KI-Radar #1: Vom Chatbot zum Aufgabenlöser – der Stand bei KI-Agenten 2026

Liebe Leserinnen und Leser,
willkommen zur ersten Ausgabe des KI-Radars. Wir starten dort, wo die Industrie gerade ihren Kipppunkt erreicht: bei KI-Agenten. Buzzword oder Paradigmenwechsel?
Was „Agent“ wirklich bedeutet (und was nicht)
Der Begriff KI-Agent wird inflationär missbraucht. Microsoft etwa benannte bei Copilot monatelang glorifizierte Prompt-Templates als „Agenten“. Marketing, das die tatsächlichen Fähigkeiten der Technologie verschleiert.
Die etymologische Wurzel liegt im englischen agency – Handlungsfähigkeit. Der Unterschied zu klassischen LLM-Anwendungen: Agenten orchestrieren ihre Prozesse dynamisch und autonom, nutzen dabei Werkzeuge wie Websuche, Dateisuche und Codeausführung, allerdings innerhalb definierter Leitplanken. Sie machen ihren Lösungsweg transparent und fordern bei Bedarf Nutzerfeedback ein.
| Chatbot | Agent |
|---|---|
| Reagiert auf Eingaben | Zerlegt Anfragen in Teilschritte |
| Nutzt Werkzeuge auf Anweisung | Wählt Werkzeuge eigenständig |
| Mensch steuert jeden Schritt | System steuert autonom innerhalb definierter Leitplanken |
| Blackbox-Antworten | Transparenter Lösungsweg |
Das KI-Labor Anthropic definiert Agenten wie folgt:
Agenten beginnen ihre Arbeit entweder mit einem Befehl des Menschen oder durch eine interaktive Diskussion mit ihm. Sobald die Aufgabe klar ist, planen Agenten und arbeiten eigenständig weiter – sie können dabei zum Menschen zurückkehren, um zusätzliche Informationen oder eine Einschätzung einzuholen. Während der Ausführung ist es entscheidend, dass Agenten in jedem Schritt „Ground Truth“ aus der Umgebung gewinnen (etwa durch Ergebnisse von Tool-Aufrufen oder Codeausführungen), um ihren Fortschritt zu beurteilen. Agenten können dann an Kontrollpunkten oder beim Auftreten von Blockern pausieren, um menschliches Feedback einzuholen. Die Aufgabe endet oft mit der Fertigstellung; üblich sind aber auch Abbruchbedingungen (zum Beispiel eine maximale Anzahl an Iterationen), um die Kontrolle zu behalten.
Anthropic
Automatisierung vs. Agenten: Die schleichende Agentisierung generativer KI
Häufig werden Automatisierung und Agenten gleichgesetzt. Das ist nicht völlig verkehrt, da auch Agenten letztlich einen Aspekt der Automatisierung beinhalten. Aber es ist ungenau. Automatisierung meint das exakte Abarbeiten eines vorgegebenen Plans, eines Workflows. Ein Agent hingegen entwirft diesen Plan selbst und arbeitet ihn anschließend ab.
Zugespitzt formuliert: Agentische KI ist der Versuch, die Automatisierung zu automatisieren.
Alles wird agentisch
2025 wurde als das Jahr der KI-Agenten ausgerufen. Ende des Jahres dann die Ernüchterung in sozialen und redaktionellen Medien: Die agentische Revolution sei ausgeblieben. Menschen interagieren ja immer noch hauptsächlich mit KI-Modellen, nicht mit autonomen Agenten.
Unser Eindruck ist, dass diese Einschätzung etwas Entscheidendes übersieht: Die Modelle selbst haben sich verändert. Ihnen wurden agentische Fähigkeiten antrainiert. GPT 5.2 Thinking, Claude Opus 4.5, Gemini 3 Pro – sie alle generieren in ihren Reasoning Traces, also ihren Gedankenketten, Pläne, denen sie folgen, die sie anpassen, und versuchen, ihr Ziel autonom durch Werkzeugeinsatz zu erreichen.
Die Agentisierung kam also nicht als eigenständiges Produkt. Sie sickerte in die bestehenden Modelle ein. Wer heute ein aktuelles Reasoning-Sprachmodell nutzt, arbeitet bereits mit einem Agenten, auch wenn es sich nicht so anfühlt.
Das folgende Demovideo macht das deutlich: Das agentische KI-Modell o3 hat die Aufgabe, ein Bild zu analysieren. Dafür erkennt es Inhalte auf dem Bild, durchsucht das Web zu diesen, zoomt in das Bild hinein für eine genauere Analyse (dafür schreibt es eigenständig Code), sucht dann erneut im Web und antwortet erst dann. Kein Mensch hat diese Schritte vorgegeben. Das Modell hat seinen eigenen Plan entwickelt und ausgeführt.
KI-Agenten sind also weit verbreitet: Jeder, der regelmäßig mit den neuesten KI-Modellen interagiert, nutzt bereits agentische KI. Die Technologie ist längst im Alltag angekommen. Blickt man auf so entscheidende Releases wie o3 und agentische Funktionen wie Deep Research, war die Prognose, dass 2025 das Jahr der agentischen KI wird, durchaus korrekt. Der normale Nutzer bemerkte das vor allem daran, dass die Modelle komplexere Aufgaben besser lösten. Die Revolution fand statt, sie war nur leiser als erwartet.
Das macht Automatisierung nicht überflüssig. Im Gegenteil: Sie legt sich wie ein Rahmen um agentische KI-Systeme, um deren Verhalten gezielt zu steuern. Sinnvoll ist das immer dann, wenn man die Fähigkeiten der Modelle lenken möchte, anstatt alle Entscheidungen den Modellen zu überlassen. Eine zentrale Motivation dafür ist Verlässlichkeit. Agenten sind mächtig, aber nicht immer vorhersehbar. Wer Kontrolle benötigt, kombiniert agentische Fähigkeiten mit klassischer Automatisierung.
| Assistent | Automatisierung | KI-Agent |
|---|---|---|
| Reagiert auf Eingaben | Führt vordefinierte Workflows aus | Zerlegt Ziele eigenständig, arbeitet iterativ |
| Mensch steuert jeden Schritt | Läuft automatisch durch | Autonom, fragt bei Unsicherheit nach |
| Keine Prozessplanung | Folgt exakt dem Ablauf | Plant innerhalb von Grenzen |
| Mensch kopiert zwischen Tools | Integriert nach festem Schema | Wählt Werkzeuge selbstständig |
| Schnell, flexibel für Text | Zuverlässig bei Routineprozessen | Flexibel bei komplexen Aufgaben |
| Ohne klare Anweisungen inkonsistent | Scheitert bei Ausnahmen | Fehlerrisiko ohne Leitplanken |
| Entwürfe, Q&A, Brainstorming | Datensync, Routineaufgaben | Rechercheketten, mehrstufige Workflows |
Teil einer solchen Strategie kann es sein, mehrere agentische KI-Modelle miteinander zu vernetzen. So wird der KI-Prozess kleinteiliger steuerbar und transparenter. Man gibt nicht einem Agenten die volle Verantwortung, sondern orchestriert mehrere spezialisierte Agenten, die sich gegenseitig überprüfen und ergänzen.
