Laut OpenAI übertrifft medizinischer KI-Rat jetzt die Antworten von Ärzten

OpenAI hat einen neuen Bewertungsstandard für KI-Systeme im Gesundheitswesen vorgestellt. "HealthBench" soll realitätsnahe medizinische Gespräche systematisch auswerten. Laut OpenAI erreichen die neuesten Sprachmodelle des Unternehmens in diesem Test bessere Ergebnisse als die Vergleichsantworten von Ärztinnen und Ärzten.
Bisherige Tests für medizinische KI-Systeme weisen laut OpenAI erhebliche Schwächen auf: Sie bilden reale Gesprächssituationen nur unzureichend ab, wurden nicht ausreichend von medizinischen Experten geprüft oder bieten zu wenig Raum, um Verbesserungen fortgeschrittener Modelle zu messen.
Für HealthBench haben 262 Ärztinnen und Ärzte aus 60 Ländern 5.000 medizinische Gesprächsszenarien entwickelt. Die beteiligten Mediziner decken 26 Fachgebiete ab und sprechen zusammen 49 Sprachen.
Der Test prüft sieben medizinische Bereiche - von der Notfallmedizin bis zu Fragen der globalen Gesundheit. Ein KI-gestütztes Bewertungssystem analysiert die Antworten nach fünf Kriterien: Kommunikationsqualität, Befolgung der Instruktion, Genauigkeit, Kontextbewusstsein und Vollständigkeit. Dabei kommen insgesamt 48.000 Einzelkriterien zum Einsatz, die auf medizinischer Expertise basieren.
Die Bewertung der Antworten erfolgt durch ein KI-Modell (GPT-4.1), das die Erfüllung vorgegebener Kriterien prüft. Um die Zuverlässigkeit dieses automatisierten Bewertungssystems zu validieren, verglich OpenAI dessen Urteile mit Bewertungen durch Ärztinnen und Ärzte. Dabei zeigte sich laut OpenAI, dass die Übereinstimmung zwischen dem KI-Bewerter und den Ärzten ähnlich hoch war wie die Übereinstimmung zwischen verschiedenen Ärzten untereinander.
GPT-4.1 und o3 übertreffen ärztliche Basisantworten
Laut OpenAI schneiden die neuesten Modelle des Unternehmens, GPT-4.1 und das Reasoning-Modell o3, im HealthBench-Test besser ab als die Vergleichsantworten von Ärztinnen und Ärzten.
Das Unternehmen betont jedoch, dass diese Ergebnisse differenziert betrachtet werden müssen: Das Verfassen von Chat-Antworten auf medizinische Fragen gehöre nicht zu den üblichen Aufgaben von Medizinern. Daher sei ein direkter Vergleich zwischen KI-Systemen und ärztlichem Personal in diesem spezifischen Kontext nur begrenzt aussagekräftig.
Die Testergebnisse zeigen demnach primär die Fähigkeiten der KI-Modelle in einer sehr spezifischen Aufgabenstellung. Sie lassen keine unmittelbaren Rückschlüsse auf die Gesamtqualität medizinischer Versorgung durch Menschen oder KI zu.
