Meta stellt Hyperagents vor: KI-System verbessert den eigenen Verbesserungsprozess

Forschende bei Meta und mehreren Universitäten haben "Hyperagenten" entwickelt, die nicht nur Aufgaben lösen, sondern auch den Mechanismus optimieren, mit dem sie sich selbst verbessern. Das funktioniert über verschiedene Aufgabenbereiche hinweg und könnte den Weg zu sich selbst beschleunigender KI ebnen.
Selbstverbessernde KI-Systeme stoßen bislang an eine paradoxe Grenze: Der Mechanismus, der die Verbesserungen steuert, ist selbst von Menschen programmiert und bleibt während des gesamten Prozesses unverändert. Egal wie gut sich das System optimiert, es kann nie über die Möglichkeiten hinauswachsen, die dieser fixe Mechanismus zulässt. Ein Forschungsteam bei Meta, der University of British Columbia und weiteren Institutionen will diese Grenze mit sogenannten Hyperagenten aufheben.
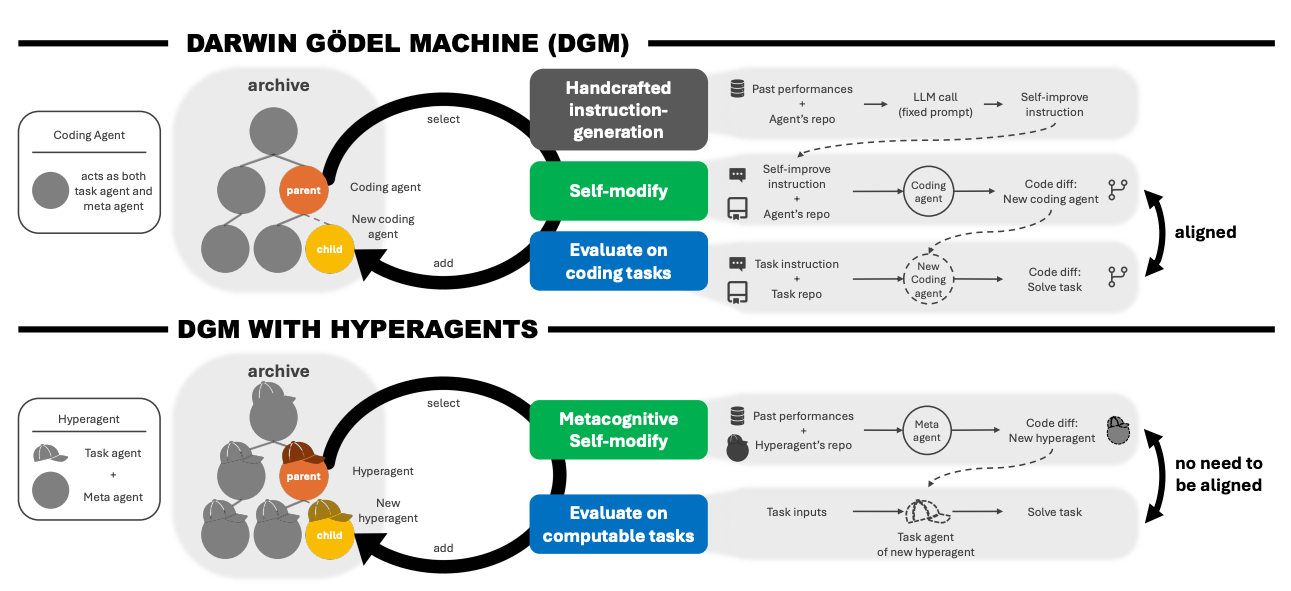
Ein Hyperagent vereint zwei Komponenten in einem einzigen, editierbaren Programm. Die erste löst eine konkrete Aufgabe, etwa das Bewerten eines wissenschaftlichen Papers oder das Entwerfen einer Belohnungsfunktion für einen Roboter.
Die zweite modifiziert den gesamten Agenten und erzeugt neue Varianten. Weil beide Teile im selben Code liegen, kann die zweite Komponente auch sich selbst umschreiben. Das System verbessert also nicht nur, wie es Aufgaben löst, sondern auch, wie es künftige Verbesserungen generiert.
Selbstverbesserung funktionierte bisher nur beim Programmieren
Das neue System baut auf der Darwin Gödel Machine (DGM) auf, einer Methode, die bereits gezeigt hat, dass sich ein Coding-Agent durch wiederholte Selbstmodifikation schrittweise verbessern kann. Der Agent erzeugt Varianten seines eigenen Codes, testet sie und speichert erfolgreiche Versionen in einem wachsenden Archiv als Sprungbretter für weitere Verbesserungen.
