KI-Modelle lassen sich laut Apple-Forschern schlechter steuern als angenommen
Ein neues theoretisches Framework legt nahe, dass die Kontrollierbarkeit von Sprachmodellen und Bildgeneratoren überraschend fragil ist. Die Steuerbarkeit hängt stark von der jeweiligen Aufgabe und dem verwendeten Modell ab.
Auf Anfrage eine gerade oder ungerade Zahl zu generieren, ist für Menschen eine leichte Aufgabe. Sprachmodelle zeigen hier sehr unterschiedliche Leistungen: Während Gemma3-4B diese Aufgabe mit fast perfekter Kalibrierung meistert, scheitern andere Modelle wie SmolLM3-3B daran. Diese Schwankungen könnten laut einer neuen Apple-Studie symptomatisch für ein grundlegendes Problem generativer KI-Modelle sein.
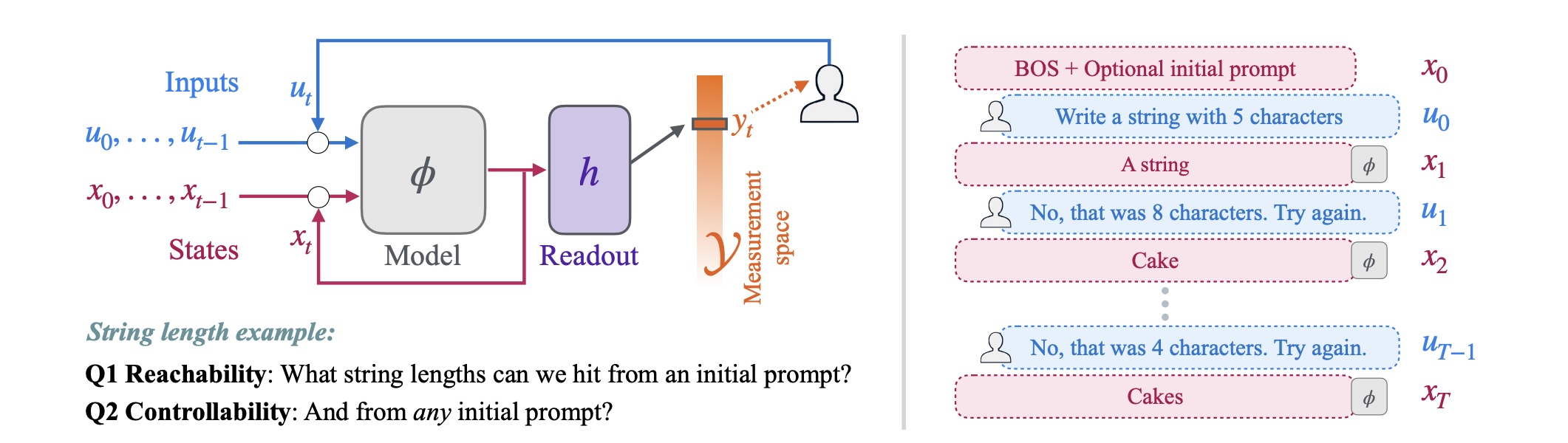
Forscher von Apple und der spanischen Universitat Pompeu Fabra haben systematisch untersucht, wie kontrollierbar Sprachmodelle und Bildgeneratoren tatsächlich sind. Ihr Fazit fällt ernüchternd aus: Die Fähigkeit, ein Modell zu einem gewünschten Ergebnis zu steuern, scheint hochgradig abhängig von der spezifischen Kombination aus Modell, Aufgabe und Ausgangsprompt zu sein.
Die Forscher unterscheiden zwei Konzepte, die in der Praxis oft verwechselt würden:
- Kontrollierbarkeit (Controllability) beschreibt, ob ein Modell gewünschte Ausgaben von jedem beliebigen Ausgangszustand aus erreichen kann.
- Kalibrierung (Calibration) meint hingegen, wie genau das Modell die Nutzeranfrage umsetzt. Ein Modell könnte theoretisch alle gewünschten Ausgaben erreichen, dabei aber systematisch von der Anfrage abweichen.
Sprachmodelle mit unberechenbaren Leistungsschwankungen
Die Forscher testeten SmolLM3-3B, Qwen3-4B und Gemma3-4B mit Aufgaben wie der Steuerung von Textformalität, Stringlänge und der Generierung gerader oder ungerader Zahlen.
