Künstliche Intelligenz: Ist das die Lösung gegen Maschinen-Vorurteile?
Forscher des MIT entwickeln eine Künstliche Intelligenz, die Vorurteile aus Datensätzen entfernen kann. Eine Formel für die Gerechtigkeit, wenn man so will.
KI-Systeme können Vorurteile haben, das ist eines der großen Probleme Künstlicher Intelligenz. Verzerrte Trainingsdaten sind der Auslöser: Wenn eine KI Brautkleider nur durch westliche Hochzeitsfotos kennenlernt, ist sie in anderen Kulturen aufgeschmissen. Zum Beispiel.
Auf der Suche nach einer Lösung gab es bislang zwei Ansätze: Bessere Daten oder bessere Algorithmen. Forscher des MIT stellen jetzt einen dritten Ansatz vor.
KI soll Verzerrungen erkennen
„Wir haben in den letzten Jahren gelernt, dass KI-Systeme unfair sein können, was gefährlich ist, wenn sie zunehmend Teil unseres Lebens werden – von der Vorhersage von Verbrechen bis zur Anzeige von Nachrichten“, heißt es in einer Mitteilung der KI-Abteilung des MIT.
Das Team habe daher einen Algorithmus entwickelt, der in vorhandenen Datensätzen Verzerrungen erkennen und eliminieren soll. Getestet wurde er bei der Gesichtserkennung.
Eine vorurteilsfreie KI sollte Gesichter immer als solche erkennen – unabhängig von Hautfarbe, Geschlecht oder Alter der Person. Doch bei unausgeglichenen Trainingsdaten ist die KI anschließend häufig nicht dazu in der Lage.
Daher widmet sich die MIT-KI nicht nur ihrem Standardtraining, sondern lernt gleichzeitig die latenten Strukturen der Daten kennen. Bei Porträts sind das Merkmale wie zum Beispiel Haare, Geschlecht, Aufnahmewinkel, Alter oder Hautfarbe.
Überrepräsentierte Merkmale werden reduziert
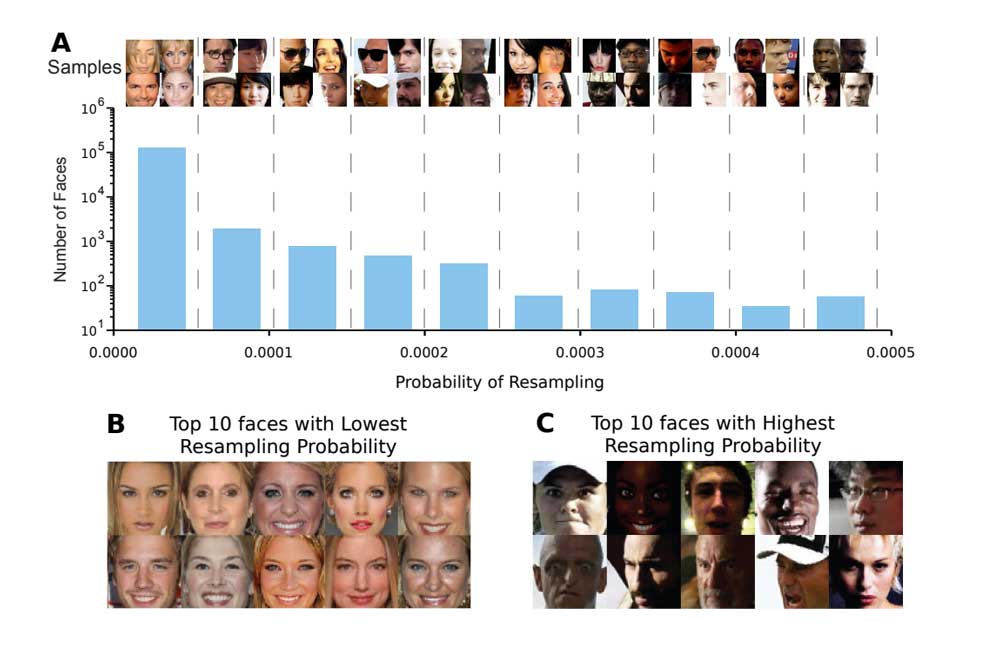
Die KI entfernt nach der ersten Analyse des Datensatzes überrepräsentierte Merkmale entsprechend ihrer Häufigkeit. Dadurch erhöht sich die Wahrscheinlichkeit, dass seltenere Merkmale einen stärkeren Einfluss beim Training haben – denn sie kommen jetzt im Verhältnis häufiger vor. So werden sie später folglich besser erkannt.
Sind zum Beispiel häufiger jüngere als ältere Menschen in einem Datensatz vertreten, schmeißt die KI einige Bilder junger Menschen raus. So treten die Porträts der älteren Menschen stärker in den Vordergrund des Trainings. Dadurch wird das Merkmal „Alter“ stärker trainiert und ältere Menschen besser erkannt.

Noch nicht perfekt
Die Forscher testeten ihre KI am PPB Datensatz, der 1.270 Porträtfotos enthält. Die Erkennungsrate überstieg den aktuellen Stand der Technik: Die Trainingsmethode der Forscher reduzierte die Vorurteile der KI.
Während sie zum Beispiel hellhäutige Menschen genauso gut erkannte wie bisherige Spitzen-KIs, identifizierte sie dunkelhäutige Menschen in fast 95 statt nur 87 Prozent aller Fälle. Schon jetzt könnte die Methode also grobe Schnitzer vermeiden, wie sie zum Beispiel Amazons Rekognition unterliefen.
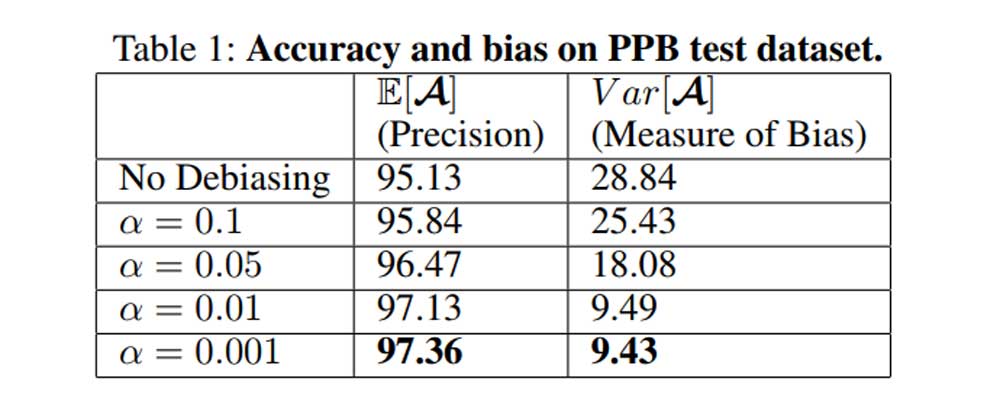
Allerdings ist noch Luft nach oben, denn hellhäutige Männer erkennt die KI mit fast 100-prozentiger Genauigkeit, also noch immer besser.
Für die Forscher ist das ein Hinweis, dass die dürftige Datenlage weiter ein Problem ist. Denn mehr Daten bedeuten mehr Beispiele.
„Unser Modell ist durch die Seltenheit der Beispiele begrenzt, aber wir stellen fest, dass eine Vergrößerung der Gesamtmenge unseres Trainingsdatensatzes diesen Nachteil reduzieren kann“, heißt es in der Veröffentlichung.
Mit dem MIT-Ansatz braucht es womöglich keine speziellen, ausgeglichenen Datensätze mehr – vorurteilsfreie KIs könnten mit bereits existierenden Daten trainiert werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.