KI-Modell DeepEyesV2 nutzt Werkzeuge statt Wissen - und schlägt größere Konkurrenz

Chinesische Forschende haben ein multimodales KI-Modell entwickelt, das Bilder analysiert, Code ausführt und das Web durchsucht. Statt mit purem Wissen schlägt DeepEyesV2 größere Modelle mit intelligenter Werkzeugnutzung.
Bei ersten Experimenten stieß das Forschungsteam von Xiaohongshu auf ein grundlegendes Problem. Direktes Reinforcement Learning allein führt nicht zu stabiler Werkzeugnutzung bei multimodalen Aufgaben. Die Modelle versuchten zunächst, Python-Code für Bildanalysen zu generieren, produzierten aber oft fehlerhafte Ausgaben. Mit fortschreitendem Training umgingen sie die Werkzeugnutzung ganz.
Multimodale Werkzeugnutzung erfordert neues Training
Diese Erkenntnisse führten zu einer zweistufigen Trainingspipeline. Eine Cold-Start-Phase etabliert grundlegende Muster für die Kombination von Bildverständnis und Werkzeugnutzung, gefolgt von Reinforcement Learning zur Verfeinerung.

Das Team verwendete führende Modelle wie Gemini 2.5 Pro, GPT-4o und Claude Sonnet 4 zur Erstellung von Lösungswegen und behielt nur Trajektorien mit korrekten Antworten und fehlerfreiem Code. Das Belohnungssystem für das Reinforcement Learning beschränkt sich auf zwei einfache Komponenten, nämlich Genauigkeits- und Format-Belohnungen.
DeepEyesV2 nutzt drei Werkzeugkategorien speziell für multimodale Aufgaben. Code-Ausführung ermöglicht Bildoperationen und numerische Analysen, Bildsuche findet visuell ähnliche Inhalte und Textsuche liefert ergänzende Informationen zu visuellen Inhalten.
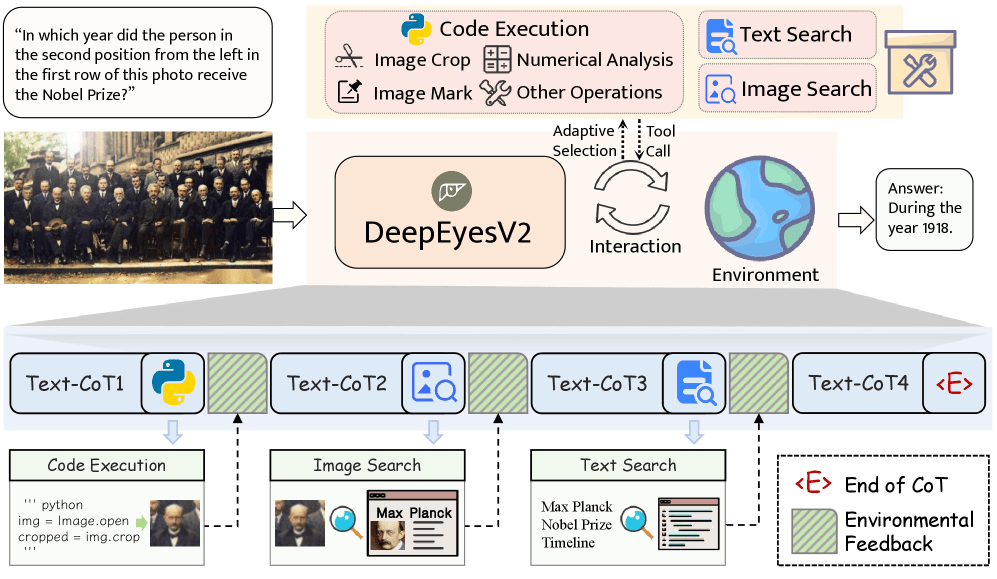
Neue Benchmark testet koordinierte Bild-Werkzeug-Nutzung
Die Forschenden entwickelten RealX-Bench, einen Benchmark, der explizit die Koordination von Bildwahrnehmung, Websuche und logischem Denken testet.