Beim Programmieren besteht eine natürliche Kopplung: Ein besserer Programmierer schreibt auch bessere Selbstmodifikationen. Außerhalb von Coding bricht diese Kopplung zusammen. Ein Agent, der wissenschaftliche Paper präziser bewertet, wird dadurch nicht automatisch geschickter darin, seinen eigenen Code umzuschreiben. Die originale DGM erreicht laut dem Paper bei Aufgaben jenseits des Programmierens ohne manuelle Anpassung nahezu null Leistung.
Die Hyperagenten umgehen dieses Problem, indem der Verbesserungsmechanismus selbst zum Gegenstand der Optimierung wird. Das Team nennt den daraus resultierenden Ansatz DGM-Hyperagents (DGM-H). Der evolutionäre Prozess mit dem Archiv bleibt erhalten, aber die Meta-Ebene ist nicht mehr fixiert.
Deutliche Fortschritte in vier Aufgabenbereichen
Das Team testet DGM-H in vier Bereichen und startet mit einem einfachen Hyperagenten, dessen Task-Agent zunächst nur einen einzelnen Sprachmodell-Aufruf nutzt. Beim Polyglot-Coding-Benchmark verbessert sich DGM-H von 0,084 auf 0,267 und liegt damit auf dem Niveau der originalen DGM, obwohl das System nicht speziell für Coding konstruiert wurde.
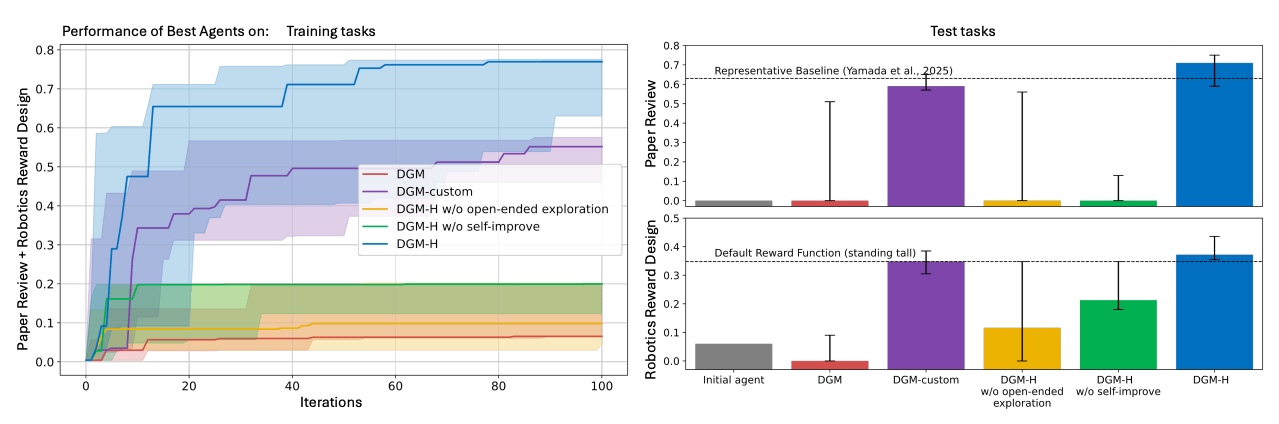
Beim Paper-Review, wo der Agent vorhersagen muss, ob eine KI-Konferenz ein Paper annimmt oder ablehnt, steigt die Testleistung von 0,0 auf 0,710. Mehrere der besten Agenten übertreffen eine etablierte statische Baseline, die bei 0,630 liegt.
Beim Robotik-Reward-Design, wo der Agent Belohnungsfunktionen für einen vierbeinigen Roboter in einer Physiksimulation entwirft, klettert die Leistung von 0,060 auf 0,372. Laut dem Paper generiert DGM-H dabei fast immer Belohnungsfunktionen, die den Roboter zum Springen bringen, statt ihn im lokalen Optimum des bloßen Aufrecht-Stehens feststecken zu lassen.
Ablationsstudien sprechen dafür, dass beide Kernkomponenten notwendig sind: Ein fixer Meta-Agent führt nur zu wenig bis keiner Verbesserung, und ohne Archiv offener Exploration bleibt der Fortschritt ebenfalls stark begrenzt.
Verbesserungsstrategien lassen sich auf neue Aufgabenbereiche übertragen
Das vielleicht wichtigste Ergebnis betrifft den Transfer zwischen Domänen. Hyperagenten, die auf Paper-Review und Robotik trainiert wurden, können in einem gänzlich neuen Bereich, der Bewertung von Olympiade-Mathematik-Lösungen, signifikant bessere Task-Agenten erzeugen. Gemessen an der vom Team eingeführten imp@50-Metrik, die den Leistungsgewinn nach 50 Iterationen erfasst, erreichen Transfer-Hyperagenten einen Wert von 0,630. Initiale Agenten und Transfer-Agenten der originalen DGM bleiben bei 0,0.
