KI-Rechercheagenten erfinden lieber Fakten als zuzugeben, dass sie etwas nicht wissen

Eine neue Studie des AI-Agent-Teams des chinesischen Smartphoneherstellers Oppo zeigt die systematischen Schwächen von Deep-Research-Systemen, die automatisch ausführliche Rechercheberichte erstellen sollen. Fast ein Fünftel aller Fehler entsteht, weil die Systeme plausibel klingende, aber erfundene Inhalte generieren.
Die Forscher entwickelten dafür zwei neue Bewertungssysteme namens FINDER (Fine-grained DEepResearch bench) und DEFT (Deep rEsearch Failure Taxonomy) und analysierten damit rund 1.000 generierte Berichte von verschiedenen kommerziellen und frei verfügbaren Systemen.
Erfundene Details täuschen Kompetenz vor
Ein System behauptete etwa, ein Investmentfonds habe über 20 Jahre eine jährliche Rendite von exakt 30,2 Prozent erzielt. Die präzise Dezimalzahl erweckt den Eindruck sorgfältiger Recherche. Solche detaillierten Performance-Daten sind für private Investoren aber in der Regel nicht öffentlich verfügbar. Das System hat die Zahl mit hoher Wahrscheinlichkeit erfunden.
In einem anderen Fall sollte ein System wissenschaftliche Arbeiten analysieren und listete 24 Quellenangaben auf. Bei der Überprüfung führten mehrere Links zu nicht existierenden Einträgen. Andere Referenzen waren Review-Artikel statt der geforderten Originalforschung. Das System behauptete dennoch, alle Quellen seien überprüft.
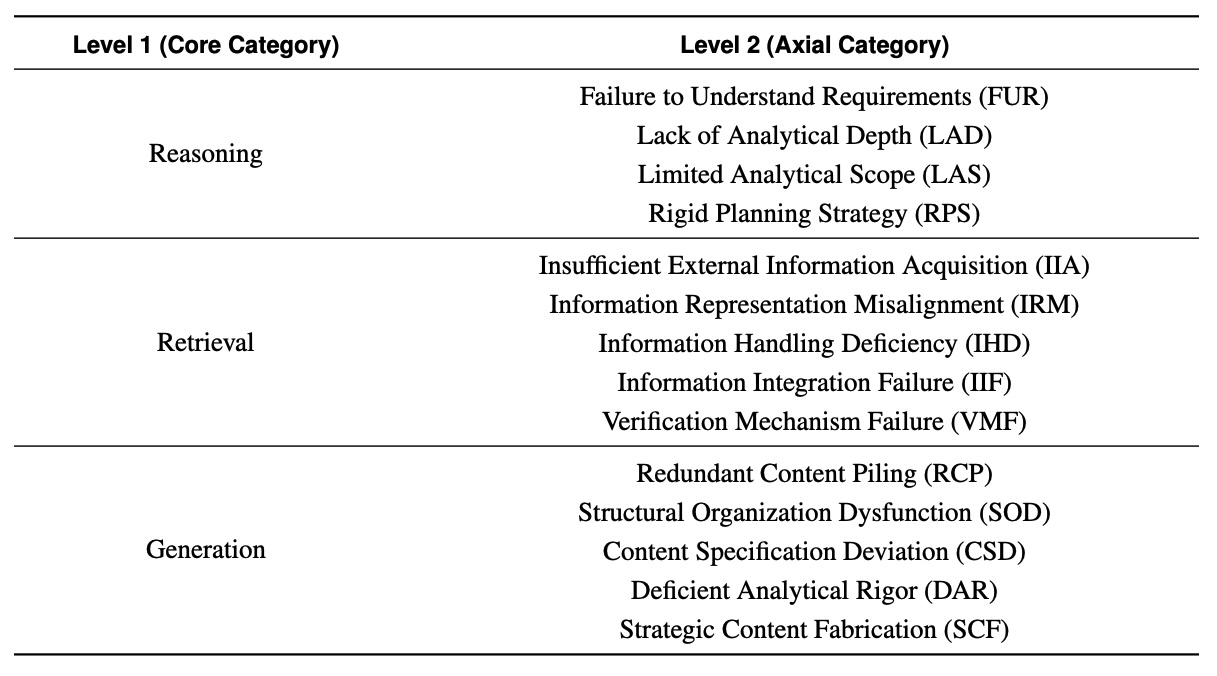
Die Forscher identifizierten insgesamt 14 verschiedene Fehlertypen über die drei Hauptkategorien Reasoning, Retrieval und Generation. Mit 39 Prozent aller Fehler liegen Probleme bei der Berichterstellung an der Spitze. Die Recherche selbst macht 33 Prozent der Fehler aus, primär durch unzureichende Informationsbeschaffung und fehlende Verifizierung. Denkfehler und Planungsprobleme machen 28 Prozent aus.
Starre Pläne statt flexible Anpassung
Interessanterweise verstehen die meisten Systeme, was von ihnen verlangt wird. Das Problem liegt in der starren Ausführung. Ein System plant etwa eine umfassende Datenbank-Analyse, kann dann aber nicht auf die Datenbank zugreifen. Statt die Strategie anzupassen, füllt es einfach alle geplanten Abschnitte mit selbst generierten Inhalten.
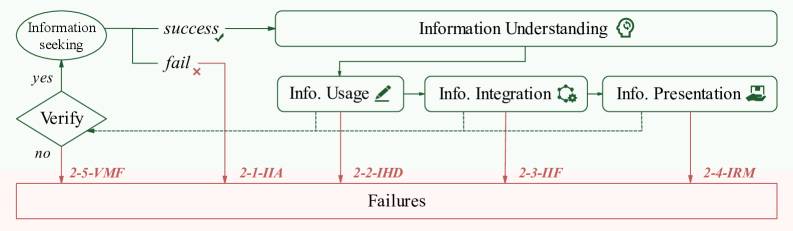
Die Forscher nennen das fehlende Reasoning Resilience, also die Fähigkeit, den Denkprozess in dynamischen Situationen anzupassen. Diese Anpassungsfähigkeit sei wichtiger als die maximale analytische Kapazität unter idealen Bedingungen.