Ein Beispiel aus der Studie verdeutlicht die Komplexität: Das Modell soll eine Blume in einem Foto identifizieren. Dazu schneidet es zunächst die relevante Bildregion aus, um Details besser zu erkennen. Anschließend startet es eine visuelle Websuche mit dem ausgeschnittenen Bild, um ähnliche Blumen zu finden. Schließlich kombiniert es die gefundenen Informationen, um die genaue Art zu bestimmen.

Diese mehrstufige Herangehensweise zeigt, warum bestehende KI-Modelle an ihre Grenzen stoßen. Die Ergebnisse offenbaren eine erhebliche Leistungslücke zwischen KI und Menschen. Selbst das beste proprietäre Modell erreichte nur 46 Prozent Genauigkeit, während Menschen 70 Prozent erzielten.
Besonders problematisch ist die Koordination aller drei Fähigkeiten. Laut der Studie sank Geminis Genauigkeit bei Aufgaben, die alle drei Bereiche erfordern, von 46 auf nur 27,8 Prozent. Diese Diskrepanz zeigt, dass aktuelle Modelle zwar einzelne Fähigkeiten beherrschen, aber bei deren Integration versagen können.

DeepEyesV2 erzielte 28,3 Prozent Gesamtgenauigkeit und lag damit vor seinem Basismodell Qwen2.5-VL-7B mit 22,3 Prozent, aber hinter den größeren Varianten mit 32 beziehungsweise 72 Milliarden Parametern. Bei Aufgaben, die alle drei Fähigkeiten koordinieren müssen, übertraf DeepEyesV2 jedoch andere Open-Source-Modelle.
Die Analyse zeigte auch, dass Suchfunktionen die Genauigkeit erheblich verbessern, wobei Textsuche größere Verbesserungen bringt als Bildsuche. Dies deutet darauf hin, dass aktuelle Modelle noch Schwierigkeiten haben, visuelle Suchergebnisse effektiv zu integrieren.
Werkzeugnutzung gleicht Größennachteile aus
Der eigentliche Durchbruch von DeepEyesV2 zeigt sich in spezialisierten Benchmarks. Bei mathematischen Denkaufgaben erreichte das Modell 52,7 Prozent Genauigkeit auf MathVerse, eine Steigerung von 7,1 Prozentpunkten gegenüber dem Basismodell.
Auch bei suchorientierten Aufgaben zeigen sich Verbesserungen. DeepEyesV2 erzielte 63,7 Prozent auf MMSearch und übertraf damit das spezialisierte MMSearch-R1-Modell mit 53,8 Prozent. Bei alltäglichen Bildverständnisaufgaben schlug das 7-Milliarden-Parameter-Modell teilweise sogar Qwen2.5-VL-32B, das mehr als viermal so viele Parameter besitzt.