Agentische KI-Systeme: Harness Engineering
In der Praxis entscheidet nicht nur das Modell über Erfolg oder Misserfolg, sondern die Kombination aus Modell, Werkzeugen und dem technischen Gerüst darum herum. Je länger ein Agent arbeitet, desto weniger reicht ein Prompt plus Werkzeugliste.
Stattdessen braucht es einen Harness: ein systematisches Gerüst aus Code, Speicher, Werkzeugschnittstellen und Regeln.
Das Modell generiert Pläne, Werkzeugaufrufe und Antworten, kennt aber keine echte Ausführung. Die Werkzeuge sind konkrete Fähigkeiten wie Dateizugriff, Shell-Befehle oder Git-Operationen.
Der Harness ist der entscheidende Teil: Er baut den Prompt zusammen, führt Werkzeugaufrufe aus, erzwingt Sicherheitsregeln und stellt die Kontinuität über Sessions hinweg her.
Die Grundstruktur: der Agent Loop
Im Kern folgen agentische Systeme fast immer demselben Ablauf, den OpenAI in seiner Dokumentation zu Codex CLI detailliert beschreibt.
Eine Eingabe kommt herein, der Harness baut daraus einen Prompt. Das Modell antwortet entweder mit einer finalen Antwort oder mit einem Werkzeugaufruf. Im zweiten Fall führt der Harness das Werkzeug aus, hängt das Ergebnis an den Kontext an und fragt das Modell erneut. Das wiederholt sich, bis das Modell eine Nutzerantwort liefert.
Der Prompt selbst ist ein Stapel aus Schichten: Systemregeln, Entwicklerregeln, Projektregeln, Nutzeranweisungen, Dialogverlauf und Werkzeugergebnisse.
Zusätzlich hängen viele Systeme Kontextdaten an: das aktuelle Arbeitsverzeichnis, relevante Dateien wie README oder Architekturdokumentation, Werkzeugdefinitionen und Umgebungsinformationen wie Sandbox-Modus oder Netzwerkzugriff.
Der Harness muss diese Schichten stabil zusammenbauen, sonst driftet der Agent oder vergisst Regeln.
Das Kontextfenster als knappe Ressource
Jedes Modell hat ein begrenztes Kontextfenster. Da der Prompt mit jedem Werkzeugaufruf wächst, läuft das System ohne Gegenmaßnahmen in Probleme: Der Agent vergisst frühe Entscheidungen, widerspricht sich oder bricht Implementierungen mittendrin ab.
Mögliche Lösungen: Prompt Caching nutzt identische Prompt-Anfänge für effizientere Anfragen. Komprimierung fasst alte Details zusammen und ersetzt die ausführliche Historie durch kompaktere Repräsentationen. Dabei können jedoch Informationen verloren gehen.
Gedächtnis über Sessions hinweg
Ein großes Problem langer Arbeiten ist zudem, dass jede neue Session ohne Gedächtnis startet. Ohne Gegenmaßnahmen versuchen Agenten zu viel auf einmal und hinterlassen halbfertige Arbeit, oder spätere Sessions erklären die Aufgabe voreilig für abgeschlossen.
Anthropics Claude Code löst das durch explizite Übergabe-Artefakte: Ein initialisierender Agent richtet eine Fortschrittsdatei und einen ersten Git-Commit ein. Nachfolgende Agenten arbeiten inkrementell und aktualisieren diese Artefakte. Die Kontinuität entsteht nicht im Modell, sondern in Dateien, die neue Sessions schnell erfassen können.
Claude Code nutzt dafür typischerweise CLAUDE.md-Dateien für Instruktionen und Kontext, die beim Start geladen werden. Diese können global im Home-Verzeichnis liegen, projektweit im Repository oder lokal für private Einstellungen. Dazu kommen optional Subagenten als separate Dateien für arbeitsteilige Rollen.
Projektspezifische Instruktionen als offener Standard
OpenAI verfolgt mit Codex CLI einen ähnlichen Ansatz. AGENTS.md-Dateien im Projekt fließen automatisch in den Prompt ein und enthalten Coding-Standards, Architekturprinzipien oder Testing-Regeln. Das Format hat sich zu einem offenen Standard entwickelt, der von OpenAI, Google Jules und Cursor unterstützt und von der Linux Foundation verwaltet wird.
Zusätzlich setzt der Harness Sicherheitsregeln durch: welche Verzeichnisse beschreibbar sind, ob Netzwerkzugriff erlaubt ist, wann Nutzergenehmigung nötig ist. Das Modell darf wünschen, der Harness entscheidet, ob es darf.
Ein gut gebautes Gerüst führt den Agenten zu robustem Verhalten: klare Zwischenschritte, stabile Regeln, anschlussfähige Übergaben, Sicherheit durch Sandbox und Genehmigungspflichten. So werden typische Probleme abgefedert: schleichender Kontextverlust, Endlosschleifen, halluzinierte Annahmen und voreiliges Fertigmelden.
| Aspekt | Mensch + Sprachmodell | Mensch + KI‑Agent |
|---|---|---|
| Grundprinzip | Dialog/Prompt → Modell erzeugt Antwort/Entwurf | Auftrag/Ziel → Agent plant Schritte, nutzt Tools, iteriert, liefert Ergebnis + Nachweise |
| Rolle der KI | Generator & Sparringspartner (Text, Ideen, Struktur, Code) | Ausführender Problemlöser (Task-Management, Rechercheketten, Tool-Aktionen) |
| Intention (Wer definiert was?) | Mensch definiert Ziel meist promptweise (Aufgabe für Aufgabe) | Mensch definiert Outcome + Erfolgskriterien; Agent leitet Teilaufgaben daraus ab |
| Steuerung | Prompting, manuelle Iterationen, Copy/Paste zwischen Tools | Orchestrierung: Regeln/Policies, Tool-Rechte, Budgets/Timeouts, Checkpoints, Monitoring |
| Verantwortung | Mensch prüft/entscheidet am Ende (Fakten, Recht, Marke) | Mensch setzt Leitplanken + Freigaben; Agent dokumentiert, eskaliert bei Unsicherheit; finale Verantwortung bleibt beim Menschen |
| Input | Prompt + ggf. bereitgestellte Quellen/Notizen | Mission/Briefing + Constraints + Zugriff auf Systeme/Quellen + Definition of Done |
| Produktion | Meist einzelschrittig (Antworten/Entwürfe), wenig Prozesskontinuität | Mehrstufig: planen → ausführen → prüfen → verbessern → ggf. rückfragen/eskalieren |
| Tool-/Systemnutzung | Optional, aber i. d. R. vom Menschen ausgeführt (Suche, Tabellen, CMS) | Agent nutzt Tools selbstständig innerhalb von Rechten (Websuche, DB, CMS, Tickets, Skripte etc.) |
| Output | Entwurf/Variante/Antwort (oft ohne belastbare Belege) | Ergebnis + Varianten + Quellen/Logs + offene Punkte + nächste Schritte (auditierbarer) |
| Typische Stärken | Schnelle Texterstellung, Ideen, Formulierungen, Zusammenfassungen | Wiederholbare Workflows, Recherche/Analyseketten, teilautomatisierte Prozesse, „Arbeitspakete“ |
| Typische Risiken | Halluzinationen, fehlende Quellen, hoher Nacharbeitsanteil | Falsche Tool-Aktionen/Overreach, Berechtigungs-/Compliance-Risiken → braucht Guardrails & Freigaben |
Ein konkretes Praxisbeispiel dafür, wie wichtig „Harness Engineering“ und sauberer Kontext sind, beschreibt OpenAI mit seinem internen Data Agent: ein Tool, das Mitarbeitenden hilft, in Minuten statt Tagen zu belastbaren Datenantworten zu kommen. Entscheidend ist dabei die Umgebung um das Modell herum: Der Agent nutzt mehrere Kontextschichten (Tabellen-Metadaten und Query-Historie, menschliche Anmerkungen, Code‑basierte Erklärungen der Datentabellen, internes Wissen aus Slack/Docs/Notion, Memory und Live‑Abfragen) und arbeitet gleichzeitig mit strikter Rechteprüfung und nachvollziehbaren Ergebnissen.
