KI-Modelle schreiben Roboter-Code fast so gut wie Menschen, aber nur mit Stützrädern

Ein neues Framework von Nvidia, UC Berkeley und Stanford untersucht systematisch, wie gut KI-Modelle Roboter per Code steuern können. Das Ergebnis: Ohne menschliche Abstraktionen scheitern selbst die besten Modelle, doch mit gezielter Laufzeit-Skalierung schließt sich die Lücke.
Forschende von Nvidia, UC Berkeley, Stanford und Carnegie Mellon haben mit CaP-X ein Open-Access-Framework vorgestellt, das systematisch untersucht, wie gut KI-Coding-Agenten Roboter durch selbst geschriebene Programme steuern können. Das Ergebnis: Keines der zwölf getesteten Frontier-Modelle erreicht im Einzelversuch die Zuverlässigkeit menschlich geschriebener Programme.
Der Grundgedanke des Papers: Statt roboterspezifische Modelle mit großen Bewegungsdatensätzen zu trainieren, sollen allgemeine Sprachmodelle Steuerungscode schreiben. Dafür übertragen die Forschenden Methoden, die sich bei Sprachmodellen bewährt haben, auf die Robotik: bestärkendes Lernen mit überprüfbaren Belohnungen aus der Physiksimulation, Skalierung der Rechenzeit bei der Ausführung durch parallele Lösungsvorschläge und Selbstkorrektur, sowie agentische Muster wie automatisches Debugging und das Ansammeln wiederverwendbarer Funktionen, wie sie bei Software-Engineering-Agenten entwickelt wurden.
Getestet wurden unter anderem Gemini-3-Pro, GPT-5.2, Claude Opus 4.5 und mehrere Open-Source-Modelle wie Qwen3-235B und DeepSeek-V3.1 auf sieben Manipulationsaufgaben getestet, von einfachem Würfelheben bis zu beidhändiger Koordination.
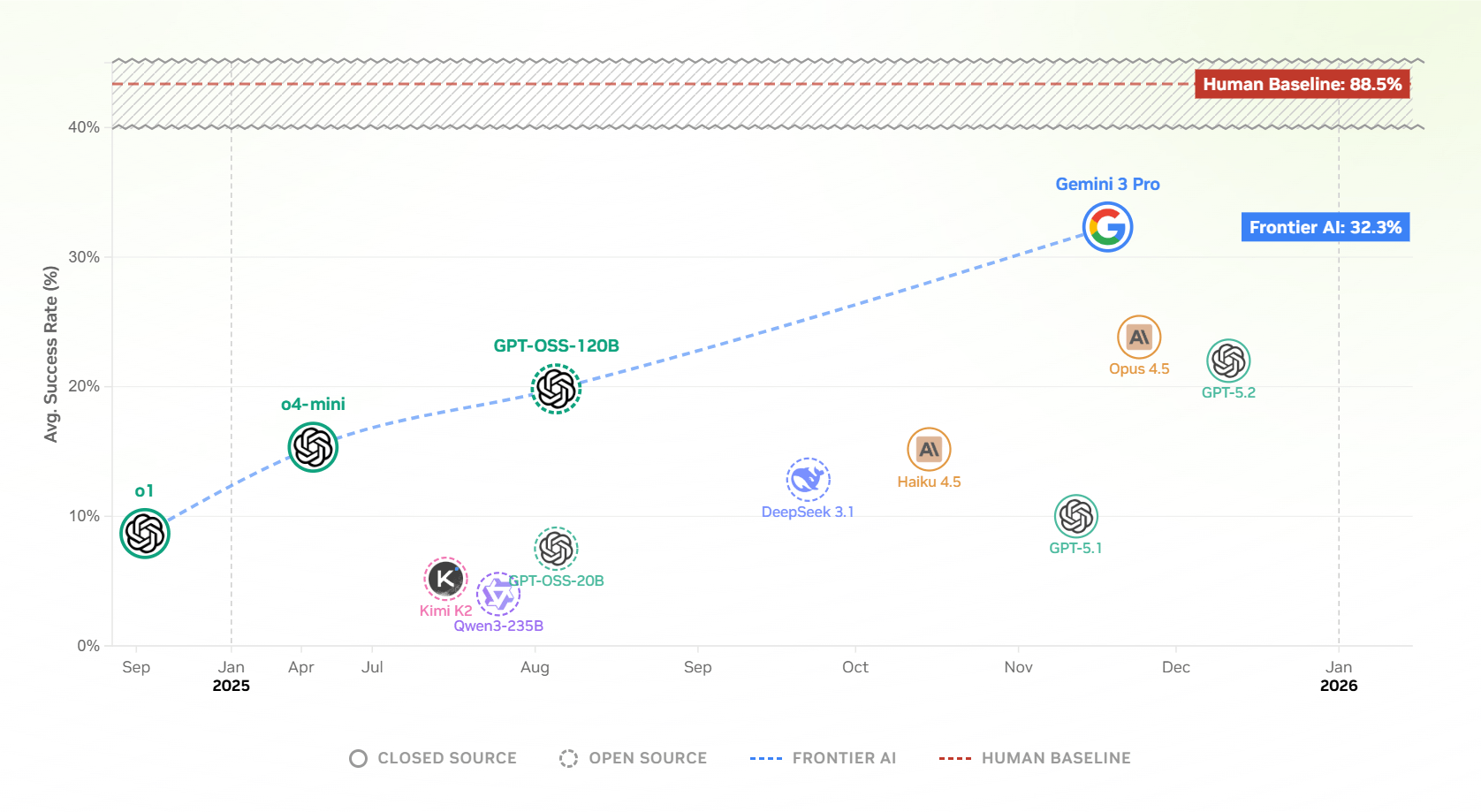
Die Leistung schwankt stark, je nachdem, welche Bausteine den Modellen zur Verfügung stehen: Erhalten sie vorgefertigte Befehle wie "greife Objekt X und hebe es an", müssen sie nur noch die richtige Reihenfolge zusammensetzen. Werden diese Komfortfunktionen jedoch durch die darunterliegenden Einzelschritte ersetzt, also Bildsegmentierung, Tiefenbildverarbeitung, Greifplanung und inverse Kinematik, sinkt die Erfolgsrate drastisch. Die Modelle müssen dann eigenständig dutzende Zeilen Code korrekt kombinieren, wo vorher ein einzelner Funktionsaufruf genügte.
