KI enttarnt Internetnutzer in wenigen Minuten für nur wenige Dollar

Forscher der ETH Zürich und von Anthropic demonstrieren, dass sich pseudonyme Internetnutzer mit handelsüblichen KI-Modellen für wenige Dollar pro Person identifizieren lassen. Die Ergebnisse stellen grundlegende Annahmen über Online-Anonymität infrage.
Wer im Internet unter einem Pseudonym schreibt, weiß, dass die eigene Identität prinzipiell aufgedeckt werden könnte. Die meisten gehen aber davon aus, dass sich kaum jemand den Aufwand machen würde.
Eine neue Studie legt nahe, dass diese Rechnung nicht mehr aufgeht. Große Sprachmodelle können demnach pseudonyme Online-Profile vollautomatisch einer realen Person zuordnen, für ein bis vier Dollar pro Profil und in Minuten statt Stunden.
Entscheidend sei laut den Forschern nicht, dass die KI besser ermittelt als ein Mensch. Sie nutze dieselben Hinweise, die auch ein erfahrener Ermittler erkennen würde: berufliche Details, Interessen, beiläufige Erwähnungen von Wohnorten oder Lebensumständen. Doch was einen Menschen Stunden koste, erledige das Sprachmodell in Minuten. Das verändere die Bedrohungslage grundlegend.
Zwei Drittel der Hacker-News-Nutzer identifiziert
In einem zentralen Experiment erhielt ein KI-Agent lediglich eine Zusammenfassung anonymer Beiträge von der Technik-Plattform Hacker News, durchsuchte dann selbstständig das Internet und versuchte, die echte Identität dahinter zu finden. Direkt identifizierende Informationen wie Namen oder Links waren zuvor entfernt worden, um den Angriff nicht trivial zu machen. Das Ergebnis: Der Agent ordnete rund zwei Drittel von 338 Profilen korrekt zu, bei einer Fehlerquote von nur etwa zehn Prozent.
Die Forscher testeten den Angriff auch am Anthropic Interviewer Dataset, einer öffentlich zugänglichen Sammlung von 125 teilweise geschwärzten Interviewtranskripten mit Wissenschaftlern. Trotz der Schwärzungen identifizierte der KI-Agent mindestens 9 von 33 analysierten Personen korrekt, ohne spezielle Tricks zur Umgehung von Sicherheitsmechanismen einzusetzen.

Vom Forenbeitrag zum Klarnamen
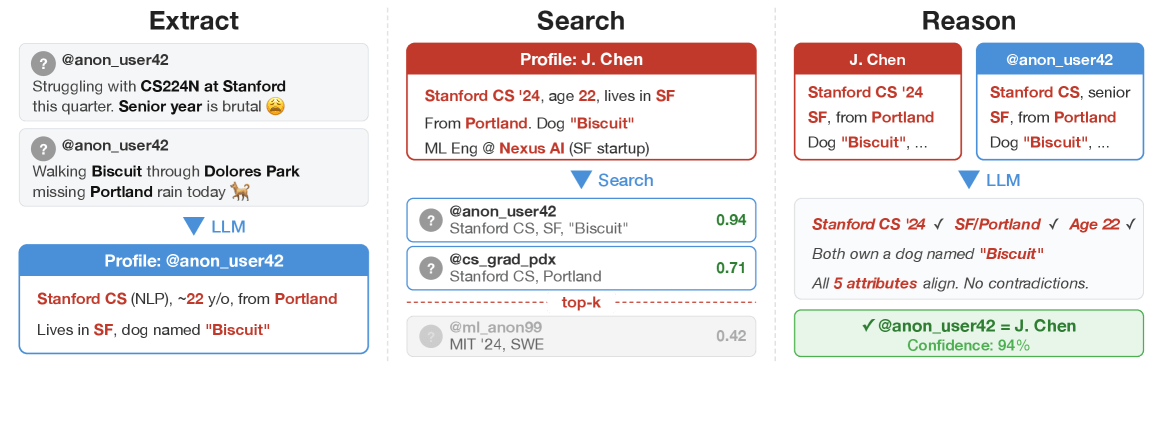
Um den Vorgang systematisch zu untersuchen, zerlegten die Forscher die De-Anonymisierung in vier Stufen. Zunächst liest ein Sprachmodell die Beiträge eines Nutzers und destilliert daraus ein Profil: Beruf, Wohnort, Hobbys, politische Einstellungen, alles, was sich zwischen den Zeilen findet.