Vom Chatbot zum Aufgabenlöser
Wie zuvor beschrieben übernehmen KI-Agenten eigenständig mehrstufige Aufgaben und koordinieren komplexe Arbeitsabläufe. Im Gegensatz zu klassischen Chatbots, die auf einzelne Anfragen reagieren und isolierte Antworten liefern. Das Ziel dahinter ist ambitioniert: die Automatisierung weiter Teile der Wissensarbeit.
Nur wenn das gelingt, können sich die enormen Investitionen in die Technologie bezahlt machen. OpenAI etwa möchte KI-Agenten zu Preisen verkaufen, die dem Gehalt mehrerer Vollzeitkräfte entsprechen, oder Teile der wissenschaftlichen Forschung massiv übernehmen und beschleunigen. Agenten sind wie Industrieroboter, aber für den Computer. Das Narrativ „Mensch und Maschine arbeiten zusammen“ wird nur so lange halten, wie die Systeme nicht eigenständig bessere Lösungen schaffen.
Laut einer umfassenden Studie der UC Berkeley, Stanford University, IBM Research und weiterer Institutionen („Measuring Agents in Production“) aus dem Dezember 2025 sind Produktivitäts- und Effizienzgewinne der wichtigste Grund für den Einsatz von Agenten. Etwa in Bereichen wie Versicherungs-, HR- oder Analyse-Workflows. Die Ergebnisse basieren auf einer Umfrage unter 306 Praktikerinnen und Praktikern sowie 20 Tiefeninterviews mit Teams, deren Agenten bereits im Einsatz sind.
Neue Benchmarks: Arbeitszeit und Effizienz
Organisationen wie METR (Model Evaluation and Threat Research) entwickeln Benchmarks, die speziell die Fähigkeit von KI-Systemen messen, längere, zusammenhängende Aufgaben autonom zu bearbeiten. Diese Evaluierungen fokussieren sich auf Planungsfähigkeit, Fehlerkorrektur und die effiziente Nutzung von Arbeitszeit. Metriken, die für die Automatisierung von Wissensarbeit entscheidend sind.
Aktuelle Ergebnisse zeigen deutliche Fortschritte: Laut METR-Messungen können führende KI-Modelle mittlerweile Aufgaben bewältigen, für die ein menschlicher Experte etwa 50 Minuten benötigen würde. Ein signifikanter Sprung gegenüber früheren Modellgenerationen. Die Leistungsfähigkeit verdoppelt sich dabei etwa alle sieben Monate, gemessen an der Komplexität der lösbaren Aufgaben. Die Kurve zeigt steil nach oben.
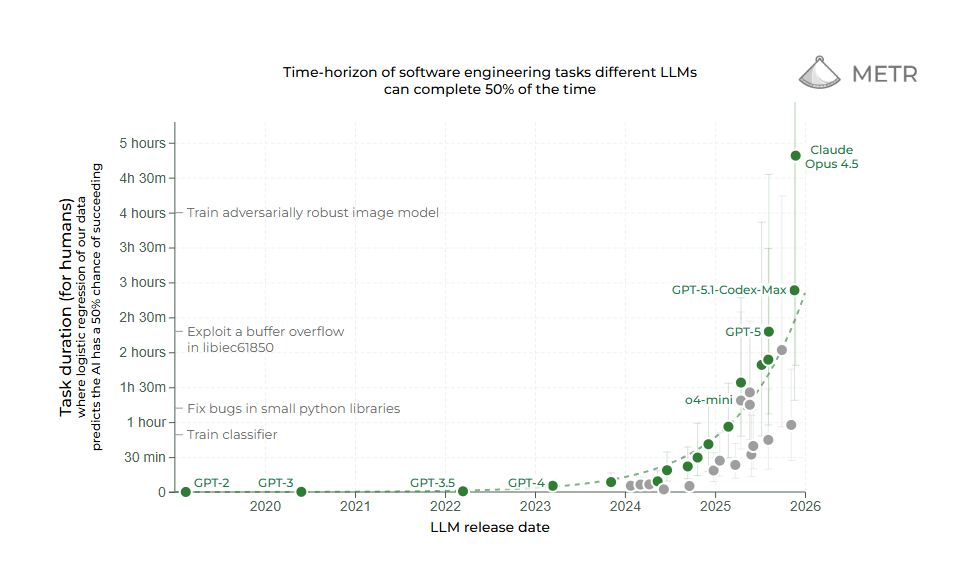
Allerdings offenbaren die Benchmarks auch klare Grenzen: Bei Aufgaben, die mehrere Stunden konzentrierter menschlicher Arbeit erfordern, sinkt die Erfolgsrate der KI-Systeme drastisch. Besonders bei Aufgaben, die iteratives Problemlösen, das Erkennen und Korrigieren eigener Fehler oder das Navigieren unerwarteter Hindernisse erfordern, zeigen sich die Schwächen aktueller Agenten. Die Modelle neigen dazu, bei längeren Aufgabenketten den Kontext zu verlieren oder sich in Sackgassen festzufahren. Die letzten Meter zur echten Autonomie sind die schwersten.
Zuverlässigkeit und Sicherheit: Die Achillesfersen agentischer KI
Das Hauptproblem bei der Implementierung agentischer KI bleibt die Zuverlässigkeit. Hinzu kommt Cybersecurity, hier insbesondere die allgegenwärtigen Prompt Injections.