Direkte Bildeinspeisung verschlechtert die Leistung
Interessanterweise zeigt der Benchmark auch, dass die direkte Einspeisung von Kamerabildern in den Kontext der Modelle die Ergebnisse verschlechtert. Die Forschenden vermuten eine Lücke in der modalitätsübergreifenden Ausrichtung: Foundation Models seien selten darauf trainiert, gleichzeitig über Softwarecode und physische Roboterausführung zu schlussfolgern.
Besser funktioniert ein zwischengeschaltetes "Visual Differencing Module": Ein separates Bildsprachmodell beschreibt zunächst die Szene in Textform, extrahiert aufgabenrelevante Eigenschaften und schildert nach jedem Ausführungsschritt, was sich im Bild verändert hat und ob die Aufgabe erledigt ist. Dieser strukturierte Text dient dem Coding-Agenten dann als Grundlage für die nächste Codegenerierung. Das liefert durchgehend bessere Ergebnisse als reine Konsolenausgaben oder auch direkte Bildeingaben.
Trainingsfreier Agent erreicht menschliches Niveau
Auf Basis dieser Erkenntnisse entwickelten die Forschenden CaP-Agent0, ein trainingsfreies System aus drei Bausteinen: Erstens das beschriebene Visual Differencing Module, das nach jedem Schritt eine textuelle Lagebeschreibung liefert. Zweitens eine automatisch erzeugte Funktionsbibliothek: Das System sammelt Hilfsfunktionen aus erfolgreichen Durchläufen, etwa zur Koordinatentransformation oder zur Filterung von Greifposen, und stellt sie für künftige Aufgaben bereit. Drittens parallele Codegenerierung: Neun Lösungsvorschläge werden gleichzeitig erzeugt, entweder von einem einzelnen Modell bei verschiedenen Temperaturen oder verteilt auf Gemini-3-Pro, GPT-5.2 und Claude Opus 4.5. Ein übergeordneter Agent fasst die Vorschläge dann zu einer endgültigen Lösung zusammen. Einige dieser Ideen fanden sich bereits in Voyager, einem Minecraft-Agenten aus dem Team um Co-Autor Jim Fan, Direktor für Robotik bei Nvidia und Co-Lead des dort ansässigen GEAR Labs, das auch für Nvidias Gr00t-Modelle verantwortlich ist.
Das Modell zerlegt eine übergeordnete Aufgabe (Fahrstuhl nach unten nehmen) automatisch in Teilschritte (Knopf drücken, Arm absenken, in den Fahrstuhl fahren). Dabei nutzt es Programmier- und Mathematikwerkzeuge um das Knopfdrücken auszuführen. | Video: https://capgym.github.io/
Trotz ausschließlicher Nutzung einfacher Grundbausteine erreicht CaP-Agent0 so auf vier von sieben Aufgaben Erfolgsraten, die mit menschlich geschriebenem Code vergleichbar sind oder diesen übertreffen. Die Forschenden testeten das System auch gegen trainierte Vision-Language-Action-Modelle (VLAs), die Roboter nicht per Code, sondern durch gelernte Bewegungsmuster aus großen Demonstrationsdatensätzen steuern. Auf dem LIBERO-PRO-Benchmark, der Aufgaben mit veränderten Objektpositionen und umformulierten Anweisungen prüft, schnitt CaP-Agent0 bei Positionsänderungen ähnlich gut ab wie das VLA-Modell π0.5 von Physical Intelligence. Bei veränderten Aufgabenbeschreibungen war CaP-Agent0 laut dem Team deutlich robuster, weil es Anweisungen direkt interpretiert, statt auf eine bestimmte Trainingsverteilung angewiesen zu sein.
Bestärkendes Lernen verbessert kleines Modell
Neben dem trainingsfreien CaP-Agent0 stellt das Framework auch CaP-RL vor, eine Methode, um Sprachmodelle durch bestärkendes Lernen gezielt für die Robotersteuerung zu verbessern. Dabei wird das Modell mit Belohnungssignalen aus der Physiksimulation trainiert: Erzeugt der generierte Code eine erfolgreiche Roboterbewegung, erhält das Modell eine positive Rückmeldung.
Ein so trainiertes Qwen2.5-Coder-7B steigerte seine Erfolgsrate beim Würfelstapeln von 4 auf 44 Prozent in der Simulation. Auf einem echten Franka-Roboter erreichte dasselbe Modell ohne weitere Anpassung 76 Prozent, weil es über abstrakte Programmierschnittstellen statt über Kamerabilder optimiert wird. Der visuelle Unterschied zwischen Simulation und Realität spielt dadurch kaum eine Rolle.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.