Microsofts "DIFF Transformer" verspricht effizientere LLMs mit weniger Halluzinationen

Microsoft Research hat eine neue KI-Architektur namens "Differential Transformer" (DIFF Transformer) entwickelt, die die Aufmerksamkeit auf relevante Kontexte verstärken und gleichzeitig Störungen reduzieren soll. Laut den Forschern zeigt der Ansatz Verbesserungen in verschiedenen Bereichen der Sprachverarbeitung.
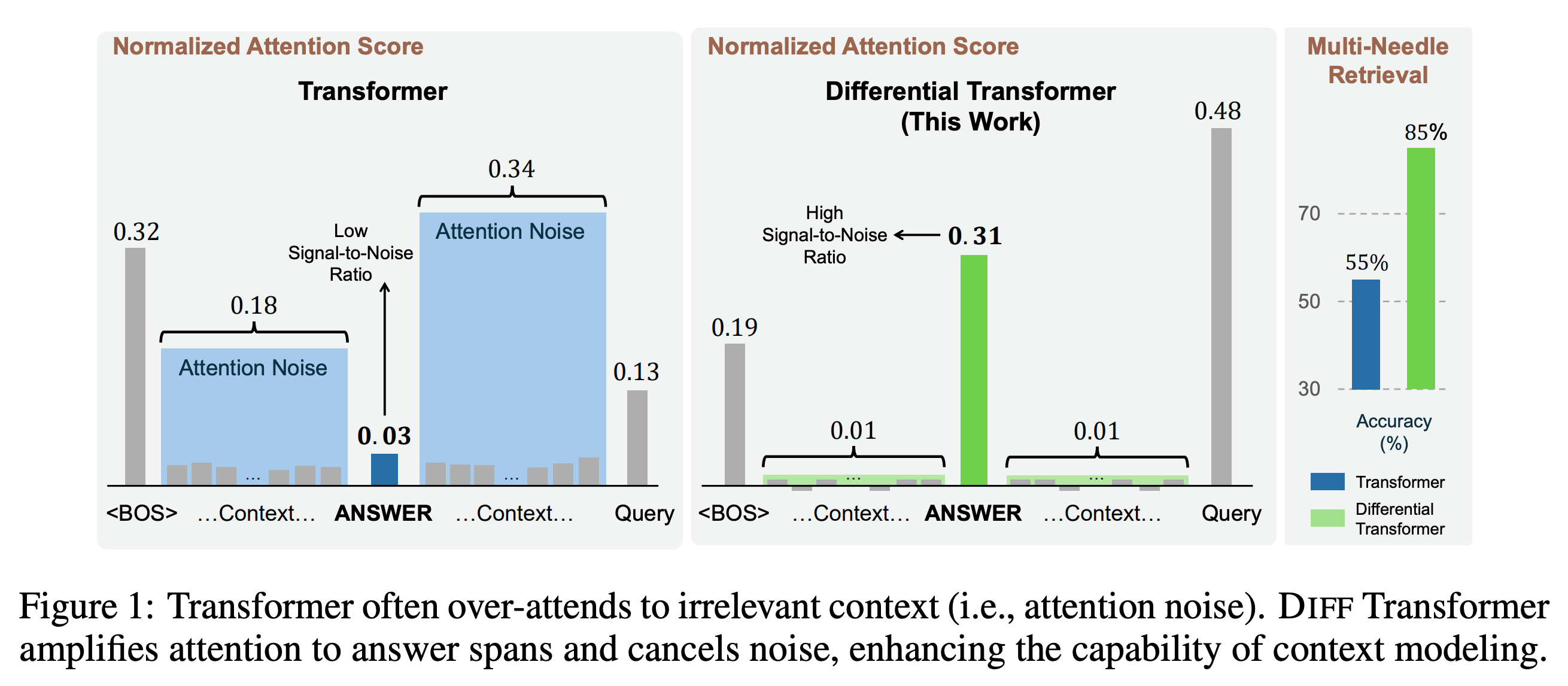
Kernstück des DIFF Transformers ist die sogenannte "differenzielle Aufmerksamkeit". Dabei werden zwei separate Softmax-Aufmerksamkeitskarten berechnet und anschließend voneinander subtrahiert. Die Forscher erklären, dass durch diese Subtraktion gemeinsames Rauschen in beiden Aufmerksamkeitskarten eliminiert wird - ähnlich der Funktionsweise von Noise-Cancelling-Kopfhörern.
"Transformer-Modelle neigen dazu, irrelevanten Kontexten zu viel Aufmerksamkeit zu schenken", so das Forschungsteam. Dies führe zu Problemen beim genauen Abrufen von Schlüsselinformationen. Der DIFF Transformer soll dieses Problem durch seinen neuartigen Aufmerksamkeitsmechanismus beheben.
DIFF Transformer zeigt mehr Leistung mit weniger Daten
In Tests zeigte sich, dass der DIFF Transformer mit etwa 65 Prozent der Modellgröße oder Trainingsdaten eine vergleichbare Leistung wie herkömmliche Transformer erreicht. Bei einem 3-Milliarden-Parameter-Modell, trainiert auf einer Billion Token, übertraf der DIFF Transformer laut der Studie Varianten mit etablierter Transformer-Architektur.
Besonders bei der Verarbeitung längerer Kontexte von bis zu 64.000 Token zeigten sich Vorteile: In Tests zur Extraktion von Schlüsselinformationen aus langen Texten ("Needle in a haystack") schnitt der DIFF Transformer deutlich besser ab als herkömmliche Modelle. Bei der Positionierung wichtiger Informationen in der ersten Hälfte eines 64.000 Token langen Kontexts erzielte das neue Modell laut den Forschern eine um bis zu 76 Prozent höhere Genauigkeit.
Weniger Halluzinationen, robusteres Lernen, bessere Quantisierung
Ein weiterer Vorteil des DIFF Transformers liegt in der Reduzierung von Halluzinationen - einem häufigen Problem bei großen Sprachmodellen. Bei der Zusammenfassung von Texten aus Datensätzen wie XSum, CNN/DM und MultiNews zeigte der DIFF Transformer eine um 9 bis 19 Prozentpunkte höhere Genauigkeit als ein vergleichbarer Standard-Transformer. Ähnliche Verbesserungen wurden bei Frage-Antwort-Aufgaben beobachtet.
Auch beim kontextuellen Lernen erwies sich die neue Architektur als robuster gegenüber Veränderungen in der Reihenfolge der Beispiele - ein bekanntes Problem bei herkömmlichen Modellen.
Die Forscher berichten zudem von Vorteilen bei der Quantisierung von KI-Modellen. Bei der Quantisierung werden die kontinuierlichen Werte der Modellparameter auf eine begrenzte Anzahl diskreter Werte reduziert, um die Modellgröße zu verringern und die Inferenzgeschwindigkeit zu erhöhen. Der DIFF Transformer reduziert Ausreißer-Aktivierungen, die eine Herausforderung für die effiziente Komprimierung darstellen. Bei einer extremen Quantisierung auf 4 Bit erreichte der DIFF Transformer eine um etwa 25 Prozentpunkte höhere Genauigkeit als ein Standard-Transformer.
Trotz dieser Vorteile ist der Durchsatz des DIFF Transformers laut der Studie nur etwa 5 bis 12 Prozent geringer als der eines vergleichbaren herkömmlichen Transformers. Die Forscher sehen in der neuen Architektur daher eine vielversprechende Grundlage für zukünftige große Sprachmodelle.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.