Open-Source-Modell LongCat zeigt: Gute Bild-KI geht auch ohne Parameter-Flut
Das chinesische Tech-Unternehmen Meituan stellt mit LongCat-Image ein neues Open-Source-Bildmodell vor. Mit nur 6 Milliarden Parametern soll es deutlich größere Modelle bei der Textdarstellung und im Fotorealismus übertreffen. Der Schlüssel liegt in einer strengen Daten-Diät und einer speziellen Text-Darstellung.
Während Konkurrenten wie Tencent oder Alibaba auf massive Parameter-Skalierung setzen, geht das Team von Meituan einen effizienteren Weg. In ihrem technischen Bericht stellt die Forschungsgruppe LongCat-Image vor, ein Text-zu-Bild-Modell, das mit lediglich 6 Milliarden Parametern auskommt.

Aktuelle Mixture-of-Experts-Architekturen wie Hunyuan3.0 nutzen bis zu 80 Milliarden Parameter. Das LongCat-Team argumentiert, dass diese "rohe Gewalt" bei der Skalierung oft zu ineffizienter Hardware-Nutzung führt, ohne die Bildqualität proportional zu steigern. LongCat-Image setzt stattdessen auf eine Architektur, die dem populären Flux.1-dev ähnelt und auf einem hybriden MM-DiT (Multimodal Diffusion Transformer) basiert.
Dieser Ansatz verarbeitet Bild- und Textinformationen zunächst in zwei getrennten Attention-Pfaden. In den ersten Schichten bleiben die Datenströme separiert, um sie später gezielt zusammenzuführen. Das erlaubt eine präzisere Steuerung der Bildgenerierung durch den Text, ohne die Rechenlast unnötig aufzublähen.
Kampf gegen die "Plastik-Optik" durch strenge Filterung
Ein zentrales Problem aktueller Bild-KI ist laut den Forschern die Kontamination der Trainingsdaten durch bereits von KI generierte Bilder. Selbst ein kleiner Anteil solcher synthetischer Daten führe dazu, dass Modelle zu einer "plastikartigen" oder "fettigen" Textur konvergieren und in einem lokalen Optimum stecken bleiben. Das Modell lernt dann vereinfachte Muster statt echter Komplexität.
Um das zu verhindern, filterte das Team während des Pre-Trainings und des Mid-Trainings rigoros alle KI-generierten Inhalte aus dem Datensatz. Einen ähnlichen Ansatz verfolgte etwa Alibaba schon mit Qwen-Image. Erst in der späteren Fine-Tuning-Phase wurden handverlesene, hochwertige synthetische Daten zugelassen.
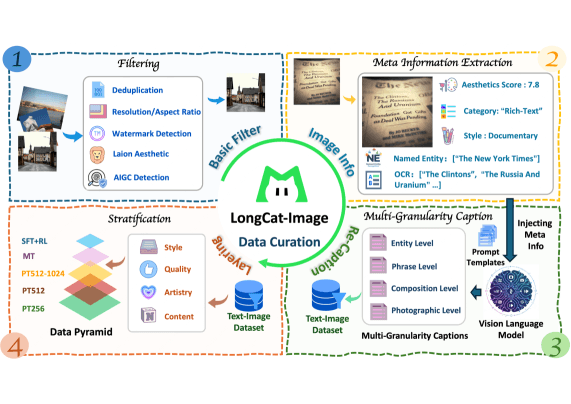
Zusätzlich führten die Entwickler im Reinforcement Learning (RL) eine neuartige Belohnungsfunktion ein: Ein Detektionsmodell für KI-Bilder bestraft den Generator, wenn das erzeugte Bild Artefakte aufweist. Das zwingt das Modell dazu, Texturen zu erzeugen, die der physischen Realität näherkommen und den Detektor "austricksen".
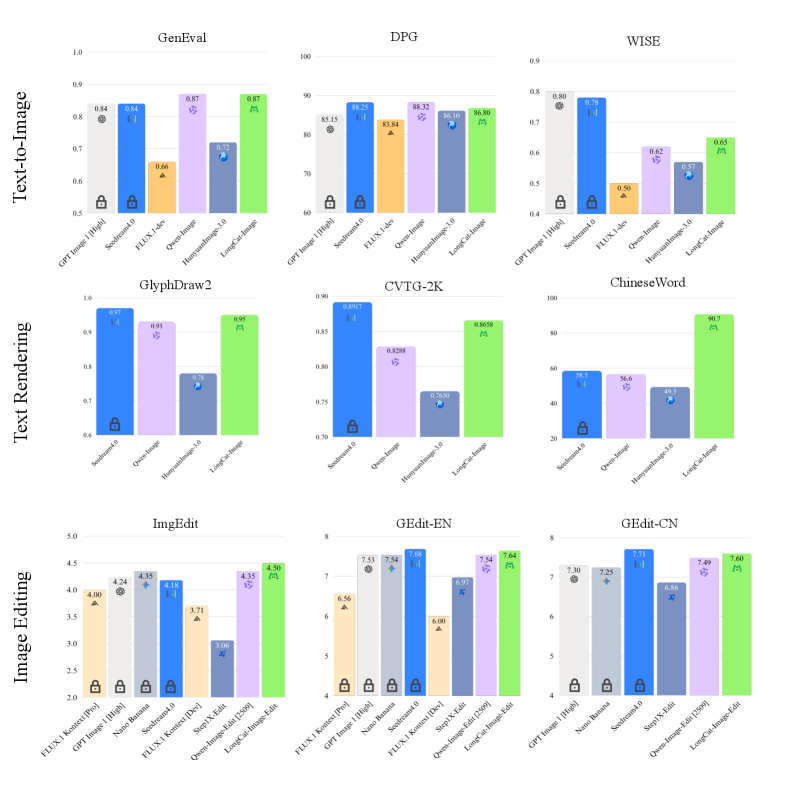
In internen und externen Benchmarks positioniert sich das 6B-Modell oft vor deutlich größeren Modellen wie Qwen-Image-20B oder HunyuanImage-3.0. Die Effizienz der Architektur ermöglicht zudem den Betrieb mit deutlich weniger VRAM, was die Hürden für die lokale Nutzung und Weiterentwicklung senkt.
Separate Text-Kodierung
Ein wesentliches Unterscheidungsmerkmal ist die Art und Weise, wie das Modell Text im Bild generiert. Die korrekte Darstellung von Schriftzügen scheitert bei vielen Modellen daran, dass sie Wörter als abstrakte Token (Silben oder Wortteile) verarbeiten, aber nicht wissen, aus welchen einzelnen Buchstaben diese bestehen.
LongCat-Image löst dies durch eine hybride Verarbeitung im Text-Encoder. Das Modell nutzt zwar Qwen2.5-VL-7B für das allgemeine Verständnis des Prompts, schaltet aber für spezifische Textwünsche um.