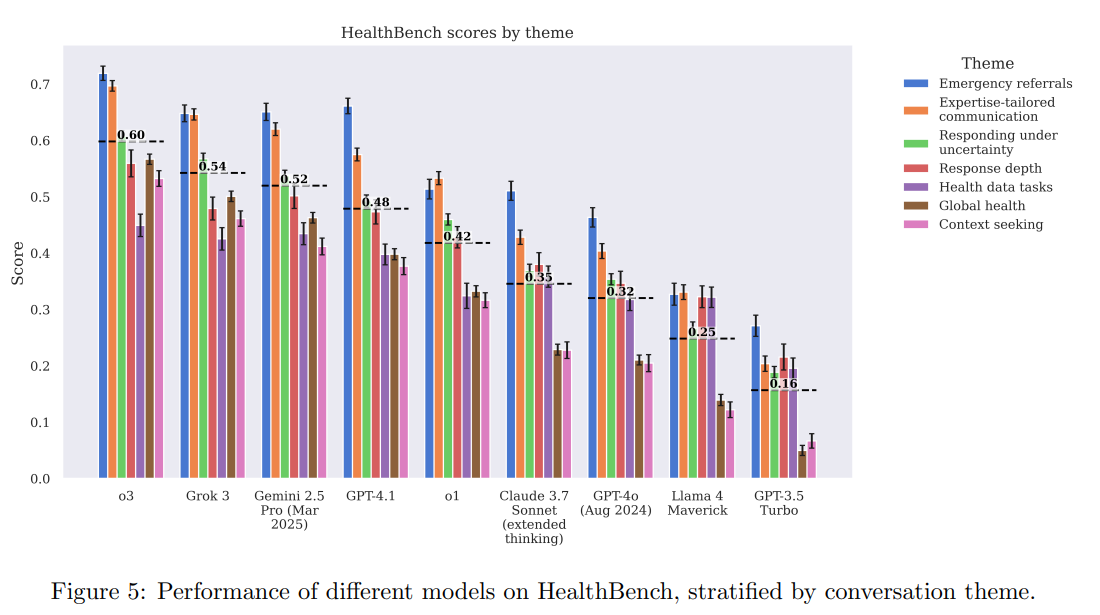
OpenAI berichtet von deutlichen Verbesserungen seiner Modelle im HealthBench-Test. Das neue Modell o3 (0,60) erreicht nach Unternehmensangaben etwa doppelt so hohe Bewertungen wie sein Vorgänger GPT-4o (0.32) vom August 2024. Vergleichbare Leistungen zeigen laut OpenAI nur die Konkurrenzmodelle Grok 3 (0.54) und Google Gemini 2.5 (0.52).
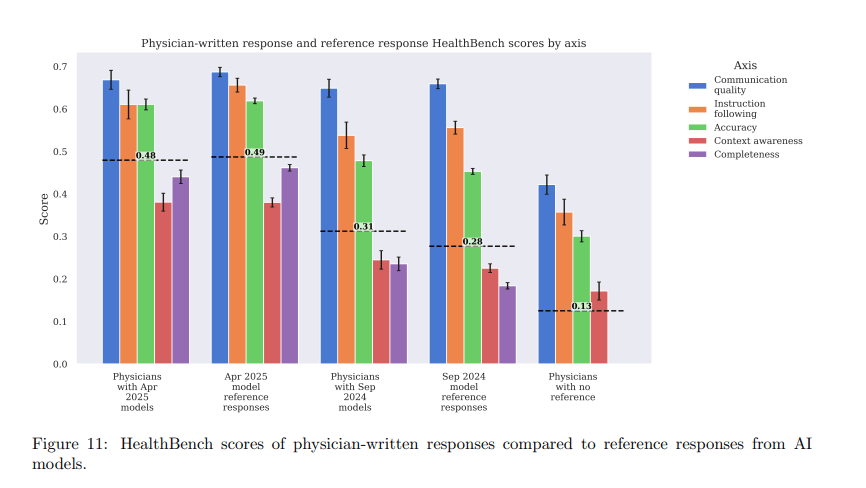
In einer ersten Testreihe vom September 2024 konnten Mediziner die Antworten älterer KI-Modelle noch verbessern, wenn sie diese als Ausgangspunkt für ihre eigenen Antworten nutzten. Ärztliche Antworten ohne KI-Unterstützung erzielten die niedrigsten Bewertungen.
In einer zweiten Testreihe im April 2025 mit den neueren Modellen GPT-4.1 und o3 änderte sich das Bild: Die Antworten der Ärztinnen und Ärzte erreichten keine besseren Bewertungen mehr als die KI-Systeme allein.
