Metas Thinking LLMs sollen ohne teure Trainingsdaten "denken" lernen
Wissenschaftler von Meta, Berkeley und NYU haben eine neue Methode entwickelt, um Sprachmodelle zum "Denken" vor dem Antworten zu bringen. Der Ansatz soll die Leistung bei allgemeinen Aufgaben verbessern.
Forscher von Meta FAIR, der University of California, Berkeley und der New York University haben eine neue Methode namens "Thought Preference Optimization" (TPO) entwickelt, um große Sprachmodelle (LLMs) zum "Denken" vor dem Antworten zu bringen. Laut der Studie soll dieser Ansatz die Leistung der Modelle bei allgemeinen Aufgaben verbessern, nicht nur bei mathematischen oder logischen Problemen.
"Wir argumentieren, dass 'Denken' einen breiten Nutzen haben sollte", erklären die Forscher. "Zum Beispiel können bei einer kreativen Schreibaufgabe interne Gedanken zur Planung der Gesamtstruktur und der Charaktere verwendet werden."
Bisher wurde die dafür häufig verwendete Technik des "Chain-of-Thought" (CoT) Promptings hauptsächlich für Mathematik- und Logikaufgaben eingesetzt. Eine Ausnahme bildet hier OpenAIs neues o1-Modell, das die Forscher als Unterstützung für ihre These anführen.
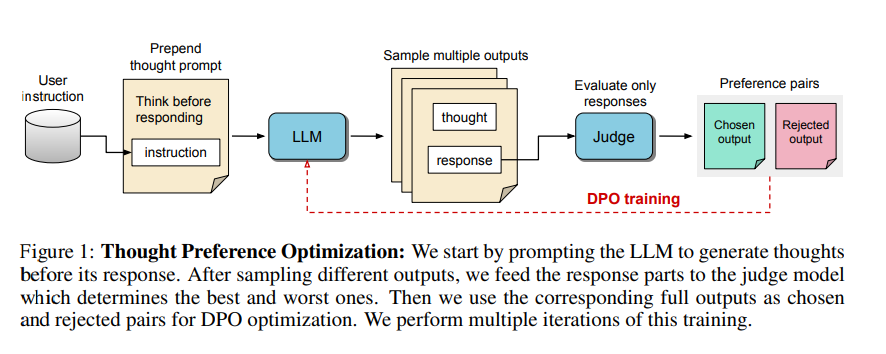
Training ohne zusätzliche Daten
Eine Herausforderung beim Training von Modellen zum Denken ist der Mangel an Trainingsdaten mit menschlichen Gedankenprozessen. TPO umgeht dieses Problem, indem es den Denkprozess des Modells iterativ optimiert, ohne zusätzliche Daten zu benötigen.
Die Methode funktioniert wie folgt:
1. Das Modell wird aufgefordert, vor der eigentlichen Antwort einen Gedankenprozess zu generieren.
2. Es werden mehrere solcher Ausgaben erzeugt.
3. Ein Bewertermodell beurteilt nur die Antworten, nicht die Gedanken.
4. Anhand dieser Bewertungen wird das Modell mittels Präferenzoptimierung trainiert.
Es werden also nicht die Gedankenschritte bewertet - nur ihr Ergebnis. Die Hoffnung der Forscher: Bessere Antworten erfordern bessere Gedankenschritte - das Modell lernt so implizit Antworten zu geben, die besseren Gedankenschritten folgen.
Es ist unklar, wie genau das o1-Modell von OpenAI trainiert wurde, aber es ist sehr wahrscheinlich, dass qualitativ hochwertige Trainingsdaten mit explizit dargelegten Gedankengängen Teil der Trainingsdaten von o1 waren. Außerdem "denkt" o1 aktiv, d.h. es gibt seine Gedankenschritte als Text aus, der wiederum analysiert bzw. ausgewertet wird. Damit unterscheidet sich die TPO von Meta deutlich von der Methode von OpenAI.
Verbesserungen in verschiedenen Kategorien
Die Forscher evaluierten ein Llama 3 8B Modell auf den Benchmarks AlpacaEval und Arena-Hard, die allgemeine Instruktionsbefolgung testen. TPO erreichte eine starke Gewinnrate von 52,5% bzw. 37,3% und übertraf damit das direkte LLM-Pendant ohne explizites Denken.
Es zeigte sich auch, dass das Denken nicht nur bei Themen wie Argumentieren und Problemlösen hilft, sondern auch zu besseren Leistungen in Kategorien führt, die typischerweise nicht mit Argumentation in Verbindung gebracht werden, wie allgemeines Wissen, Marketing und Gesundheit.
"Dies eröffnet eine neue Möglichkeit, Thinking LLMs zu entwickeln, die auf allgemeine Instruktionsbefolgung abzielen, anstatt sich auf engere technische Bereiche zu spezialisieren", schließen die Forscher.
Allerdings räumen die Wissenschaftler ein, dass ihr experimenteller Aufbau nicht für mathematische Aufgaben geeignet ist. Tatsächlich verschlechterte sich die Leistung bei mathematischen Problemen im Vergleich zum Ausgangsmodell.
Zukünftige Arbeiten könnten sich darauf konzentrieren, die Länge der Gedanken steuerbarer zu machen und die Auswirkungen des Denkens auf größere Modelle zu untersuchen. Die Forscher hoffen, dass ihre Arbeit zu einer breiteren Anwendung von Thinking LLMs in nicht-mathematischen Bereichen führen wird.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.