Kontext-Dateien für KI-Agenten: Gut gemeint, aber selten hilfreich

Kontext-Dateien sollen Coding-Agenten produktiver machen. Neue Forschung zeigt: Das klappt nur unter sehr bestimmten Bedingungen.
Eine aktuelle Studie von Forschern der ETH Zürich wirft ein deutlich kritischeres Licht auf die Praxis, Coding-Agenten mit Kontext-Dateien wie AGENTS.md auszustatten. Ihnen zufolge verschlechtern insbesondere automatisch generierte Kontext-Dateien die Erfolgsrate der Agenten tendenziell, während sie gleichzeitig die Inferenzkosten um über 20 Prozent erhöhen.
Für ihre Untersuchung entwickelten die Forscher einen eigenen Benchmark mit 138 Aufgaben aus 12 Open-Source-Repositories, die allesamt von Entwicklern geschriebene Kontext-Dateien enthalten, nutzten aber auch den weit verbreiteten SWEbench-Lite. Getestet wurden vier gängige Coding-Agenten, darunter Claude Code, Codex und Qwen Code, jeweils in drei Szenarien: ohne Kontext-Datei, mit LLM-generierter Kontext-Datei und mit der von Entwicklern geschriebenen Variante.
LLM-generierte Dateien führten in fünf von acht Testsettings zu schlechterer Performance. Von Entwicklern geschriebene Kontext-Dateien schnitten zwar besser ab, verbesserten die Erfolgsrate im Schnitt aber nur um rund 4 Prozentpunkte gegenüber dem Szenario ganz ohne Kontext-Datei.
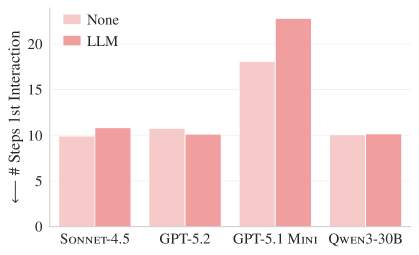
Kontext-Dateien halfen zudem den Coding-Agenten auch nicht, relevante Dateien schneller zu finden. Bei dem schwächeren Modell GPT-5.1 Mini stieg die Zahl der Schritte bis zur ersten Interaktion mit einer relevanten Datei durch LLM-generierte Kontext-Dateien sogar deutlich an.
Zusätzliche kognitive Last
Besonders aufschlussreich ist die Verhaltensanalyse. Die Agenten befolgten die Anweisungen in den Kontext-Dateien durchaus: Sie führten mehr Tests durch, durchsuchten mehr Dateien und nutzen Repository-spezifische Tools häufiger. Das Problem liegt also nicht darin, dass die Agenten die Dateien ignorieren. Vielmehr machten unnötige Anforderungen die Aufgaben schwieriger, was sich auch daran zeige, dass die Agenten signifikant mehr Reasoning-Tokens verbrauchten.
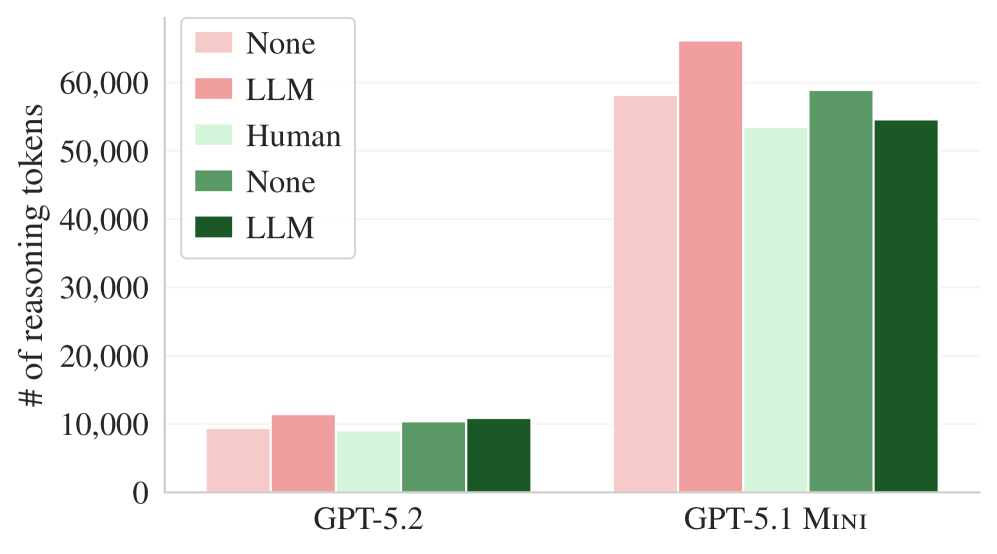
Die Kontext-Dateien erzeugten zusätzliche kognitive Last, ohne den Problemlösungsprozess zu verbessern. Zudem seien LLM-generierte Kontext-Dateien weitgehend redundant zur bereits vorhandenen Dokumentation. Erst wenn sämtliche Dokumentation aus den Repositories entfernt wurde, zeigten sie einen positiven Effekt.
Kontext-Dateien sind sinnvoll, wenn Wissen fehlt
Vercel testete kürzlich einen sehr spezifischen Anwendungsfall: die Vermittlung von aktuellem Framework-Wissen für Next.js, also genau jene Art von Information, die nicht in den Trainingsdaten enthalten ist. Dort ist der Vorteil von persistentem Kontext nachvollziehbar groß. Die ETH-Forscher hingegen untersuchten den allgemeineren Fall, reale Bug-Fixes und Feature-Ergänzungen in diversen Repositories, und fanden dort kaum messbare Vorteile. Die Studie widerspricht Vercels Befunden also nicht grundsätzlich, setzt sie aber in einen wichtigen Kontext.
Auf automatisch generierte Kontext-Dateien sollten Entwickler demnach vorerst verzichten und nur minimale, manuell verfasste Anforderungen aufnehmen, etwa Hinweise auf spezifische Tools oder Build-Systeme. AGENTS.md ist laut den Forschern nur dann sinnvoll, wenn es manuell verfasst wird, um tatsächlich fehlendes Wissen zu kompensieren. Als allgemeines Allheilmittel für bessere Coding-Agenten tauge es laut der aktuellen Forschungslage nicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.