Meta-Forscher denkt die Transformer-Architektur für Sprachmodelle neu
Ein Meta-Forscher hat eine neue KI-Architektur entwickelt, die vorab Entscheidungen treffen kann, in welche Richtung der generierte Text gehen soll. Der sogenannte Free Transformer soll laut Forschungspapier besonders bei Programmier- und Mathematikaufgaben besser abschneiden.
François Fleuret von Meta erklärt das Problem anhand eines Generators für Filmkritiken. Ein Standard-Transformer schreibt Wort für Wort und merkt dabei allmählich, ob die Kritik positiv oder negativ wird. Er trifft diese Entscheidung nicht bewusst, sondern sie ergibt sich aus den gewählten Token.
Das führt laut der Studie zu mehreren Problemen. Die Berechnungen werden unnötig kompliziert, weil das Modell ständig raten muss, in welche Richtung der Text geht. Außerdem kann es durch einzelne falsche Wörter vom ursprünglichen Kurs abkommen.
Der Free Transformer löst dieses Problem, indem er vorab eine Entscheidung trifft. Im Filmkritik-Beispiel würde er zuerst festlegen, ob die Kritik positiv oder negativ werden soll, und dann entsprechende Token generieren.
Minimaler Aufwand für zusätzliche Funktionen
Die technische Umsetzung erfolgt durch eine zusätzliche Schicht in der Mitte des Transformer-Modells. Diese Schicht erhält während der Textgenerierung zufällige Eingabewerte und wandelt sie in strukturierte Entscheidungen um. Ein separater Encoder-Teil lernt während des Trainings, welche versteckten Entscheidungen zu welchen Texten passen.
Der Encoder funktioniert anders als der normale Textgenerator. Während der Standard-Transformer nur die bisherigen Wörter sehen kann, betrachtet der Encoder den kompletten Text auf einmal. So kann er globale Eigenschaften des Texts erkennen und entsprechende versteckte Entscheidungen treffen. Ein Umwandlungsmechanismus sorgt dafür, dass diese Entscheidungen in eine Form gebracht werden, die der Decoder verstehen kann.
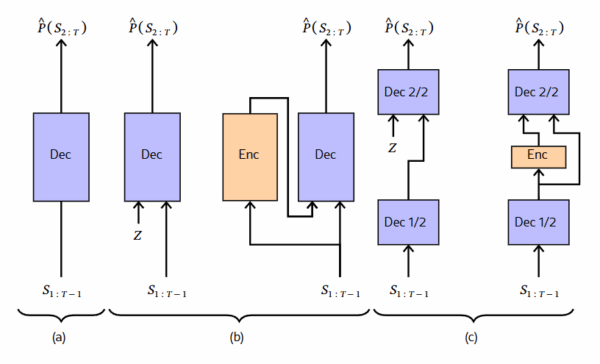
Durch geschickte Architekturaufteilung bleibt der zusätzliche Rechenaufwand gering. Der Encoder nutzt die ersten Verarbeitungsschritte des Standard-Modells mit und benötigt nur einen zusätzlichen Baustein. Laut der Studie erhöht sich dadurch der Rechenaufwand um lediglich etwa drei Prozent.
Das System kann aus mehr als 65 000 verschiedenen versteckten Zuständen wählen. Ein Kontrollverfahren sorgt dafür, dass nicht zu viel Information in den versteckten Entscheidungen gespeichert wird. Ohne diese Kontrolle könnte der Encoder "schummeln" und einfach den kompletten zu schreibenden Text im Voraus festlegen. Das würde das System beim praktischen Einsatz nutzlos machen.

Deutliche Verbesserungen bei komplexen Aufgaben
Der Forscher testete seine Architektur mit Modellen von 1,5 und 8 Milliarden Parametern auf 16 Standard-Benchmarks. Besonders bei Aufgaben, die logisches Denken erfordern, zeigte sich eine deutliche Verbesserung.
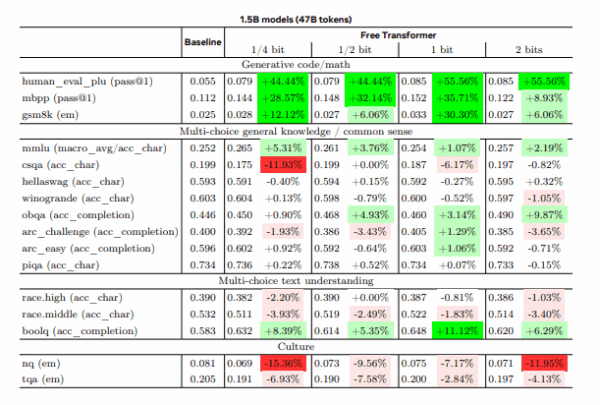
Bei der Code-Generierung erreichte das kleinere Modell mit weniger Trainingsdaten 44 Prozent bessere Ergebnisse als die Vergleichsversion. Bei Mathematik-Aufgaben verbesserte es sich um bis zu 30 Prozent. Das größere Modell, das mit deutlich mehr Daten trainiert wurde, zeigte geringere aber immer noch messbare Verbesserungen von 11 Prozent bei Code-Generation und 5 Prozent bei Wissensfragen.
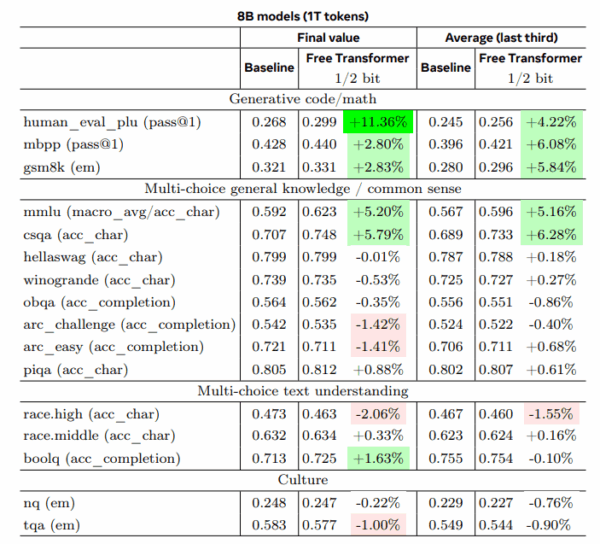
Fleuret führt die grundsätzlichen Verbesserungen darauf zurück, dass die versteckten Entscheidungen dem Modell helfen, komplexe Probleme strukturierter anzugehen. Anstatt jeden Schritt neu zu durchdenken, kann es eine übergeordnete Strategie festlegen und dann konsequent verfolgen.
Noch Raum für Optimierungen
Die Studie räumt ein, dass die Trainingsverfahren noch nicht optimal an die neue Architektur angepasst wurden. Der Forscher verwendete dieselben Einstellungen wie für die Standard-Modelle. Eine speziell angepasste Trainingsmethode könnte die Verbesserungen noch verstärken.
Auch die Skalierung auf größere Modelle bleibt unerforscht. Die Experimente beschränkten sich auf relativ kleine Modelle im Vergleich zu aktuellen Sprachmodellen mit hunderten Milliarden Parametern.
Fleuret sieht Potenzial für die Kombination seines Ansatzes mit anderen KI-Techniken. Während sein System versteckte Entscheidungen im Hintergrund trifft, könnten andere Verfahren zusätzlich sichtbare Denkschritte im generierten Text zeigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.