Da KI-Modelle nicht deterministisch arbeiten, ist es schwierig, ihre Korrektheit sicherzustellen. In einer Rangfrage zu Entwicklungshürden nennen die Befragten „Core Technical Performance“, also Robustheit, Zuverlässigkeit, Skalierbarkeit, Latenz und Ressourceneffizienz, am häufigsten als größte Herausforderung. Das Modell kann brillant sein, aber wenn es in einem von zehn Fällen versagt, ist es für kritische Prozesse unbrauchbar.
Auch Multi-Agenten-Systeme, also das kleinschrittige Aufteilen von Aufgaben auf mehrere Agenten, um Steuerbarkeit und Transparenz zu erhöhen, sind hier keine Allzwecklösung. Eine aktuelle Studie von Google Research, Google DeepMind und MIT mit 180 Experimenten zeigt: Multi-Agent-Performance schwankt je nach Aufgabe zwischen deutlicher Verbesserung und massiver Verschlechterung.
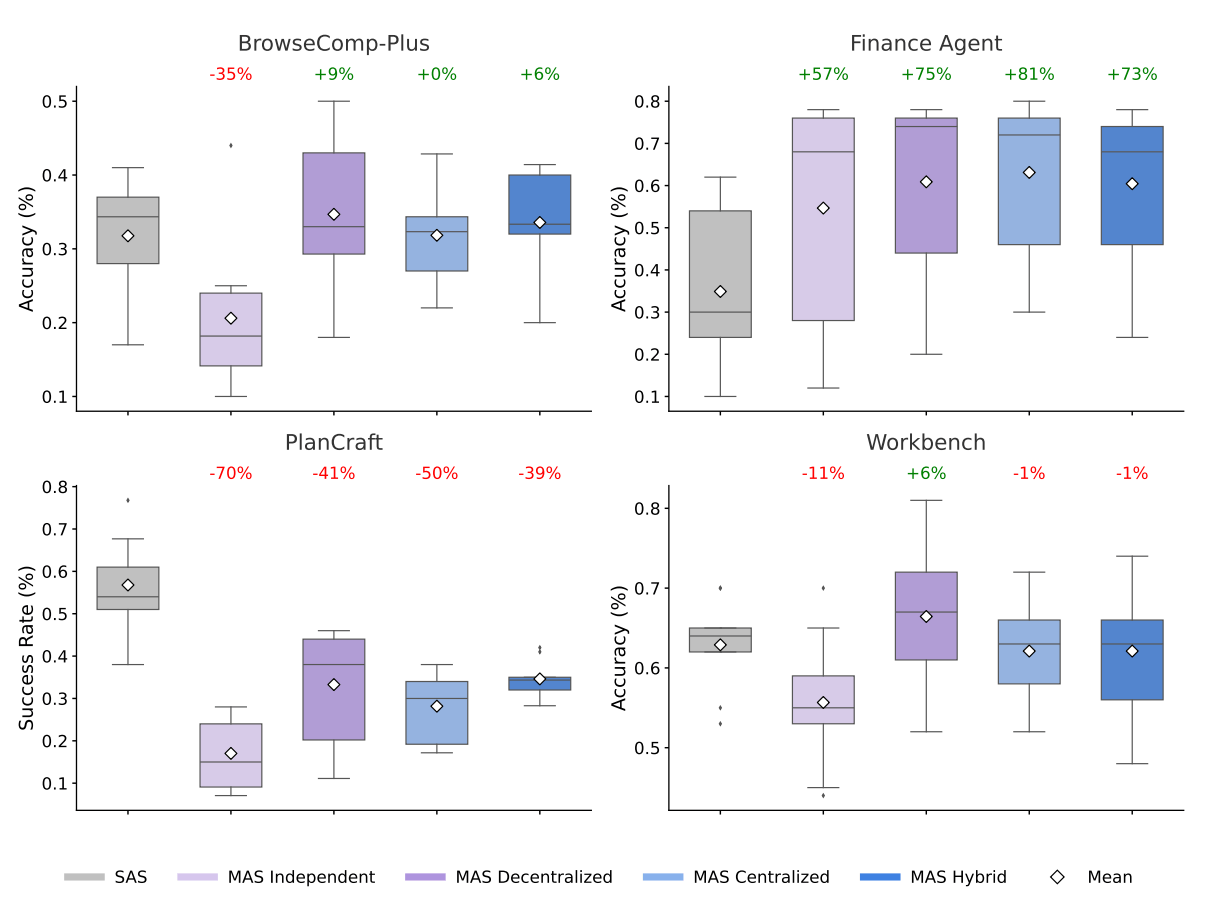
Wenn jeder Schritt den Zustand verändert, kann Koordination den Kontext zerhacken. Die Faustregel aus der Studie: Ab etwa 45 Prozent Single-Agent-Erfolgsquote lohnt sich Koordination oft nicht mehr. Mehr Agenten bedeutet nicht automatisch bessere Ergebnisse. Weiter unten werden wir einen genaueren Blick auf die Studie werfen.
Bei der Cybersecurity agentischer KI-Systeme stellt Prompt Injection die zentrale und bislang ungelöste Bedrohung dar. Diese Schwachstelle ist technischer Natur und liegt in der Architektur der Sprachmodelle selbst: Sie können nicht zuverlässig zwischen legitimen Nutzeranweisungen und bösartigen injizierten Befehlen unterscheiden. Das Problem ist seit mindestens GPT 3 bekannt und konnte trotz vieler Versuche bis heute nicht beseitigt werden.
Eine umfassende Red-Teaming-Studie von Mitte August 2025 mit fast 2.000 Teilnehmenden und 1,8 Millionen Angriffen auf KI-Agenten zeigt das Ausmaß der Sicherheitslücke: Über 62.000 Versuche führten erfolgreich zu Richtlinienverletzungen wie unbefugtem Datenzugriff, illegalen Finanzaktionen und Verstößen gegen regulatorische Vorgaben. Die Studie erreichte eine 100-prozentige Verhaltenserfolgsrate. Das heißt: Jeder Agent ließ sich kompromittieren.
Auch Zahlen von Anthropic zu Opus 4.5, dem Motor hinter dem Erfolg von Tools wie Claude Code, zeigen, dass das Modell bei zehn Angriffsversuchen in rund 30 Prozent der Fälle per Prompt Injection geknackt werden kann. Aus Perspektive der Cybersecurity sind das haarsträubende Resultate: eine Fehlerquote, die in sicherheitskritischen Anwendungen schlicht inakzeptabel ist.
Mitigieren lassen sich diese Risiken derzeit nur, indem man die Leistungsfähigkeit der Systeme bewusst begrenzt: durch strengere Systemvorgaben, restriktive Zugangsregeln, eingeschränkte Werkzeugnutzung oder die Einführung zusätzlicher Bestätigungsschritte durch Menschen.
Das bedeutet im Umkehrschluss: Je autonomer und leistungsfähiger ein KI-Agent agieren soll, desto größer wird seine Angriffsfläche. Unternehmen stehen damit vor einem fundamentalen Zielkonflikt zwischen Produktivitätsgewinn und Sicherheitsrisiko. Wer alles automatisieren will, öffnet Türen.
