Laut OpenAI wird ChatGPT immer etwas Bullshit erzählen, aber es könnte Unsicherheit zugeben

OpenAI erklärt, warum Sprachmodelle immer halluzinieren werden. Künftig sollen sie aber zumindest besser erkennen, wenn sie Unsinn erzählen.
Sprachmodelle wie jene hinter ChatGPT werden auch künftig falsche Aussagen generieren – sogenannte Halluzinationen a.k.a. Bullshit. Das schreibt OpenAI in einer Analyse zur strukturellen Begrenztheit aktueller KI-Systeme.
Die Ursache liegt in der Architektur und Zielsetzung der Modelle: Sie sind darauf trainiert, das nächstwahrscheinliche Wort vorherzusagen, nicht, wahre Aussagen zu treffen. Weil sie keine Vorstellung von Wahrheit haben, können sie Falsches ebenso flüssig formulieren wie Richtiges, solange es sprachlich plausibel wirkt. In kreativen Anwendungen ist das gewünscht, problematisch wird es, wenn Nutzer faktische Korrektheit erwarten.
Verschiedene Halluzinationsformen
OpenAI unterscheidet dabei verschiedene Arten von Halluzinationen. Intrinsische Halluzinationen widersprechen der Eingabeaufforderung direkt – etwa wenn ein Modell auf die Frage "Wie viele Ds sind in DEEPSEEK?" mit "2" antwortet.
Extrinsische Halluzinationen wiederum widersprechen dem Trainingswissen oder der Realität, etwa bei falschen Biografien oder erfundenen Zitaten.
Eine weitere Kategorie sind sogenannte "Arbitrary-Fact"-Halluzinationen: Aussagen über Fakten wie Geburtstage oder Dissertationstitel, die selten oder gar nicht im Trainingsmaterial vorkommen. Da es dafür kein erkennbares Muster gibt, geraten Sprachmodelle hier zwangsläufig in epistemische Unsicherheit – und raten.
Zur Eindämmung von Halluzinationen kombiniert OpenAI mehrere technische Ansätze: verstärkendes Lernen mit menschlichem Feedback, externe Tools wie Rechner oder Datenbanken, sowie Suchfunktionen (Retrieval-Augmented Generation). Ergänzt werden diese durch spezialisierte Subsysteme zur Faktenprüfung. Langfristig soll eine modulare Gesamtarchitektur – ein "System aus Systemen" – dafür sorgen, dass Sprachmodelle kontrollierter und verlässlicher antworten.
Modelle sollen Unsicherheit erkennen
Vollständig vermeiden lassen sich Halluzinationen laut OpenAI nicht. Künftig sollen Modelle aber erkennen, wenn sie keine verlässliche Antwort geben können – und dies auch mitteilen. Im Zweifel sollen sie externe Tools nutzen, um Hilfe bitten oder die Ausgabe abbrechen.
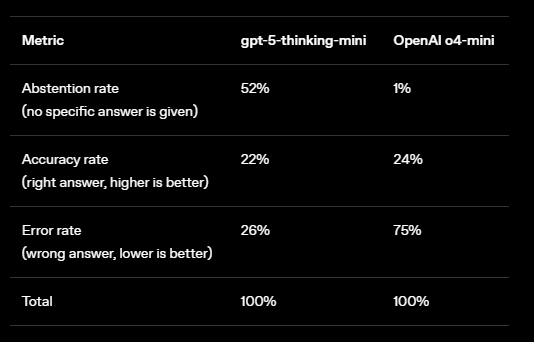
Das Verhalten soll sich stärker an menschlicher Unsicherheit orientieren: Auch Menschen wissen nicht alles, geben aber mitunter zu, wenn sie etwas nicht wissen, anstatt einfach zu antworten. Natürlich äußern sich auch Menschen manchmal trotzdem.
Bei LLMs liegt ein zentrales Problem laut OpenAI in den gängigen Bewertungsmethoden: Die meisten Benchmarks belohnen überhöhtes Selbstvertrauen und bestrafen Zurückhaltung. Evaluationsverfahren wie MMLU, GPQA oder SWE-bench setzen auf binäre Korrektheitsmetriken und geben keine Punkte für Antworten wie "Ich weiß es nicht".
Modelle, die ehrlich Unsicherheit kommunizieren, schneiden dort schlechter ab als solche, die systematisch raten, selbst wenn diese dabei halluzinieren. OpenAI spricht von einer "Epidemie", bei der Unsicherheit systematisch bestraft und Halluzination belohnt wird.
Als Gegenmaßnahme schlägt OpenAI vor, bestehende Benchmarks so zu überarbeiten, dass sie Unsicherheit gezielt abfragen und bewerten. Etwa durch Aufgabenformate, bei denen Modelle nur antworten sollen, wenn ihre Sicherheit über einem bestimmten Schwellenwert liegt. Andernfalls werden falsche Antworten explizit bestraft und „IDK“-Antworten (I don't know) nicht negativ gewertet. Solche "Vertrauensschwellen" könnten laut OpenAI ein objektiver Maßstab werden, um Modelle für angemessenes Verhalten zu belohnen statt für übertriebene Sicherheit.
Vor kurzem zeigte ein Stanford-Mathematikprofessor diesen Fortschritt: Er testet seit einem Jahr dasselbe ungelöste Problem an OpenAI-Modellen. Während frühere Versionen falsche Antworten gaben, erkannte das aktuelle Modell erstmals, dass es das Problem nicht lösen kann – und sagte das auch.
Auch beim schwierigsten Problem der diesjährigen Internationalen Mathematik-Olympiade blieb das Modell korrekt stumm. Die zugrunde liegenden Verbesserungen sollen in einigen Monaten in kommerziellen Modellen verfügbar sein.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.