Microsoft stellt schnelleres Phi-Denk-Modell mit bis zu 10x höherem Token-Durchsatz vor

Microsoft hat Phi-4-mini-flash-reasoning vorgestellt, ein neues KI-Modell für Szenarien mit begrenzter Rechenleistung, Speicher und Latenz. Das Modell soll Fähigkeiten zur Schlussfolgerung auf Edge-Geräte, mobile Anwendungen und andere ressourcenbeschränkte Umgebungen bringen.
Das neue Modell verfügt über 3,8 Milliarden Parameter und ist für mathematisches Reasoning optimiert. Es baut auf der im Dezember vorgestellten Phi-4-Familie auf.
Neue Architektur mit "Gated Memory Unit"
Die Grundlage von Phi-4-mini-flash-reasoning ist die SambaY-Architektur, die für dieses Modell um "differenzielle Aufmerksamkeit" erweitert wurde. Deren zentrale Innovation ist die Gated Memory Unit (GMU), ein Mechanismus, der die Effizienz des Modells drastisch verbessert.
Herkömmliche Transformer-Architekturen verwenden in jeder Schicht aufwendige Attention-Mechanismen, um die Relevanz verschiedener Input-Teile zu bewerten. Die GMU reduziert diese Komplexität erheblich: Statt rechenintensiver Cross-Attention-Operationen nutzt sie eine elementweise Multiplikation zwischen dem aktuellen Layer-Input und einem Speicherzustand aus einer vorherigen Schicht.
Diese Vereinfachung ermöglicht eine dynamische Neukalibrierung der Token-Mischung basierend auf dem aktuellen Kontext, ohne die hohen Rechenkosten traditioneller Attention-Mechanismen.
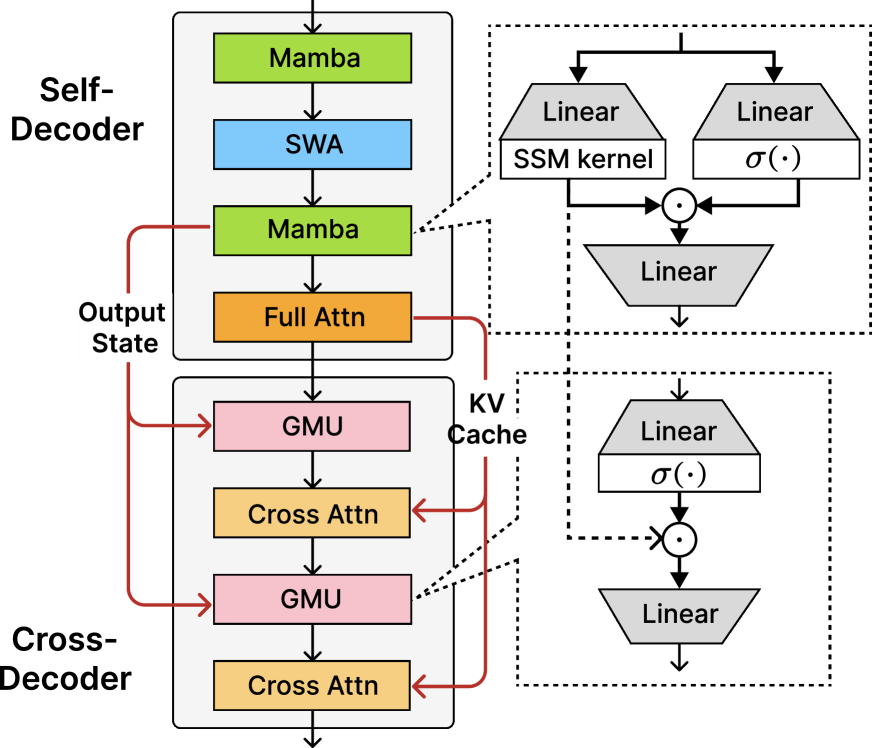
Die Architektur ersetzt die Hälfte der Cross-Attention-Schichten mit GMUs und reduziert dadurch den Speicherbedarf erheblich. Während bei herkömmlichen Modellen die Datentransfers zwischen Arbeitsspeicher und Prozessor mit der Sequenzlänge linear ansteigen, bleibt dieser Aufwand bei der SambaY-Architektur weitgehend konstant.
Deutliche Performance-Verbesserungen
Die architektonischen Änderungen führen zu beeindruckenden Leistungssteigerungen: Laut Microsoft erreicht Phi-4-mini-flash-reasoning einen bis zu zehnmal höheren Durchsatz sowie eine durchschnittliche Latenzreduzierung um das Zwei- bis Dreifache im Vergleich zu seinem Vorgänger. Die veröffentlichten Ergebnisse erzielte Phi-4-mini-flash-reasoning jedoch auf einer industriellen GPU – nicht auf einem ressourcenschwachen Gerät, für das das Modell eigentlich optimiert ist.
