.
Salienz-Methoden laut Studie nicht bereit für "Prime Time"
Diese Salienz-Methoden - also Methoden, die die Aufmerksamkeit neuronaler Netze visualisieren sollen - werden dabei oft hinter ein KI-Modell geschaltet, das für die Diagnostik selbst eingesetzt wird. Die Visualisierungen sollen dann behandelnden Ärtz:innen, aber auch Patient:innen ermöglichen, die Vorhersagen nachzuvollziehen oder zu überprüfen. Die Methoden sollen so auch die Akzeptanz von KI-Systemen in der Medizin erhöhen.
In einer neuen Studie zeigen Forschende nun, dass alle verbreiteten Salienz-Methoden unabhängig vom eingesetzten Diagnostik-Modell hinter der Visualisierungs-Leistung von menschlichen Expert:innen liegen. Das Team kommt daher zum Schluss, dass diese Methoden noch nicht reif für den breiten Einsatz in der klinischen Praxis sind.
"CheXlocalize"-Benchmark zeigt Grenzen der verbreiteten Methode
In der von Pranav Rajpurkar von der Harvard Medical School, Matthew Lungren von Stanford und Adriel Saporta von der New York University geleiteten Analyse überprüften die Autor:innen sieben verbreitete Salienz-Methoden auf ihre Zuverlässigkeit und Genauigkeit bei der Identifikation von zehn auf Röntgenbildern diagnostizierten Erkrankungen. Sie verglichen die Leistung der Methoden zudem mit der von menschlichen Expert:innen.
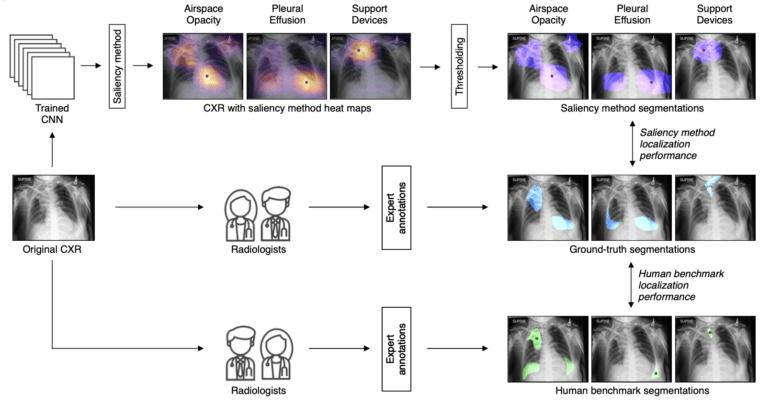
In ihrer Analyse schnitten alle Salienz-Methoden bei der Bildbewertung und der Erkennung pathologischer Läsionen durchweg schlechter ab als menschliche Radiolog:innen. Dort, wo solche Methoden bereits in der Praxis eingesetzt werden, mahnen die Autor:innen daher zur Vorsicht.
"Unsere Analyse zeigt, dass Saliency Maps noch nicht zuverlässig genug sind, um individuelle klinische Entscheidungen eines KI-Modells zu validieren", so Rajpurkar, der Assistenzprofessor für biomedizinische Informatik an der HMS ist. "Wir haben wichtige Einschränkungen identifiziert, die ernsthafte Sicherheitsbedenken für den Einsatz in der aktuellen Praxis aufwerfen."
Als mögliche Ursache für die schlechten Ergebnisse vermutet das Team algorithmische Artefakte in den Salienz-Methoden, deren relativ kleinen Heatmaps (14 x 14 Pixel) auf die ursprünglichen Bildmaße (normalerweise 2000 x 2000 Pixel) interpoliert werden.
Das Team veröffentlicht den Code, die Daten und alle Analysen auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.