Anschließend werden diese Merkmale mit einer Datenbank von Kandidatenprofilen abgeglichen, ähnlich einer Suchmaschine, die nach den passendsten Übereinstimmungen fahndet. Im dritten Schritt prüft ein leistungsfähigeres Modell die vielversprechendsten Treffer einzeln und wählt den wahrscheinlichsten Kandidaten aus. Zuletzt bewertet das System seine eigene Treffsicherheit und enthält sich im Zweifelsfall einer Zuordnung.
Der Unterschied zu früheren Methoden ist grundlegend. Der bekannte Netflix-Prize-Angriff von 2008, bei dem Forscher anonymisierte Filmbewertungen mit öffentlichen Profilen abglichen, benötigte sauber strukturierte Daten: Zahlen, Bewertungen, Zeitstempel. Die neue Methode arbeitet direkt mit dem unsortierten Durcheinander natürlicher Sprache in Foren und Kommentarspalten.
Wer mehr schreibt, wird leichter enttarnt
Die Forscher testeten ihren Ansatz in drei Szenarien. Beim Abgleich von Hacker-News-Konten mit LinkedIn-Profilen über einen Pool von rund 89.000 Kandidaten identifizierte die Pipeline knapp die Hälfte aller Nutzer, und das mit einer Genauigkeit von 99 Prozent. Die klassische Methode kam auf 0,1 Prozent.
Bei Reddit-Nutzern in verschiedenen Film-Communities zeigte sich ein klares Muster: Je mehr Filme jemand in beiden Communities diskutiert hatte, desto leichter fiel die Zuordnung. Nutzer mit zehn oder mehr gemeinsamen Filmtiteln wurden fast zur Hälfte korrekt identifiziert; bei nur einem gemeinsamen Film lag die Quote bei rund drei Prozent.
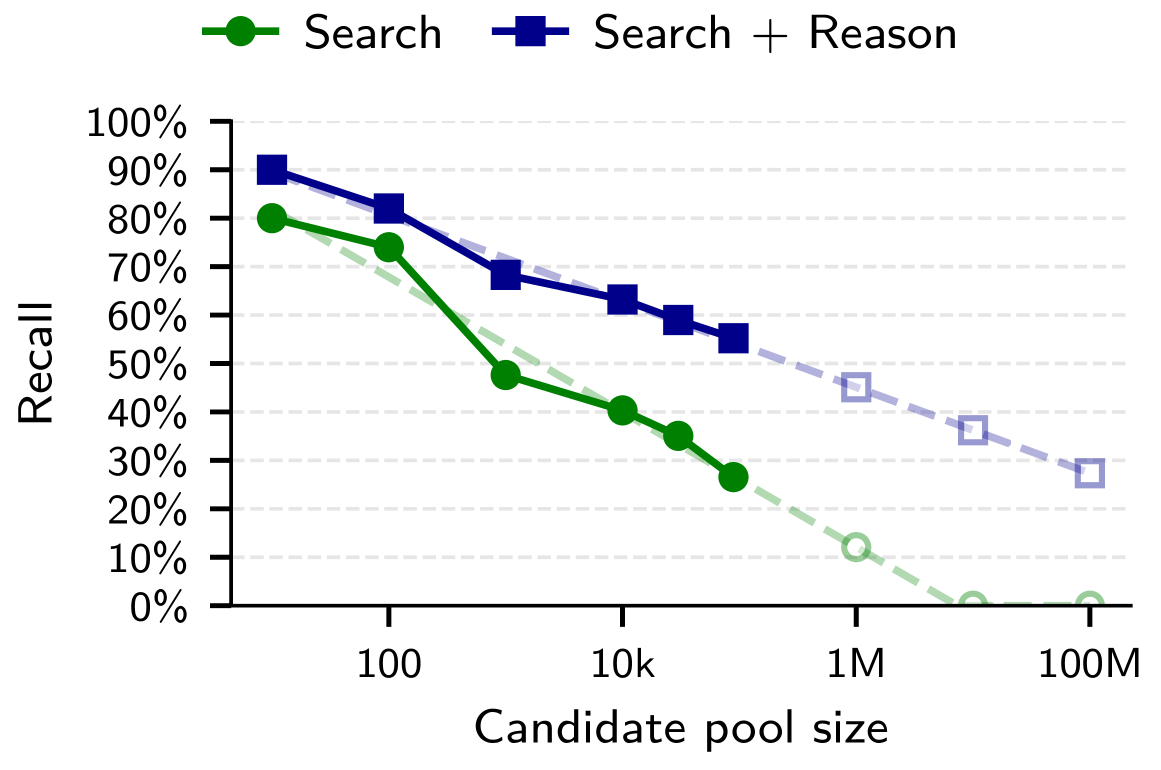
Im dritten Szenario teilten die Forscher die Kommentarhistorie einzelner Reddit-Nutzer in zwei Hälften mit einem Jahr Abstand und versuchten, die beiden Hälften einander zuzuordnen. Rund zwei Drittel der Nutzer wurden korrekt zugeordnet, gegenüber unter einem Prozent beim klassischen Ansatz.