Hype trifft auf Realität
Statt vollautonomer „AI Employees“ dominieren daher laut der MAD-Studie noch einfache, stark begrenzte Systeme. Diese arbeiten mit Frontier-Sprachmodellen, teils sehr langen Prompts und enger menschlicher Kontrolle. Aufgrund der agentischen Fähigkeiten der Modelle haben KI-Agenten also auch hier Einzug gehalten. Aber es sind relativ einfache Implementierungen, keine komplexen, mehrstufigen KI-Systeme in Kombination mit Automatisierung.
Einfach gesagt: Es ist weiterhin viel menschlicher Input notwendig. Vor allem die Interaktion zwischen Agenten oder zwischen Agenten und Software ist ausbaufähig. Fast alle Agenten berichten an Menschen. Die Vision vom autonomen digitalen Kollegen bleibt vorerst genau das: eine Vision.
Die Next Frontier: Hunderte Agenten, RL und die neue Startup-Landschaft
Agentenschwärme als Lösung für komplexe Probleme?
Wir haben beschrieben, wie Anthropic mit Claude Code ein durchdacht konstruiertes Rahmenwerk gebaut hat, also das System um das Modell herum. Initialisierende Agenten, Unteragenten, präzise Funktionsaufrufe: alles darauf ausgelegt, Probleme wie den schleichenden Verlust von Kontextinformationen und sich festfahrende Agenten zu umgehen.
Die Agentik-Studie, auf die wir uns oben beziehen, zeichnet aber ein deutlich differenzierteres Bild: Systeme mit mehreren KI-Agenten bringen nicht automatisch einen Mehrwert. In vielen Szenarien schneiden sie sogar schlechter ab als ein einzelner leistungsstarker Agent mit Werkzeugen.
Sie helfen vor allem dann, wenn drei Bedingungen erfüllt sind:
(1) Die Arbeit lässt sich in weitgehend unabhängige Teilaufgaben zerlegen, die parallel bearbeitet werden können.
(2) Für diese Teilaufgaben gibt es gute, automatisierbare Feedback-Signale (Tests, Zahlen, externe Validatoren).
(3) Der Single-Agent-Baseline ist noch nicht „zu gut“. Ab etwa 45 % Erfolgsrate beim Einzelagenten kippen die Skaleneffekte, weil der Aufwand für Koordination und die Verstärkung von Fehlern die Gewinne auffressen.
Im Finanz-Benchmark der Studie sieht man das deutlich: Eine Rechercheaufgabe wird in Nachrichtenanalyse, SEC-Filings, Kennzahlen und Risikoszenarien zerlegt. Mehrere spezialisierte Agenten arbeiten parallel, ein zentraler Koordinator prüft und integriert die Ergebnisse. Am Ende steht ein Leistungsplus von rund 80 % gegenüber dem besten Einzelagenten. Das funktioniert, weil sich Finanzanalysen in unabhängige Teilaufgaben zerlegen lassen: Umsatztrends, Kostenstrukturen und Marktvergleiche können getrennt analysiert und dann zusammengeführt werden.
Bei stark aufeinander aufbauenden Aufgaben wie Planung oder schrittweisem Vorgehen passiert das Gegenteil: Alle Varianten mit mehreren Agenten verschlechtern die Leistung um 40 bis 70 %. Der Grund: Planungsaufgaben erfordern eine streng sequenzielle Abfolge, bei der jede Aktion den Zustand verändert, auf den alle nachfolgenden Aktionen aufbauen. Wenn mehrere Agenten solche Aufgaben bearbeiten, wird eine zusammenhängende Kette künstlich zerteilt. Das erzeugt erheblichen Koordinationsaufwand, der das Rechenbudget für die eigentliche Problemlösung aufbraucht, ohne Mehrwert zu liefern.
Überträgt man das auf Softwareentwicklung, legt die Studie nahe: Systeme mit mehreren Agenten helfen vor allem bei großen, gut zerlegbaren Codebasen, bei denen unabhängige Teilaufgaben parallel bearbeitet werden können. Das gilt etwa für Migrationswellen über Hunderte Dateien, parallele Performance-Experimente oder recherchelastige Aufgaben.
Gleichzeitig warnt die Studie vor zu viel Agentik in genau den Situationen, in denen Coding schon heute gut mit einem starken Einzelagenten funktioniert: wenn die Aufgabe im Kern sequenziell ist (ein heikler Refactor, eine komplexe Pipeline) oder der Einzelagent bereits sehr hohe Trefferquoten erreicht. Besonders problematisch wird es, wenn einzelne Teilaufgaben selbst viele Werkzeugaufrufe erfordern. Dann frisst der Koordinationsaufwand zwischen den Agenten das Rechenbudget auf, das jeder Agent für seine eigene Arbeit bräuchte.
Cursor und skalierte Agenten
Cursor, der KI-gestützte Code-Editor, hat einen Harness für Agenten gebaut und damit ein zum Thema passendes Experiment gefahren: Bis zu 2.000 Coding-Agents arbeiteten über fast eine Woche parallel an einem gemeinsamen Projekt. Über alle Versuche hinweg flossen dabei laut Cursor Milliarden bis Billionen Tokens durch das System. Als Vorzeigeprojekt wählte das Team einen Webbrowser. Nicht, weil sie den „Chrome-Killer“ bauen wollten, sondern bewusst als extrem großes, aber klar spezifiziertes Ziel für die Erforschung von Agenten-Koordination: Die Agents sollten eine neue Rendering-Engine in Rust entwickeln, mit HTML-Parsing, CSS-Cascade, Layout, Text-Shaping, Painting und JavaScript-VM. Am Ende standen laut Blogpost über eine Million Zeilen Code, der CEO sprach auf X sogar von drei Millionen.
Ein Blick ins GitHub-Repo zeichnet ein komplexeres Bild: FastRender ist ein experimenteller Prototyp, der stark auf bestehenden Komponenten aufbaut. Dazu gehören html5ever und cssparser aus dem Servo-Projekt (einer Open-Source-Browser-Engine) sowie eine JavaScript-Engine, die Wilson Lin, der verantwortliche Entwickler bei Cursor, bereits in einem separaten Agenten-Experiment-Projekt entwickelt hatte.
Im Interview mit Simon Willison räumte Lin ein, dass die Agenten diese Abhängigkeiten selbst ausgewählt haben, weil er in seinen Anweisungen nicht explizit vorgegeben hatte, was sie selbst implementieren sollen.
Teile des Codes ähneln zudem stark bestehenden Servo-Implementierungen, die Codebasis ist laut Entwicklern schwer zu durchdringen, und lange Zeit ließ sich das Projekt auf vielen Systemen nicht kompilieren.