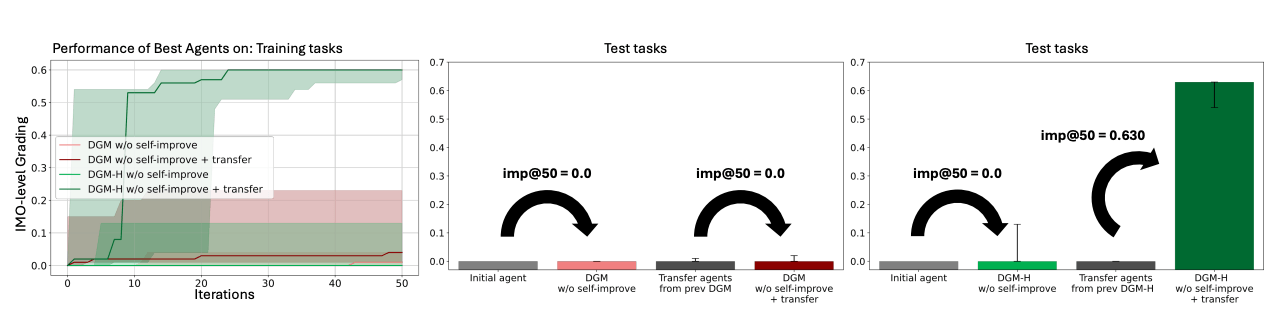
DGM-H lernt also nicht nur, bestimmte Aufgaben besser zu lösen, sondern erwirbt allgemeine Selbstverbesserungsfähigkeiten, die auch in unbekannten Kontexten greifen. Die Differenz ist statistisch signifikant. Beim Versuch, diese Verbesserungen über mehrere Durchläufe hinweg zu akkumulieren, zeigt sich ein höherer Median bei Transfer-Agenten; allerdings ist dieser Unterschied nicht mehr statistisch signifikant.
Das System baut sich eigenständig Werkzeuge für bessere Selbstverbesserung
Eine qualitative Analyse der Code-Änderungen offenbart, dass DGM-H ohne explizite Anweisung eine Reihe von Infrastruktur-Komponenten entwickelt. So entsteht etwa ein Performance-Tracker, der Leistungsdaten über Generationen hinweg speichert und Verbesserungstrends berechnet. Daneben baut das System einen persistenten Speicher auf, der nicht bloß Zahlen festhält, sondern synthetisierte Einsichten formuliert.
Ein Beispiel aus den Experimenten: "Gen55 bietet die beste Genauigkeit, ist aber zu streng. Gen64 bietet eine verbesserte Ausgewogenheit, jedoch eine geringere Genauigkeit. Kritisches Denkvermögen von Gen55 mit der Ausgewogenheit von Gen64 kombinieren."
Beim Paper-Review erkennt das System eigenständig, wenn seine Vorhersagen kollabieren, etwa wenn 94 Prozent aller Bewertungen auf "Accept" lauten, und korrigiert dieses Verhalten. Im Robotik-Bereich baut DGM-H schrittweise eine interne Wissensbasis auf, die gültige Umgebungsvariablen, Constraints und Skalierungsheuristiken dokumentiert und so Kompilierungsfehler eliminiert.
In vorläufigen Experimenten, in denen das System auch seine eigene Auswahllogik verändern darf, findet es eigenständig Strategien, die zwischen dem Nutzen bewährter Lösungen und dem Ausprobieren neuer Varianten abwägen. Diese selbst gefundenen Strategien sind besser als eine zufällige Auswahl, kommen aber bisher nicht an sorgfältig von Hand entworfene Mechanismen heran.
Sicherheitsvorkehrungen und offene Risiken
Alle Experimente liefen in abgeschotteten Umgebungen mit begrenzten Ressourcen, eingeschränktem Internetzugang und menschlicher Aufsicht. Die Forschenden warnen jedoch, dass solche Schutzmaßnahmen an ihre Grenzen stoßen könnten, je leistungsfähiger selbstverbessernde Systeme werden.
Unter anderem könnten sich solche Systeme schneller weiterentwickeln, als Menschen sie prüfen können, und Agenten könnten Schwächen in der Bewertung ausnutzen, um auf dem Papier besser abzuschneiden, ohne die eigentliche Aufgabe tatsächlich besser zu lösen.
Technische Einschränkungen bleiben ebenfalls bestehen. Das System arbeitet mit einer fixen Aufgabenverteilung und kann die äußere Optimierungsschleife nicht verändern. Der Code ist auf GitHub verfügbar.
Erst kürzlich hatte das chinesische KI-Unternehmen MiniMax mit M2.7 ein Modell vorgestellt, das in mehr als 100 autonomen Runden seinen eigenen Trainingsprozess verbessert haben soll. Auch OpenAI berichtete, dass das Coding-Modell Codex 5.3 die eigene Entwicklung signifikant beschleunigt habe.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.