
Das britische Start-up Wayve, das sich auf KI-gestütztes autonomes Fahren spezialisiert hat, stellt sein neues Modell vor: Lingo-1 kombiniert maschinelles Sehen mit textbasierter Logik.
Menschen müssen im Straßenverkehr ständig Entscheidungen treffen: Wann geben wir Gas, wann nehmen wir den Fuß vom Gas, überholen wir oder halten wir uns lieber zurück?
Diese Entscheidungen müssen auch selbstfahrende Autos treffen. Doch anders als Menschen können sie ihre Entscheidungen nicht begründen - noch nicht. Lingo-1 soll das ändern.
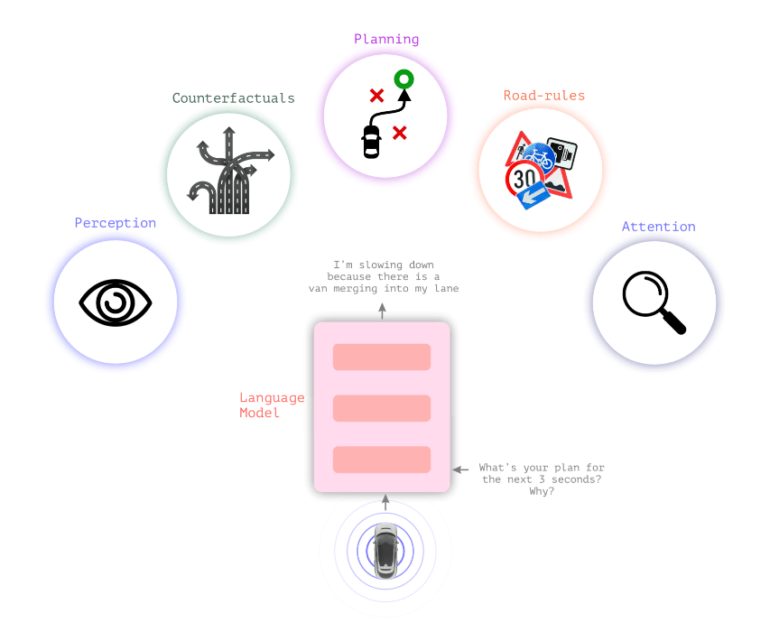
Lingo-1 verbindet Sprachmodelle mit visuellen Modellen
Herkömmliche autonome Fahrsysteme haben eine visuelle Wahrnehmung, auf deren Grundlage das System eine Entscheidung trifft. Das neue visuelle Sprachmodell Lingo-1 von Wayve schaltet zwischen die visuelle Wahrnehmung und die Handlung eine textuelle Logik, mit der das Auto die Handlung erklären kann.
So liefert das Auto zu einer Fahrentscheidung und zur Verkehrssituation im Allgemeinen ständig textuelle Aussagen, die die aktuelle Situation beschreiben und Entscheidungen begründen, ähnlich wie ein laut denkender Fahrer oder ein Fahrlehrer, der die Aufmerksamkeit des Fahrschülers unterstützen will.
Video: Wayve
Diese textuelle Logik könnte das Sicherheitsgefühl im Auto erhöhen, da autonome Entscheidungen weniger als "Black Box" wahrgenommen werden. Sie könnte auch zur Sicherheit autonomer Fahrzeuge beitragen, indem das System Verkehrsszenarien textuell durchdenkt, die nicht in den Trainingsdaten enthalten sind.
Darüber hinaus kann das Verhalten von Lingo-1 durch einfache Textbefehle flexibel angepasst und mit weiteren von Menschen skizzierten Beispielen trainiert werden, ohne dass zunächst aufwendig viele visuelle Daten gesammelt werden müssen.
"Kausale Schlussfolgerungen sind für das autonome Fahren von entscheidender Bedeutung, da sie es dem System ermöglichen, die Beziehungen zwischen Elementen und Aktionen innerhalb einer Szene zu verstehen", schreibt Wayve.
Video: Wayve
Anstatt tausende von visuellen Beispielen zu sammeln, wie ein Auto für einen Fußgänger bremst, würden einige Beispiele dieser Szene mit kurzen Textbeschreibungen ausreichen, wie sich das Auto in dieser Situation verhalten sollte und welche Faktoren zu berücksichtigen sind.
Auch autonome Autos könnten vom umfassenden Wissen großer Sprachmodelle profitieren
Generelles Wissen in großen Sprachmodellen könnte auch Fahrmodelle verbessern, insbesondere in bisher unbekannten Situationen.
"LLMs verfügen bereits über umfangreiches Wissen über menschliches Verhalten, das sie aus Datensätzen im Internet gewonnen haben, so dass sie in der Lage sind, Konzepte wie Objekterkennung, Verkehrsregeln und Fahrmanöver zu verstehen. Zum Beispiel können die Sprachmodelle zwischen einem Baum, einem Geschäft, einem Haus, einem Hund, der einem Ball hinterherläuft, und einem Bus, der vor einer Schule hält, unterscheiden", schreibt Wayve.
Video: Wayve
Lingo-1 wurde mit Bild-, Sprach- und Aktionsdaten trainiert, die von Wayve-Fahrern während ihrer Fahrten in London gesammelt wurden. Laut Wayve erreicht Lingo-1 derzeit 60 Prozent der Genauigkeit menschlicher Fahrer. Das System hat seine Leistung seit den ersten Tests im August und September durch Verbesserungen der Architektur und des Trainingsdatensatzes mehr als verdoppelt.
Einschränkungen sind, dass Lingo-1 bisher nur mit Daten aus London trainiert wurde. Außerdem kann Lingo-1 für LLM typische falsche Antworten geben. Allerdings habe Lingo-1 hier einen Vorteil durch die Verknüpfung mit visuellen Daten aus der realen Welt, schreibt das Unternehmen.
Technische Herausforderungen seien die großen Kontextlängen für Videobeschreibungen bei multimodalen Modellen und die Integration von Lingo-1 in die Closed-Loop-Architektur direkt im autonomen Fahrzeug.
Im Juni stellte Wayve GAIA-1 vor, ein generatives KI-Modell, das dazu beitragen kann, den Engpass zu überwinden, der durch die begrenzte Verfügbarkeit von Videodaten für das Training von KI-Modellen für verschiedene Verkehrssituationen entsteht. GAIA-1 lernt Fahrkonzepte, indem es die nächsten Bilder in einer Videosequenz vorhersagt, was es zu einem wertvollen Werkzeug für das Training autonomer Systeme für die Navigation in komplexen realen Szenarien macht.