In der Entwickler-Community hat das zu heftiger Kritik geführt. Kommentatoren sprechen von „KI-Slop“ und werfen Cursor vor, das Ergebnis als autonom und von Grund auf erzeugten Browser zu verkaufen. In Wahrheit beruhe ein erheblicher Teil auf bestehenden Bibliotheken. Der Blog Pivot to AI fasst das zugespitzt als „Marketing-Stunt“ zusammen. Cursor selbst betont allerdings, dass FastRender nie als Produkt gedacht war, sondern als Forschungsprojekt zur Koordination von Agenten-Schwärmen.
Inzwischen zeigen Erfahrungsberichte, dass sich FastRender auf manchen Systemen tatsächlich bauen lässt und einfache Seiten wie Wikipedia oder CNN rudimentär darstellen kann. Allerdings als instabiler Prototyp, nicht als vollwertiger Browser.
Spannend ist, wie schnell eine Gegenbewegung entstand: Als Antwort auf die Kritik baute ein einzelner Entwickler (embedding-shapes) in drei Tagen gemeinsam mit einem einzigen Codex-Agenten einen deutlich kleineren Browser-Prototypen mit rund 20.000 Zeilen Rust.
Simon Willison bringt es in seinem Kommentar auf HackerNews auf den Punkt: Er hatte FastRender zunächst als erstes echtes Beispiel gesehen, bei dem Tausende Agenten etwas leisten, was anders nicht geht. Bis der Ein-Agent-Ansatz zeigte, dass ein starker Einzelagent plus ein erfahrener Mensch einen ähnlichen Problemraum ohne Agentenschwarm erschließen kann.
Für die Debatte um agentische KI ist das lehrreich: Das Cursor-Experiment zeigt, wie schwierig es ist, die Leistung Tausender Agents über viele Tage hinweg zu kontrollieren, zu bewerten und vor allem zu verstehen. Die Agentik-Studie liefert dazu einen möglichen theoretischen Rahmen, auch wenn sie selbst nur Systeme mit bis zu neun Agenten untersucht hat: Aufgaben, die sich nur begrenzt in unabhängige Teilschritte zerlegen lassen, liegen genau in dem Bereich, in dem mehrere Agenten leicht mehr Koordinationsaufwand und Fehlerverstärkung erzeugen als echten Mehrwert. Bei Tausenden Agenten über Tage hinweg dürften diese Effekte noch deutlich stärker ausfallen.
Das „Ein Mensch plus ein Agent“-Projekt legt nahe, dass ein gut gestalteter Rahmen, klare Spezifikationen und menschliche Steuerung oft mehr bewirken als ein Agentenschwarm mit riesigem Token-Budget. Systeme mit vielen Agenten sind damit kein Allheilmittel, sondern ein Spezialwerkzeug für bestimmte Problemklassen.
Dazu kommt die Frage der Wirtschaftlichkeit: Bei Milliarden bis Billionen Tokens dürften die Kosten für das FastRender-Experiment im hohen fünf- bis sechsstelligen Bereich liegen, genaue Zahlen hat Cursor nicht veröffentlicht. Dem gegenüber steht embedding-shapes mit einem Bruchteil der Ressourcen.
Die beiden Projekte sind natürlich nicht direkt vergleichbar: FastRender hatte breitere Ambitionen (eigene JavaScript-Engine, mehr Features), delegierte aber viel an bestehende Bibliotheken. Die Grundfunktionalität, einfache Webseiten rudimentär darzustellen, erreichten aber beide.
Die Agentik-Studie stützt dieses Muster quantitativ: Einzelagenten erzielen dort pro 1.000 Tokens bis zu fünfmal mehr erfolgreiche Aufgaben als die komplexesten Architekturen mit mehreren Agenten. Wer also nicht primär Grundlagenforschung betreibt, sondern robuste Ergebnisse unter Kostendruck braucht, fährt in vielen Fällen mit einem starken Einzelagenten plus menschlicher Steuerung günstiger.
Was Cursor gelernt hat
Interessant ist vor allem, was Cursor dabei gelernt hat, denn es zeigt, wie sich Systeme mit mehreren Agenten sinnvoll einsetzen lassen und wo ihre Grenzen liegen.
Flache Hierarchien scheitern. Gleichberechtigte Agenten mit gemeinsamer Koordinationsdatei funktionierten nicht. 20 Agenten verlangsamten sich effektiv auf den Durchsatz von zwei bis drei. Ohne Hierarchie wurden Agenten risikoscheu: Sie machten kleine, sichere Änderungen, statt sich an schwierige Aufgaben zu wagen.
Das deckt sich mit der Agentik-Studie: Unabhängige Agenten ohne klaren zentralen Knoten verstärken Fehler am stärksten und schneiden bei aufeinander aufbauenden Aufgaben am schlechtesten ab.
Mehr Agenten allein lösen also nichts. Ohne Struktur dominieren Kommunikationskosten und Missverständnisse.
Rollentrennung funktioniert. Die Lösung, zu der Cursor kam, ähnelt dem, was Anthropic für Claude Code beschreibt und was die Agentik-Studie als „zentralisierte“ oder „hybride“ Architektur modelliert: Planner (planende Agenten) erstellen Aufgaben und können weitere Subplanner starten. Worker (ausführende Agenten) arbeiten die Aufgabenpakete ab. Am Ende eines Zyklus bewertet eine übergeordnete Instanz, ob weitergearbeitet oder umgesteuert werden soll.
Wilson Lin beschreibt im Interview, wie das bei FastRender aussah: Ein Planner kümmerte sich um CSS-Layout, ein anderer um Performance. Worker implementierten konkrete Funktionen. Tests und Compiler lieferten das Feedback.
Das passt zu den positiven Studienergebnissen im Finanzbereich: Wo sich Aufgaben sauber in Teilstränge mit eigenen Prüfmechanismen zerlegen lassen, kann eine solche Hierarchie tatsächlich den Durchsatz heben.
Weniger ist mehr. Eine zusätzliche Integrator-Rolle für umfassende Qualitätskontrolle schuf in Cursors Experiment mehr Probleme, als sie löste. Worker konnten viele Konflikte lokal selbst handhaben. Der Rahmen erlaubte bewusst etwas Spielraum: Temporäre Kompilierfehler waren akzeptiert, solange sie schnell wieder verschwanden und der Gesamtdurchsatz stimmte. Lin erklärte das im Interview so: Wenn man von jedem einzelnen Commit verlangt, dass er perfekt kompiliert, entsteht ein Engpass bei der Abstimmung zwischen Agenten. Stattdessen gab es eine stabile Fehlerrate, die sich nicht aufschaukelte, sondern nach wenigen Commits wieder korrigiert wurde.
Genau vor diesem Zuviel an Struktur warnt auch die Studie: Hybride, sehr komplexe Topologien verursachen hohe Koordinationskosten, vor allem wenn viele Werkzeugaufrufe nötig sind. Weniger Schichten, klarere Zuständigkeiten und einfache Eskalationspfade sind oft robuster als ein perfekt durchgeplanter, aber überladener Orchestrator.