Für die Bewertung entwickelten die Forscher den FINDER-Benchmark mit 100 Forschungsaufgaben und 419 Prüfpunkten. Die Aufgaben sind deutlich komplexer als in bisherigen Tests und verlangen explizit nach überprüfbaren Quellen und methodischer Strenge.
Auch Spitzensysteme erreichen nur 51 Prozent
Die Forscher testeten kommerzielle Systeme wie Gemini 2.5 Pro Deep Research und OpenAIs o3 Deep Research sowie frei verfügbare Alternativen. Gemini 2.5 Pro erreichte mit 51 von 100 möglichen Punkten die beste Gesamtleistung. o3 Deep Research überzeugte bei der Faktentreue mit knapp 66 Prozent korrekter Zitate.
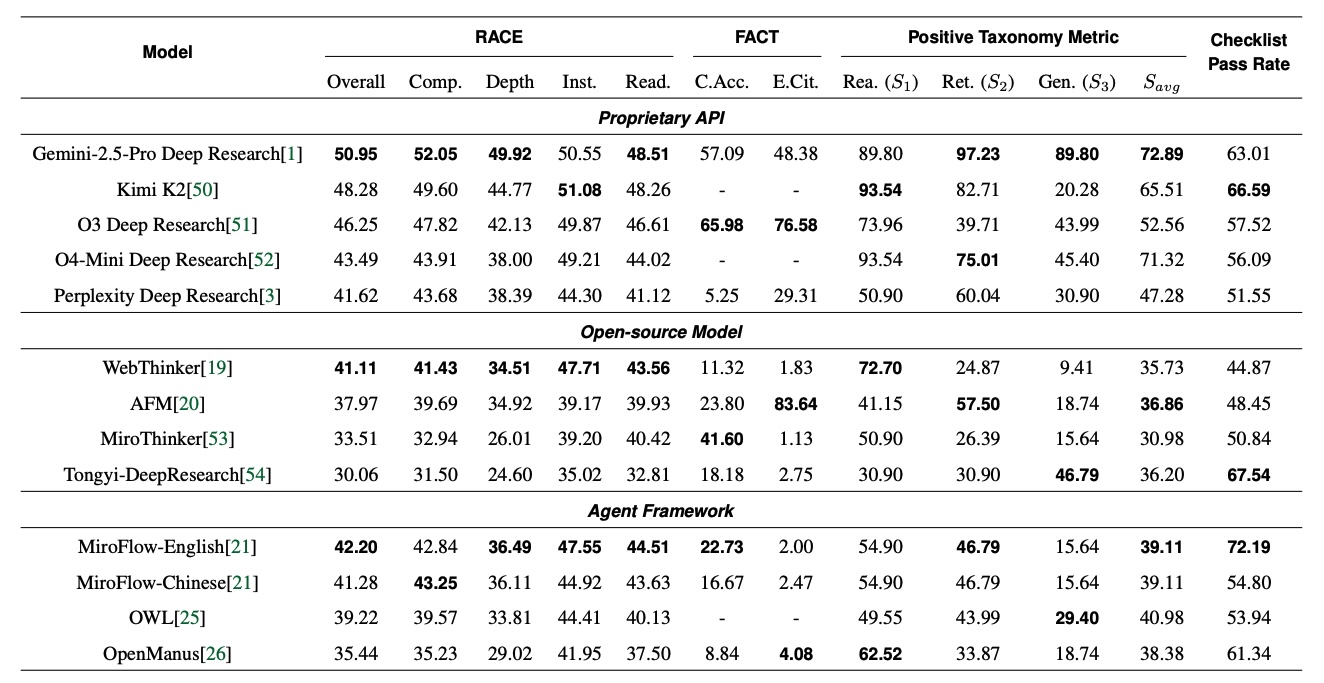
Die Ergebnisse zeigen laut den Forschern, dass aktuelle Systeme nicht am Aufgabenverständnis scheitern, sondern an der Integration von Evidenz und der Anpassungsfähigkeit. Systeme bräuchten explizite Prüfmechanismen über alle Phasen des Rechercheprozesses und müssten lernen, transparent mit Unsicherheiten umzugehen, statt Informationslücken durch erfundene Details zu kaschieren.
Die Frameworks FINDER und DEFT sind auf GitHub verfügbar. Die Forscher hoffen, dass die Community damit verlässlichere Rechercheagenten entwickeln kann.
Mit der Fähigkeit, zu immer niedrigeren Preisen immer mehr Tokens verarbeiten und generieren zu können, versprach die Ende 2024 von Google eingeführte Deep-Research-Funktion, ausführliche Berichte in wenigen Minuten selbstständig erstellen zu können. Auch Perplexity, Grok und OpenAI führten kurz darauf ähnliche Features ein und rufen teilweise mehr als 100 Webseiten als Quellen in einem Durchgang ab.
Immer mehr zeichnet sich jedoch ab, dass sich tiefgehende Recherche-Ergebnisse nicht einfach durch die Skalierung von Eingabedaten verbessern lassen und sich die Fehlerquellen herkömmlicher KI-Suche eher noch verstärken. Dennoch können Deep-Research-Funktionen nützlich sein, etwa für die explorative Suche nach Quellen. Man sollte nur wissen, wie man die Systeme bedient.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.