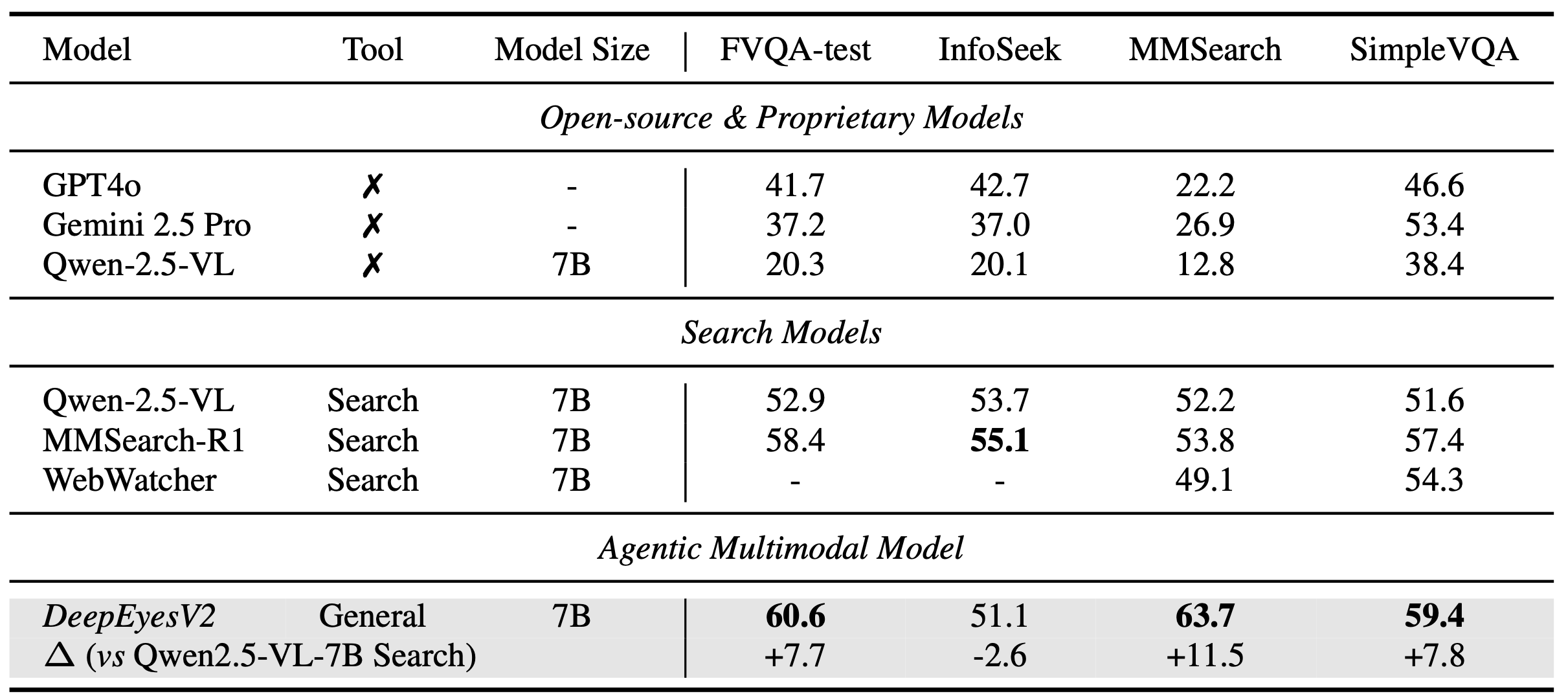
Diese Ergebnisse zeigen, dass geschickte Werkzeugnutzung Größennachteile ausgleichen kann. Statt durch mehr Parameter wird die Leistung durch die Fähigkeit gesteigert, externe Ressourcen gezielt einzusetzen.
Aufgabenabhängige Strategien bei visuellen Problemen
Die Analyse der Werkzeugnutzung zeigte deutliche aufgabenspezifische Muster. Bei visuellen Wahrnehmungsaufgaben extrahiert das Modell relevante Bildregionen; bei mathematischen Problemen mit Diagrammen kombiniert es Bildanalyse mit numerischen Berechnungen. Wissensintensive visuelle Fragen beantwortet es, indem es gezielte Websuchen auf Basis der Bildinhalte startet.
Nach dem Reinforcement-Learning-Training (RL-Training) entwickelte das Modell ein adaptiveres Verhalten. Die Häufigkeit der Werkzeugnutzung nahm deutlich ab – ein Hinweis darauf, dass das Modell gelernt hat, Hilfsmittel nur bei Bedarf einzusetzen. Die weiterhin hohe Varianz bei der Anzahl der Werkzeugaufrufe deutet jedoch auf flexible, aufgabenspezifische Strategien hin.
Das chinesische Unternehmen Xiaohongshu hat sich erst vor wenigen Monaten mit der Veröffentlichung seines ersten Open-Source-Sprachmodells auf der weltweiten KI-Landkarte positioniert. dots.llm1 erzielte in mehreren Benchmarks konkurrenzfähige Ergebnisse und übertrifft Modelle von Alibaba und Deepseek hinsichtlich Effizienz. Auch das Zeichenerkennungsmodell dots.ocr überzeugte in dieser Hinsicht.
Das im Mai veröffentlichte DeepEyes verband bereits Reasoning-Fähigkeiten mit multimodalem Verständnis. DeepEyesV2 führt diesen Ansatz fort und stärkt die Bemühungen, diese Basistechniken in agentischen Umgebungen sinnvoll zu verknüpfen. Xiaohongshu, hierzulande auch unter dem Namen Rednote bekannt, betreibt ähnlich wie Tiktok eine große chinesische Social-Media- und E-Commerce-Plattform.
Das Modell DeepEyesV2 ist auf Hugging Face und GitHub unter der Apache-Lizenz 2.0 verfügbar und darf auch kommerziell genutzt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.