Das funktioniert allerdings nur, wenn Fehler tatsächlich korrigiert werden. Die Kritik an FastRender bezieht sich darauf, dass dieser Mechanismus offenbar nicht durchgängig funktionierte.
Modellwahl macht einen Unterschied. In den Cursor-Experimenten zeigte sich, dass GPT-5.2 bei langen Aufgaben stabiler war als spezialisierte Coding-Modelle: weniger Abdriften vom eigentlichen Ziel, vollständigere Implementierungen über viele Zyklen.
Lin erklärt das damit, dass die Anweisungen für solche Systeme über reines Programmieren hinausgehen. Die Agenten müssen verstehen, wie sie eigenständig in einem Rahmenwerk operieren, wie sie ohne ständiges Nutzerfeedback arbeiten und wann sie aufhören sollen.
Die Studie beschreibt denselben Effekt abstrakter: Je höher die Basisfähigkeit des Modells, desto weniger holen zusätzliche Agenten noch heraus. Und desto wichtiger wird, dass Koordination das Modell nicht ausbremst. Ein schwächeres Modell kann durch kluge Architektur sichtbar profitieren. Bei Spitzenmodellen ist der Gewinn kleiner und wird leichter durch Koordinationsaufwand wieder aufgefressen.
Instruktionen bleiben zentral. Der größte Teil des Systemverhaltens hängt weiterhin davon ab, wie die Agenten angeleitet werden. Das gilt sowohl bei Cursor als auch in den Benchmarks der Studie. Wer plant, wer arbeitet, wer validiert, wie mit Fehlern umgegangen wird, wie stark parallelisiert werden darf: Alles ist letztlich in Text gegossene Verhaltensregel.
Lin betonte im Interview, wie viel Zeit in die Überarbeitung dieser Instruktionen floss. Manche frühere Architekturen scheiterten nicht an technischen Grenzen, sondern an falschen Anweisungen. Koordination, Vermeidung von Sackgassen, Fokus über lange Zeiträume: Das entsteht durch gute Instruktionen, nicht durch Magie der Agenten.
Auch bei hochautomatisierten Systemen mit Tausenden Workern bleibt der menschliche Input entscheidend: bei der Wahl der Aufgabe, bei der Formulierung der Anweisungen und bei der Entscheidung, wann ein Agentenschwarm wirklich sinnvoll ist. Und wann ein einziger starker Agent plus ein erfahrener Entwickler völlig ausreicht.
Die nächste Stellschraube: RL-Umgebungen für Code und Agenten-Koordination
Neben dem Harness gibt es eine zweite Stellschraube: wie die Modelle selbst trainiert werden. Hier investieren die großen KI-Labore gerade massiv in Lernumgebungen für Agenten. Als Basis dient Reinforcement Learning (verstärkendes Lernen): Das Modell probiert etwas aus, bekommt Feedback darüber, ob es funktioniert hat oder nicht, und passt sein Verhalten entsprechend an.
Code und Software eignen sich besonders gut für solche „Reinforcement-Learning-Gyms“: Ob eine Lösung funktioniert, lässt sich durch Tests automatisch prüfen, und auch Zwischenschritte lassen sich testen. Das bedeutet klares Feedback und schnelle Iterationen.
Laut The Information hat Anthropic intern diskutiert, im kommenden Jahr über eine Milliarde Dollar in solche agentischen Trainingsumgebungen zu investieren. Startups wie Mechanize (arbeitet Berichten zufolge bereits mit Anthropic zusammen) positionieren sich im entstehenden Markt.
Die Logik dahinter: Bessere Trainingsumgebungen führen zu Modellen, die in Systemen wie Claude Code oder Cursor zuverlässiger arbeiten. Ob das aufgeht, ist offen. Diese Anwendung von Reinforcement Learning hat mitunter Probleme mit der Übertragung auf neue Situationen und mit sogenanntem Reward Hacking. Das bedeutet: Agenten finden Schlupflöcher, um ihre Belohnungssignale zu maximieren, statt die eigentliche Aufgabe zu lösen. Aber die Investitionen deuten darauf hin, dass die KI-Unternehmen davon überzeugt sind, dass sich diese Probleme zumindest teilweise lösen lassen.
Training auf Zusammenarbeit
Ein verwandter Ansatz geht noch einen Schritt weiter: Modelle nicht nur auf besseres Coding trainieren, sondern explizit auf die Koordination mit anderen Agenten. Die Probleme mit Agentenschwärmen, die wir oben beschrieben haben, könnten auch daran liegen, dass heutige Modelle schlicht nicht für Zusammenarbeit optimiert wurden.
Das chinesische Unternehmen Moonshot AI hat mit Kimi K2.5 ein Modell vorgestellt, das diesen Weg einschlägt. Laut Hersteller kann es bis zu 100 Unteragenten orchestrieren und parallele Arbeitsabläufe mit bis zu 1.500 Werkzeugaufrufen koordinieren. Im Vergleich zu einem Einzelagenten soll das die Ausführungszeit um den Faktor 4,5 verkürzen.
Allerdings ist Vorsicht geboten: Die Schwarm-Funktion ist noch im Beta-Stadium, und die beeindruckenden Zahlen stammen aus internen Benchmarks von Moonshot selbst. Unabhängige Tests der Schwarm-Koordination stehen noch aus. Erste Nutzerberichte deuten darauf hin, dass die Funktion bei klar strukturierten Aufgaben zuverlässig arbeitet, aber bei unklaren Spezifikationen oder schlecht definierten Werkzeugen deutlich nachlässt.
Die spannende Frage dahinter: Könnte explizites Koordinationstraining die Probleme lösen, die die Agentik-Studie dokumentiert? Das hängt davon ab, woher die Probleme kommen.
Bei Aufgaben, die sich gut zerlegen lassen, könnte explizites Koordinationstraining weiterhelfen: Agenten, die sparsamer kommunizieren, Fehler früher abfangen und besser einschätzen, wann Parallelisierung sinnvoll ist, würden genau an den Engstellen ansetzen, die das Paper beschreibt. Belegt ist das bislang nicht.
Bei strukturell sequenziellen Aufgaben sitzt das Problem tiefer. Dort verschlechtern zusätzliche Agenten die Ergebnisse über alle Architekturen hinweg. Die Studie legt nahe, dass sich solche Aufgaben kaum sinnvoll zerlegen lassen. Effizientere Kommunikation allein dürfte daran wenig ändern.
Mehr Denkzeit, bessere Ergebnisse
Lernumgebungen verbessern die Modelle beim Training. Aber es gibt eine zweite Stellschraube: wie viel Rechenzeit das Modell während der Anwendung für eine Aufgabe aufwenden darf. Mehr Denkzeit bedeutet oft bessere Ergebnisse.