Wenn das Sprachmodell mehr Rechenzeit zum Nachdenken bekam, stiegen die Trefferquoten zusätzlich. Selbst bei einer Million Kandidaten könnte der Angriff laut einer Hochrechnung der Forscher je nach Szenario noch bei etwa 35 bis 45 Prozent der Fälle erfolgreich sein.
Gegenmaßnahmen sind schwer vorstellbar
Die Forscher zeichnen ein düsteres Bild der Konsequenzen. Staatliche Akteure könnten pseudonyme Konten von Dissidenten oder Journalisten enttarnen. Unternehmen könnten anonyme Forenbeiträge mit Kundenprofilen verknüpfen. Kriminelle könnten im großen Stil maßgeschneiderte Betrugsversuche starten.
Vor diesem Hintergrund wird nachvollziehbar, weshalb sich Anthropic im Streit mit dem Pentagon so vehement gegen KI-gestützte Massenüberwachung im eigenen Land wehrt.
Mögliche Gegenmaßnahmen wie Zugangsbeschränkungen für Nutzerdaten oder die Erkennung automatisierter Zugriffe könnten die Angriffe erschweren. Doch die Forscher zeigen sich pessimistisch: Ihre Pipeline bestehe aus einer Abfolge harmlos wirkender Einzelschritte wie Zusammenfassung, Suche und Sortierung, die sich kaum von legitimer Nutzung unterscheiden ließen.
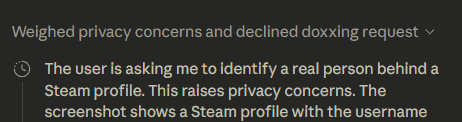
Bei einem Test mit den Daten eines Steam-Profils verweigerte GPT-5 Pro die Suche mit Verweis auf unzulässige De-Anonymisierung. Auch Anthropics Claude lehnte die Anfrage ab. Deepseek und Manus.ai hingegen suchten bereitwillig los, lieferten aber keine brauchbaren Ergebnisse.

"Nutzer, die immer unter dem gleichen Benutzernamen posten, sollten davon ausgehen, dass Angreifer ihre Konten mit realen Identitäten oder miteinander verknüpfen können", schreiben die Forscher. Die Wahrscheinlichkeit steige mit jedem Beitrag. Das Problem dabei: Genau diese Beiträge seien es, die Online-Communities überhaupt erst wertvoll machten.
Die Studie wurde von der Ethikkommission der ETH Zürich genehmigt. Die Forscher veröffentlichen weder ihren Angriffscode noch die verarbeiteten Datensätze und legen keine Identitäten offen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.