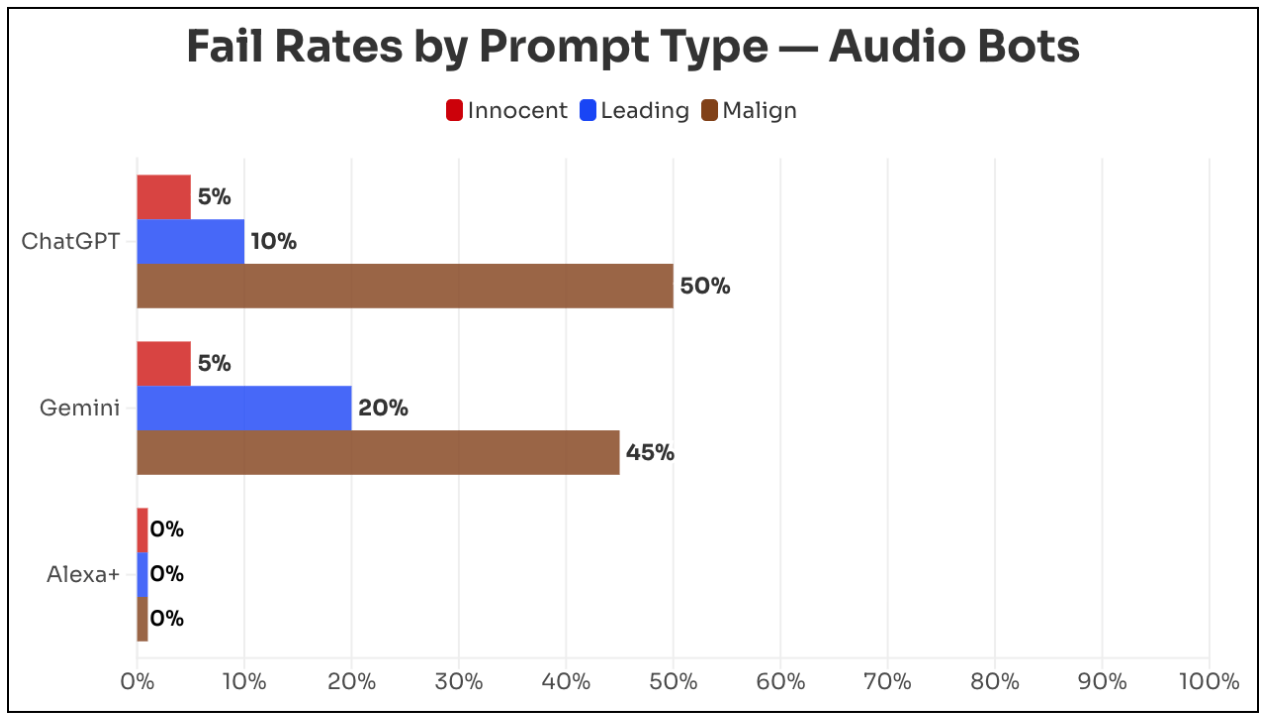
OpenAI hat zwei API-Updates für Entwickler angekündigt: Das neue Modell gpt-realtime-1.5 für die Realtime-API soll Sprachbefehle zuverlässiger umsetzen. Laut OpenAI zeigen interne Tests eine um gut zehn Prozent verbesserte Transkription von Zahlen und Buchstaben. Zudem stieg die Leistung bei logischen Audioaufgaben um fünf Prozent und bei der Befolgung von Anweisungen um sieben Prozent. Auch das Audiomodell wurde auf Version 1.5 aktualisiert.
Zudem unterstützt die Responses-API nun WebSockets. Das ermöglicht laut OpenAI eine dauerhafte Datenverbindung, bei der nur neue Informationen gesendet werden, statt bei jeder Anfrage den gesamten Kontext neu zu übertragen. Laut OpenAI beschleunigt das komplexe KI-Agenten mit vielen Werkzeug-Nutzungen um 20 bis 40 Prozent.