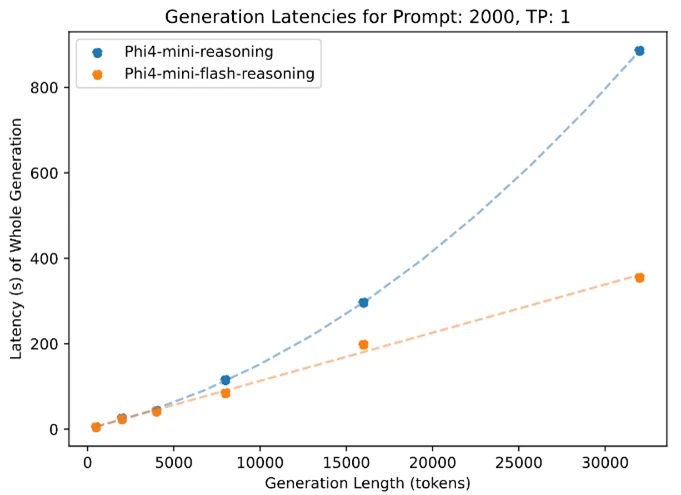
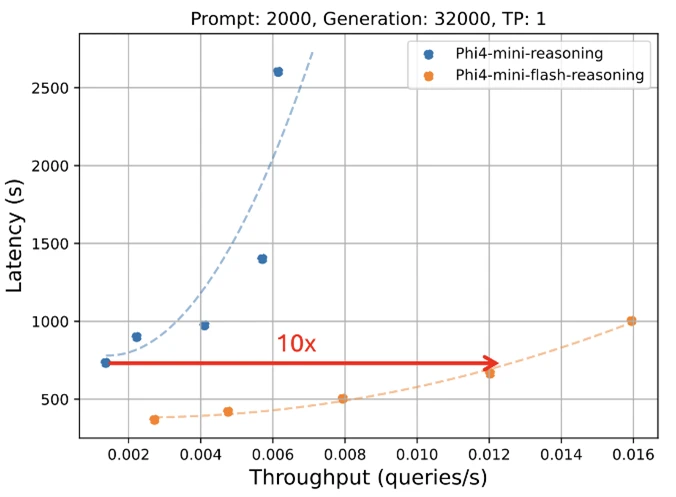
Ein Vorteil von Phi-4-mini-flash-reasoning zeigt sich zudem bei der Verarbeitung langer Kontexte. Das Modell unterstützt eine Kontextlänge von bis zu 64.000 Token und behält dabei seine Leistungsfähigkeit auch bei maximaler Auslastung bei.
Laut Microsoft profitiert das Modell von der effizienten SambaY-Architektur, die auch bei längeren Sequenzen eine konstante Verarbeitungsgeschwindigkeit ermöglicht. Dies ist ein deutlicher Vorteil gegenüber herkömmlichen Transformer-Modellen, die bei steigender Kontextlänge typischerweise an Performance verlieren.
Flash-Variante übertrifft Basismodell
Laut dem technischen Paper wurde Phi-4-mini-flash mit fünf Billionen Token aus dem gleichen Datenkorpus wie Phi-4-mini trainiert, der teilweise aus synthetischen Daten besteht. Das Training erfolgte auf 1.000 A100-GPUs über 14 Tage.
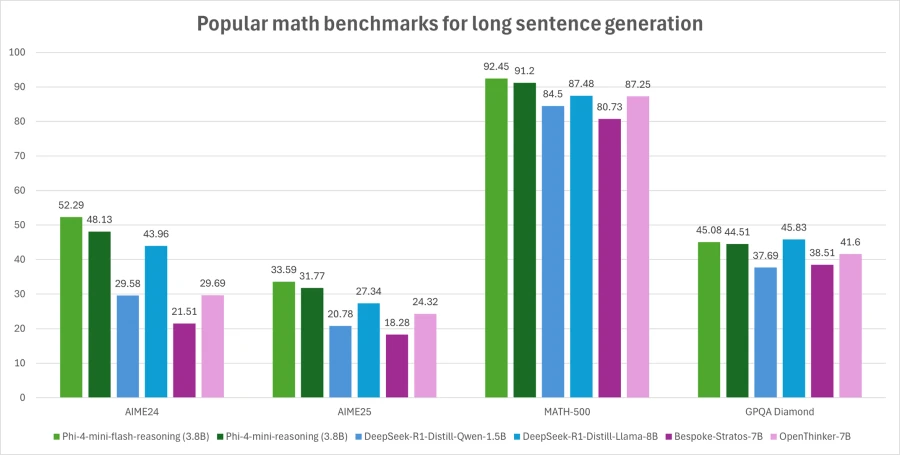
In umfangreichen Tests übertrifft das neue Modell seinen Vorgänger in nahezu allen Bereichen. Besonders deutlich zeigen sich die Verbesserungen bei wissensintensiven Aufgaben und Programmieraufgaben, wo das Modell mehrere Prozentpunkte zulegt. Auch bei mathematischen Aufgaben, Code-Generierung und wissenschaftlichen Reasoning-Aufgaben schneidet Phi-4-mini-flash-reasoning merklich besser ab - und das ohne die aufwendige Reinforcement-Learning-Stufe des Vorgängers.
Das Modell ist unter anderem auf Hugging Face verfügbar und Microsoft stellt Code-Beispiele im Phi Cookbook zur Verfügung. Die Trainingscodebase wurde auf GitHub unter Open-Source-Lizenz veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.