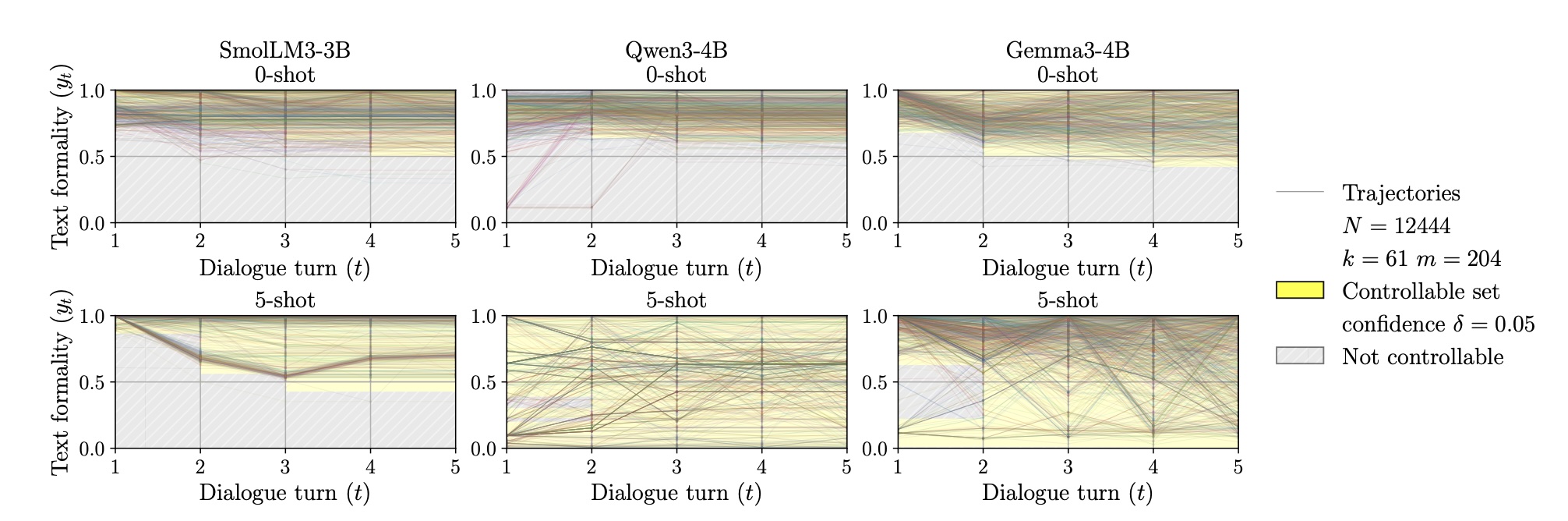
Bei der Formalitäts-Aufgabe mit 5-shot-Prompting erreichten Qwen3-4B und Gemma3-4B laut der Studie volle Kontrollierbarkeit innerhalb von fünf Dialogrunden. SmolLM3-3B blieb hingegen unkontrollierbar. Auffällig waren demnach starke Überschießeffekte. Selbst wenn das Feedback explizit die Ziel-Formalität nannte, korrigierten die Modelle oft zu stark in die Gegenrichtung.
Die Aufgabe mit geraden und ungeraden Zahlen zeigte die Unberechenbarkeit der Modelle besonders deutlich. Qwen3-4B erreichte perfekte Kontrollierbarkeit. Gemma3-4B erzielte bei dieser Aufgabe zwar eine fast perfekte Kalibrierung, doch die vollständige Kontrollierbarkeit über den gesamten Messraum hinweg blieb eine Herausforderung.
Ein Experiment mit Qwen-Modellen von 0,6 bis 14 Milliarden Parametern zeigte zudem, dass größere Modelle kontrollierbarer sind. Die meisten Verbesserungen flachten jedoch ab etwa 4 Milliarden Parametern ab.
Bildgeneratoren kämpfen mit Objektplatzierung
Bei Text-zu-Bild-Modellen wie FLUX-s und SDXL untersuchten die Forscher die Kontrolle über Objektanzahl, Objektposition und Bildsättigung. FLUX-s schnitt bei der Objektanzahl am besten ab: Mehr angeforderte Objekte führten zuverlässig zu mehr Objekten im Bild. Die exakte Anzahl traf das Modell aber selten, im Schnitt lag es um etwa 3,5 Objekte daneben.
Am deutlichsten zeigte sich die Diskrepanz zwischen Kontrollierbarkeit und Kalibrierung bei der Bildsättigung. FLUX-s und SDXL konnten zwar Bilder mit allen möglichen Sättigungswerten erzeugen, ob ein Bild jedoch stark oder schwach gesättigt ausfiel, hatte kaum etwas mit der Anfrage zu tun. Die Korrelation zwischen gewünschter und tatsächlicher Sättigung lag unter 0,1.
Open-Source-Toolkit veröffentlicht
Das Framework basiert auf Konzepten aus der Kontrolltheorie und formalisiert Dialogprozesse mit KI-Modellen als Kontrollsysteme. Die Forscher haben ihre Methoden als Open-Source-Toolkit veröffentlicht, das die systematische Analyse von Modell-Kontrollierbarkeit ermöglichen soll.
Die in der Studie untersuchten Modelle reichen bis 14 Milliarden Parameter; echte Frontier-Modelle wie GPT-5 oder Claude 4.5, mit denen viele Menschen täglich interagieren, blieben außen vor. Die Autoren betonen jedoch, dass ihr Framework allgemein formuliert und architekturagnostisch ist. Es soll für jedes generative Modell gelten.
Die gezeigte Skalierungskurve lege zwar nahe, dass größere Modelle kontrollierbarer werden, nicht aber, dass das Problem bei Frontier-Modellen verschwindet. Vielmehr liefere das Toolkit erstmals die Möglichkeit, auch solche Modelle systematisch auf ihre tatsächliche Steuerbarkeit hin zu testen.
Die Autoren plädieren daher für einen Perspektivwechsel: Kontrollierbarkeit sollte nicht vorausgesetzt, sondern explizit analysiert werden. Die Ergebnisse legten nahe, dass selbst bei einfachen Testaufgaben kein Modell und kein Prompting-Ansatz durchgängig funktioniere.
Eine fragile Kontrollierbarkeit ist nicht das einzige Problem: Eine Anthropic-Studie zeigte, dass Modelle die Einhaltung von Sicherheitsregeln vortäuschen können, während sie im Hintergrund andere Ziele verfolgen. Zudem erkennen KI-Modelle Testsituationen und passen ihr Verhalten entsprechend an, was die Aussagekraft von Benchmarks untergraben kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.