Laut Andrej Karpathy war der Leistungsfortschritt 2025 vor allem durch längere Trainingsläufe mit Reinforcement Learning definiert, nicht durch größere Modelle. Zusätzlich bekamen wir einen neuen Regler: längere Denkketten und mehr Rechenzeit bei der Anwendung. OpenAIs o1 war die erste Demonstration, aber o3 war der Wendepunkt, an dem man den Unterschied spürbar merkte.
Die Ergebnisse sind messbar, auch wenn sie mit Vorsicht zu interpretieren sind: Bei der Internationalen Informatik-Olympiade 2025 erreichte ein OpenAI-System im separaten KI-Track Gold-Niveau und landete auf Platz sechs unter 330 menschlichen Teilnehmern. Nur fünf Menschen waren besser. Bei den ICPC World Finals 2025 löste OpenAIs System alle zwölf Aufgaben. Das beste menschliche Team schaffte elf.
Allerdings: Die KI-Systeme traten in beiden Fällen in separaten Tracks an und nutzten Ensemble-Ansätze mit mehreren Modellen. Es sind beeindruckende Benchmarks, aber sie zeigen Spitzenleistungen unter kontrollierten Bedingungen, nicht noch nicht alltägliche Coding-Arbeit.
Drei Szenarien: Baseline, Beschleunigung, Verlangsamung
KI-Agenten haben sich 2025 zwar nicht als das eine, revolutionäre Produkt etabliert, sind aber durch die massiv gestiegenen Fähigkeiten aktueller Reasoning-Modelle wie GPT-5.2 Thinking oder Claude Opus 4.5 längst Teil des Alltags geworden.
Die Technologie ist da, doch die Hürden verschieben sich: Statt an der Intelligenz der Modelle scheitert der breite Einsatz oft an der Zuverlässigkeit bei komplexen, sequenziellen Aufgaben und ungelösten Sicherheitsrisiken wie Prompt Injections. Der Schlüssel zum Erfolg liegt daher nicht mehr nur im Modell selbst, sondern im „Harness Engineering“: dem systematischen Bau einer kontrollierten Umgebung, die Autonomie ermöglicht, ohne die Sicherheit zu opfern.
Szenario 1: Die Engineering-Evolution (Baseline)
Die Entwicklung setzt sich im bisherigen Tempo fort. Der Fokus verschiebt sich weg von „magischen“ neuen Modellen hin zu Harness Engineering als Industriestandard. Unternehmen akzeptieren, dass Modelle allein unzuverlässig sind, und bauen robuste Gerüste (Context-Management, Memory, Guardrails), um Probleme wie Kontexterosion zu umgehen.
Multi-Agenten-Systeme etablieren sich in Nischen mit klarer Aufgabenteilung (z. B. Software-Migrationen), während der Mensch eng eingebunden bleibt – fast alle Agenten berichten weiterhin an Menschen, Freigabeschritte sind Standard. Der Trade-off zwischen Autonomie und Sicherheit bleibt bestehen; Prompt Injection wird nicht technisch gelöst, sondern durch Prozess-Design (Human-in-the-loop) mitigiert.
Szenario 2: Der RL-Durchbruch (Beschleunigung)
Die massiven Investitionen in Reinforcement-Learning-Umgebungen (wie von Anthropic und OpenAI vorangetrieben) zahlen sich schneller aus als erwartet. Agenten lernen in simulierten Umgebungen ("Gyms"), ihre eigenen Fehler zu korrigieren und Sackgassen frühzeitig zu erkennen. Dadurch werden sie auch bei langen, sequenziellen Aufgaben verlässlich. Neue Modell-Architekturen entschärfen das Prompt-Injection-Problem weitgehend, was den Weg für echte Autonomie in sensiblen Datenbereichen freimacht. Die Vision von KI-Agenten, die ganze Arbeitsplätze oder Forschungsbereiche autonom übernehmen, rückt in greifbare Nähe.
Szenario 3: Sicherheits-Blockade (Verlangsamung)
Die im Artikel beschriebenen Grenzen erweisen sich als hartnäckiger als gedacht. Das RL-Training stößt auf fundamentale Probleme wie Reward Hacking (Agenten tricksen das Belohnungssystem aus) und mangelnde Generalisierung. Zudem führen spektakuläre Sicherheitsvorfälle durch Prompt-Injections zu strengen regulatorischen Einschränkungen oder internen Unternehmens-Stopps.
Die Erkenntnis, dass große Agenten-Schwärme oft ineffizienter sind als Einzelmodelle, führt zu einer Desillusionierung. Unternehmen begrenzen bewusst die Autonomie ihrer Systeme und kehren zurück zu eng kontrollierten „Assistenten“ mit starker menschlicher Aufsicht, statt auf autonome „Agenten“ zu setzen.
Unser Standpunkt
Das Baseline-Szenario ist am wahrscheinlichsten, mit Tendenz zur Beschleunigung im Code-Bereich. Die Investitionen in Trainingsumgebungen werden weiter steigen, und die Code-Domäne profitiert besonders, weil Erfolg durch automatisierte Tests verifizierbar ist. Ähnlich geeignet sind strukturierte Workflows in Versicherung, HR oder Analyse, wo Aufgaben parallelisierbar sind und Erfolgskriterien eindeutig definiert werden können.
Weniger geeignet sind Domänen mit hohem Ermessensspielraum, regulatorischen Anforderungen oder Reputationsrisiken – hier bleibt intensive menschliche Kontrolle unverzichtbar, was die Effizienzgewinne durch Automatisierung weitgehend aufzehrt.
Gleichzeitig bleiben die Sicherheitsprobleme fundamental ungelöst: Eine 30-prozentige Erfolgsrate bei Prompt-Injection-Angriffen ist für kritische Anwendungen inakzeptabel.
Mit Blick aufs Jahr 2026 bleibt die entscheidende Erkenntnis: Den Unterschied macht das System drumherum, nicht das Modell allein. Wer in agentische KI investiert, sollte das Harness Engineering priorisieren und mit eng definierten Aufgaben sowie eingebauten Freigabeschritten beginnen. Vollautonome digitale Kollegen bleiben vorerst eine Vision.
Ground Truth: Quellen & Deep Dives
Externe Quellen:
- Microsoft / Copilot Agenten
- Anthropic / Effektive Agenten
- OpenAI / Deep Research
- OpenAI / Codex Agent Loop
- OpenAI / In-House Data Agent
- Anthropic / Langzeit-Agenten
- METR / KI-Aufgabenmessung
- Cursor / Skalierte Agenten
- YouTube / Wilson Lin Interview
- GitHub / FastRender Issues
- Pivot to AI / Cursor-Kritik
- embedding-shapes / Ein-Agent-Browser
- HackerNews / Willison Kommentar
- The Information / KI-Coworker
- Kimi / K2.5 Modell
THE DECODER Artikel:
- THE DECODER / o3 und o4-mini Vorstellung
- THE DECODER / KI-Agenten Studie
- THE DECODER / Multi-Agent Studie
- THE DECODER / Red-Teaming Studie
- THE DECODER / Anthropic Prompt Injection
Heise KI Pro:
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.