KI-Modelle müssen vor Gericht: o1 schlägt Gemini im kniffligen "Ace Attorney" Gaming-Test

Forscherinnen und Forscher haben die Denkfähigkeiten führender KI-Modelle anhand eines Videospiels getestet, in dem es darum geht, Gerichtsverfahren zu gewinnen. Die Ergebnisse zeigen interessante Unterschiede in Leistung und Kosteneffizienz.
Ein Forschungsteam des Hao AI Lab an der University of California San Diego hat führende KI-Modelle einer ungewöhnlichen Herausforderung gestellt: Sie mussten sich im Titel "Phoenix Wright: Ace Attorney" beweisen.
Die Inspiration dafür kam nach eigener Aussage von KI-Pionier Ilya Sutskever, der einst die Fähigkeit zur Vorhersage des nächsten Wortes mit dem Verständnis einer Kriminalgeschichte verglich. OpenAI-Mitgründer und ehemaliger Chefwissenschaftler Sutskever hat sich kürzlich für sein geheimnisvolles KI-Start-up eine weitere Milliardenfinanzierung gesichert.
"Ace Attorney" eigne sich laut dem Hao AI Lab besonders gut für diesen Test, da es von den Spieler:innen verlangt, Beweise zu sammeln, Widersprüche aufzudecken und die Wahrheit hinter Lügen zu enthüllen. Die KI-Modelle mussten dabei in Kreuzverhören Ungereimtheiten erkennen und mit den richtigen Beweisen konfrontieren.
o1 an der Spitze, Gemini mit Abstand dahinter
Die Wissenschaftler:innen testeten mehrere aktuelle, multimodale KI-Modelle, darunter OpenAI o1, Gemini 2.5 Pro, Claude 3.7-thinking und Llama 4 Maverick. Dabei zeigten o1 und Gemini 2.5 Pro die beste Performance und erreichten beide Level 4, wobei o1 einen leichten Vorsprung bei den schwierigsten Fällen hatte.
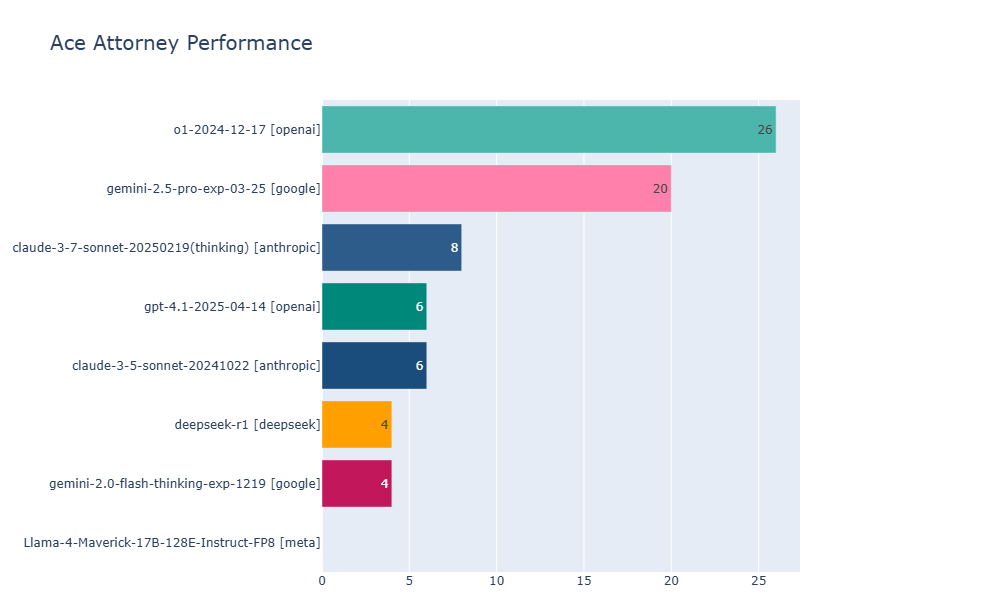
Nach Angaben der Forschenden testet das Spiel verschiedene zentrale Eigenschaften, die aktuelle KI-Systeme voneinander unterscheiden: Sie müssen lange Kontexte durchsuchen und darin Widersprüche erkennen, visuelle Informationen präzise verstehen und strategische Entscheidungen im Spielverlauf treffen.
