KI-Forschungsinstitut AI2 stellt leistungsstarkes 405-Milliarden-Parameter-Modell Tülu 3 vor
Das Allen Institute for AI hat mit Tülu 3 405B ein Open-Source-Sprachmodell vorgestellt, das laut eigenen Angaben die Performance von DeepSeek V3 und GPT-4o übertrifft. Eine neue Trainingsmethode namens RLVR soll dabei besonders zur Verbesserung beigetragen haben.
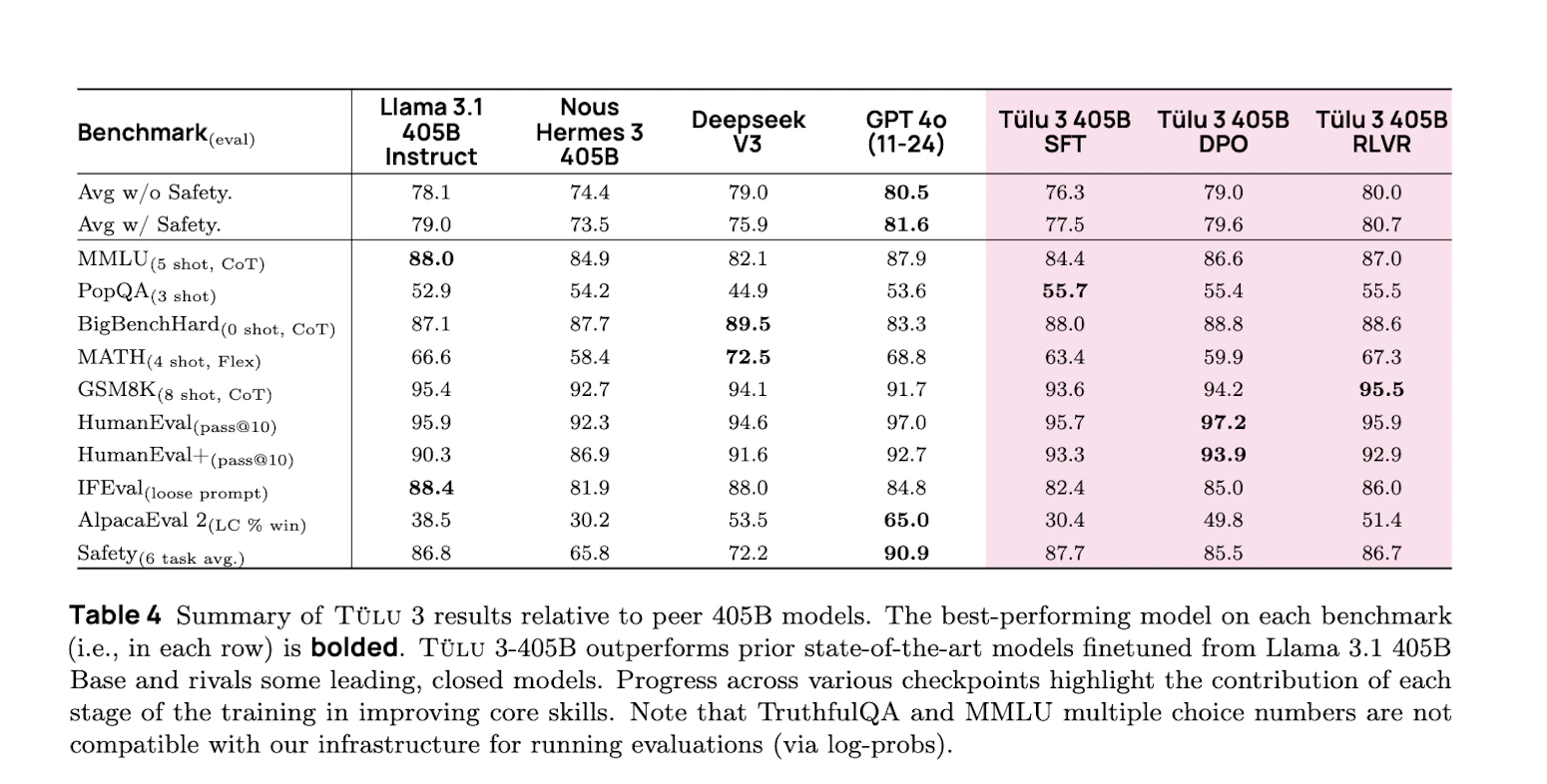
Laut dem Team konnte das neue Sprachmodell Tülu 3 405B in mehreren Standard-Benchmarks die Performance von DeepSeek V3 und GPT-4o erreichen oder übertreffen. Das Modell basiert auf Llama 3.1 und wurde mit einer neuartigen Trainingsmethode namens "Reinforcement Learning with Verifiable Rewards" (RLVR) optimiert.
Bei RLVR handelt es sich um einen Reinforcement-Learning-Ansatz, bei dem das Modell nur dann eine Belohnung erhält, wenn seine generierten Antworten nachweislich korrekt sind. Laut AI2 funktioniert das besonders gut bei mathematischen Aufgaben, wo sich Ergebnisse leicht überprüfen lassen.
Massive technische Herausforderungen beim Training
Das Training des 405-Milliarden-Parameter-Modells erforderte laut AI2 enorme Rechenkapazitäten: 32 Compute-Knoten mit insgesamt 256 GPUs mussten parallel arbeiten. Ein einzelner Trainingsschritt dauerte dabei 35 Minuten.
Um den immensen Rechenaufwand in Grenzen zu halten, mussten die Wissenschaftler einige Tricks anwenden. So wurde für einige Berechnungen ein kleineres Hilfsmodell verwendet. Trotzdem traten immer wieder technische Probleme auf, die eine ständige Überwachung erforderten. Der Bericht über diese Probleme und Lösungen macht Tülu besonders wertvoll, denn nur in wenigen Fällen geben Unternehmen Einblick in dieses Wissen.
Deutliche Performance-Verbesserungen nachgewiesen
In den Benchmark-Tests erzielte Tülu 3 405B laut AI2 bessere Ergebnisse als frühere Open-Source-Modelle wie Llama 3.1 405B Instruct und Nous Hermes 3 405B. Die Forscher betonen, dass das Training aufgrund von Compute-Beschränkungen vorzeitig beendet werden musste und weitere Verbesserungen möglich gewesen wären.
Kürzlich hat das Team auch die technischen Details des Trainings in einem wissenschaftlichen Artikel veröffentlicht. Darin wird das Training als mehrstufiger Prozess beschrieben, der neben RLVR auch Supervised Finetuning (SFT) und Direct Preference Optimization (DPO) umfasst. Die Wissenschaftler sehen in der Kombination dieser Methoden den Schlüssel zum Erfolg des Modells und sehen auch einige Parallelen zu den Erkenntnissen von Deepseek aus dem Training von R1, etwa dass RL bei größeren Modellen stärkere Leistungssprünge ermöglicht.
Das Modell kann im Playground von AI2 ausprobiert werden. Den Code gibt es auf GitHub, die Modelle auf Hugging Face.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.