Sobald Text im Prompt in Anführungszeichen steht, wendet das Modell einen speziellen Character-Level-Tokenizer an. Das bedeutet, der Text innerhalb der Anführungszeichen wird nicht als semantisches Konzept, sondern Buchstabe für Buchstabe kodiert. Das reduziert laut den Autoren die "Gedächtnislast" des Modells erheblich, da es nicht für jedes Wort ein eigenes visuelles Muster auswendig lernen muss, sondern lernt, einzelne Glyphen zu konstruieren.
Separates Edit-Modell für Bildbearbeitung
Entgegen dem Trend, ein einziges Modell für Generierung und Bearbeitung zu trainieren, entwickelte das Team mit LongCat-Image-Edit ein separates Modell. Den Forschern zufolge verschlechterten die für das Editing-Training notwendigen synthetischen Daten die fotorealistische Qualität der reinen Bildgenerierung.

Das Editing-Modell basiert auf einem Checkpoint aus der mittleren Trainingsphase des Hauptmodells, da dieser Zustand noch "formbarer" sei als das fertig optimierte Endprodukt. Durch gemeinsames Training mit Generierungsaufgaben soll das Modell lernen, Instruktionen präzise zu folgen, ohne das visuelle Wissen über die Welt zu vergessen ("Catastrophic Forgetting").

Meituan stellt neben den finalen Gewichten für das Text-zu-Bild- und das Editing-Modell auch weitere Ressourcen auf GitHub und Hugging Face zur Verfügung. Das Paket umfasst Mid-Training-Checkpoints als Basis für Entwickler sowie den vollständigen Code für die Trainingspipeline, von der Vorbereitung bis zu den Reinforcement-Learning-Methoden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.