Bewertungen für Sicherheit, Kosten und Verlässlichkeit
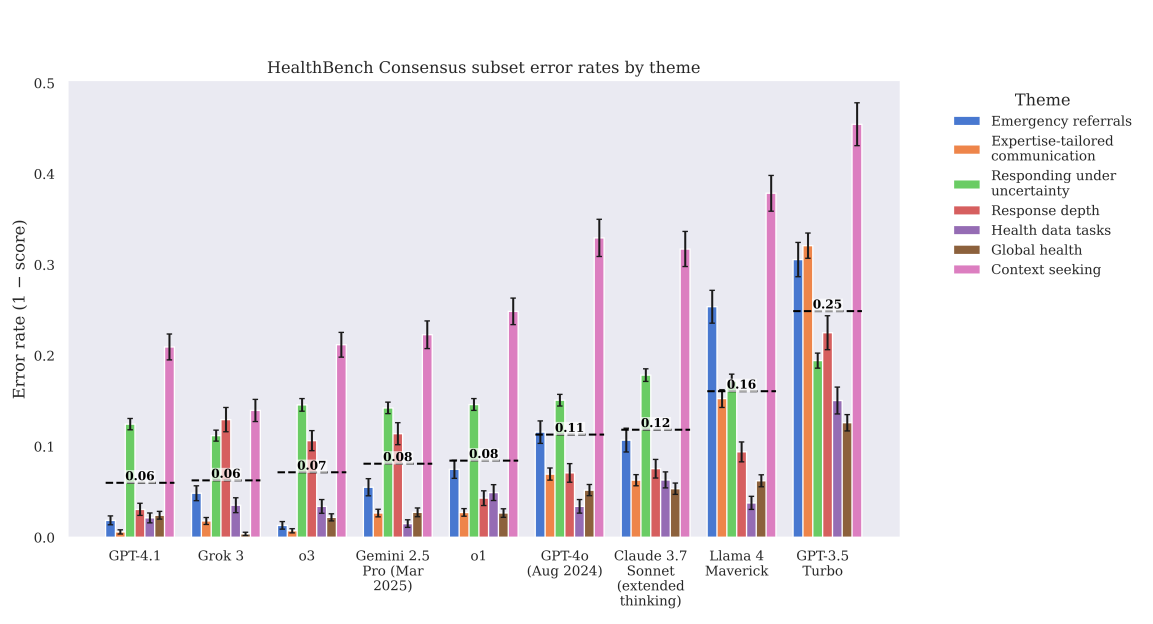
Gerade im Gesundheitswesen ist die Zuverlässigkeit von Modellen entscheidend: Eine einzige unsichere oder falsche Antwort kann den Nutzen vieler guter Antworten zunichtemachen. HealthBench prüft daher auch die Zuverlässigkeit der Modelle im schlechtesten Fall – also wie gut das schlechteste von mehreren generierten Ergebnissen ausfällt. Die neuesten Modelle zeigen hier ebenfalls deutliche Verbesserungen, auch wenn laut OpenAI noch Raum für Fortschritte besteht.
Ein weiterer Schwerpunkt liegt auf der Effizienz. Das kompakte Modell GPT-4.1 nano arbeitet laut OpenAI 25-mal kostengünstiger als sein Vorgänger GPT-4o vom August 2024 - bei gleichzeitig besserer Leistung. Dies könnte den Einsatz in Regionen mit begrenzten Ressourcen erleichtern.
Mit zwei Zusatzdatensätzen – HealthBench Consensus und HealthBench Hard – will OpenAI zudem eine Grundlage für besonders zuverlässige und besonders schwierige Testszenarien schaffen. Während "Consensus" nur mehrfach validierte Kriterien enthält, listet "Hard" 1.000 besonders anspruchsvolle Fälle, an denen auch Spitzenmodelle noch scheitern.
OpenAI hat alle Testdaten und Bewertungsmethoden von HealthBench (Paper) auf GitHub veröffentlicht und lädt die Forschungsgemeinschaft ein, den Benchmark zu nutzen und weiterzuentwickeln.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.