Bei der Entwicklung von Spielen geht die KI über einfache Text- und Bildaufgaben hinaus und muss das Verstehen in kontextbezogene Handlungen umsetzen. Overfitting ist schwieriger, da Erfolg in diesem Bereich das Denken in kontextabhängigen Aktionen erfordert und nicht nur auf Auswendiglernen basiert.
Overfitting bedeutet, dass sich ein KI-Modell die Trainingsdaten - einschließlich aller Zufälligkeiten und Fehler - merkt und deshalb neue, unbekannte Daten schlechter verarbeitet. Es tritt nach aktuellem Kenntnisstand auch bei Reasoning-Modellen auf, die beispielsweise für Mathe- und Code-Aufgaben optimiert sind.
Gemini Pro 2.5 bietet das beste Preis-Leistungs-Verhältnis
Gemini 2.5 Pro erwies sich zudem als deutlich kosteneffizienter als andere getestete Modelle. Laut Hao AI Lab ist es je nach Fall sechs- bis fünfzehnmal günstiger als o1. In Level 2, einem besonders langen Fall, kostete o1 über 45,75 Dollar, während Gemini 2.5 Pro nur 7,89 Dollar verbrauchte.
Selbst im Vergleich zum gerade erst eingeführten GPT-4.1, das allerdings kein Reasoning-Modell ist, schneidet Gemini 2.5 Pro preislich besser ab: Es kostet 1,25 Dollar pro Million Input-Token gegenüber 2 Dollar bei GPT-4.1. Die Wissenschaftler:innen weisen allerdings darauf hin, dass die tatsächlichen Kosten aufgrund der Bildverarbeitung leicht höher liegen könnten.
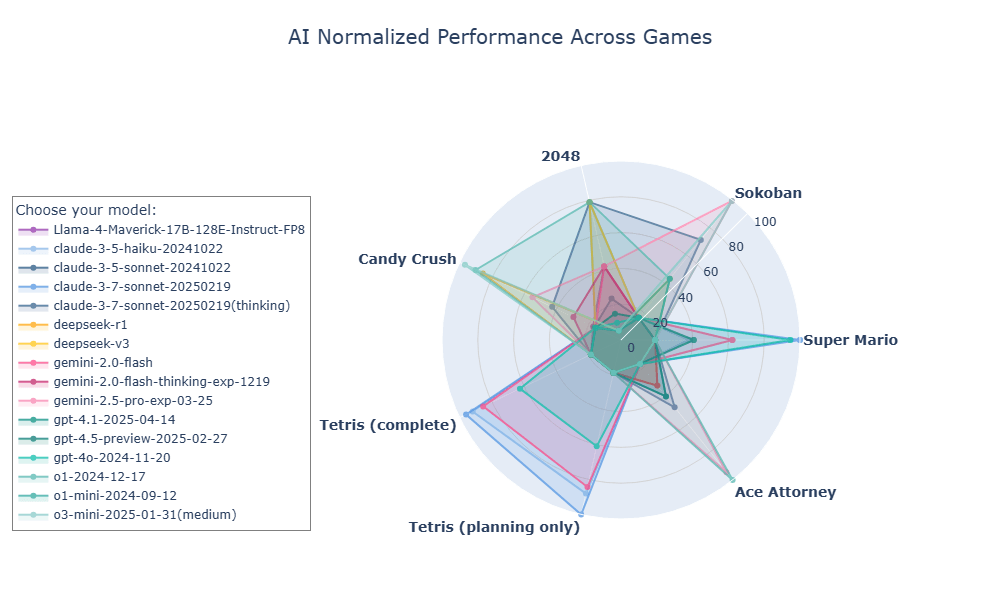
Im Benchmark Game Arena stellen die Forschenden bereits seit Ende Februar aktuelle Sprachmodelle in Spielen wie Candy Crush, 2048, Sokoban, Tetris und Super Mario auf die Probe. Ace Attorney dürfte das Spiel mit der anspruchsvollsten Mechanik der bisher getesteten Titel sein.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.