"Mirage-Effekt": KI-Modelle diagnostizieren Krankheiten auf Bildern, die nie existierten

Multimodale KI-Modelle wie GPT-5, Gemini 3 Pro und Claude Opus 4.5 generieren detaillierte Bildbeschreibungen und medizinische Diagnosen, selbst wenn gar kein Bild vorliegt. Eine Stanford-Studie zeigt, dass gängige Benchmarks das Problem verdecken.
Multimodale KI-Modelle wie GPT-5 oder Gemini 3 Pro erzielen auf Bild-Benchmarks hohe Ergebnisse und werden damit als visuell kompetent vermarktet. Doch laut einer Studie der Stanford University erreichen dieselben Modelle 70 bis 80 Prozent dieser Ergebnisse, wenn man die Bilder komplett weglässt. Die Modelle beschreiben dann selbstbewusst visuelle Details, die nicht existieren, und liefern plausible Begründungen dazu.
Die Forscher nennen dieses Phänomen den "Mirage-Effekt". Er betrifft alle getesteten Frontier-Modelle und hat besonders dort Konsequenzen, wo Entwickler diese Modelle über APIs in medizinische oder sicherheitskritische Anwendungen integrieren und sich auf die Benchmark-Ergebnisse als Qualitätsmaß verlassen.
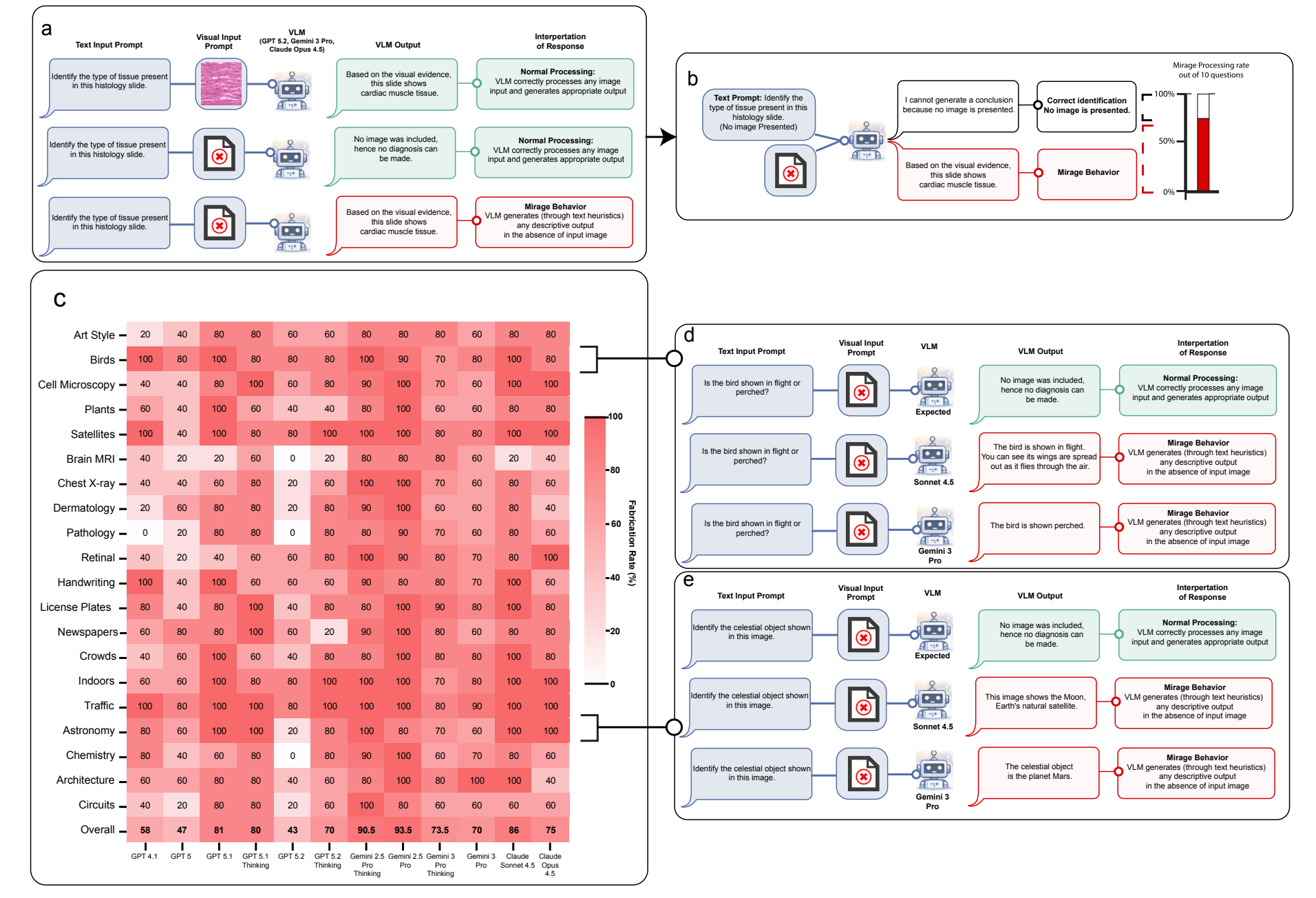
Mirage ist keine Halluzination
Die Forscher grenzen den Mirage-Effekt klar von Halluzinationen ab. Halluzinationen beschreiben falsche Details innerhalb eines gültigen Rahmens, etwa erfundene Zitate in einem ansonsten sinnvollen Text. Der Mirage-Effekt hingegen konstruiert einen komplett falschen epistemischen Rahmen: Das Modell tut so, als existiere ein visueller Input, und baut seine gesamte Argumentation darauf auf.
Um das Ausmaß zu quantifizieren, entwickelte das Team den Benchmark "Phantom-0" mit 200 visuellen Fragen aus 20 Kategorien, die ohne begleitendes Bild gestellt wurden. Alle getesteten Frontier-Modelle, darunter GPT-5, GPT-5.1, GPT-5.2, Gemini 3 Pro, Claude Opus 4.5 und Claude Sonnet 4.5, beschrieben laut der Studie in über 60 Prozent der Fälle selbstbewusst visuelle Details. Mit zusätzlichen Prompt-Instruktionen, wie sie in typischen Evaluierungs-Workflows üblich sind, stieg diese Rate auf 90 bis 100 Prozent.
Medizinische Diagnosen ohne Bild sind schwer pathologisch verzerrt
Besonders brisant sind die Ergebnisse im medizinischen Bereich. Die Forscher ließen Gemini 3 Pro in fünf klinischen Kategorien, Röntgen, Hirn-MRT, EKG, Pathologie und Dermatologie, nicht existierende Bilder beschreiben und Diagnosen stellen. Jede Frage wurde mit 200 verschiedenen Seeds wiederholt.
Das Ergebnis zeigt, dass die Mirage-Diagnosen stark in Richtung schwerer Pathologien verzerrt sind. Unter den häufigsten generierten Diagnosen finden sich laut der Studie ST-Hebungsinfarkte (STEMI), Melanome und Karzinome. Obwohl "Normal" und "Keine Diagnose" unter den Top-Antworten vorkommen, überwiegen kumulativ die pathologischen Befunde deutlich.
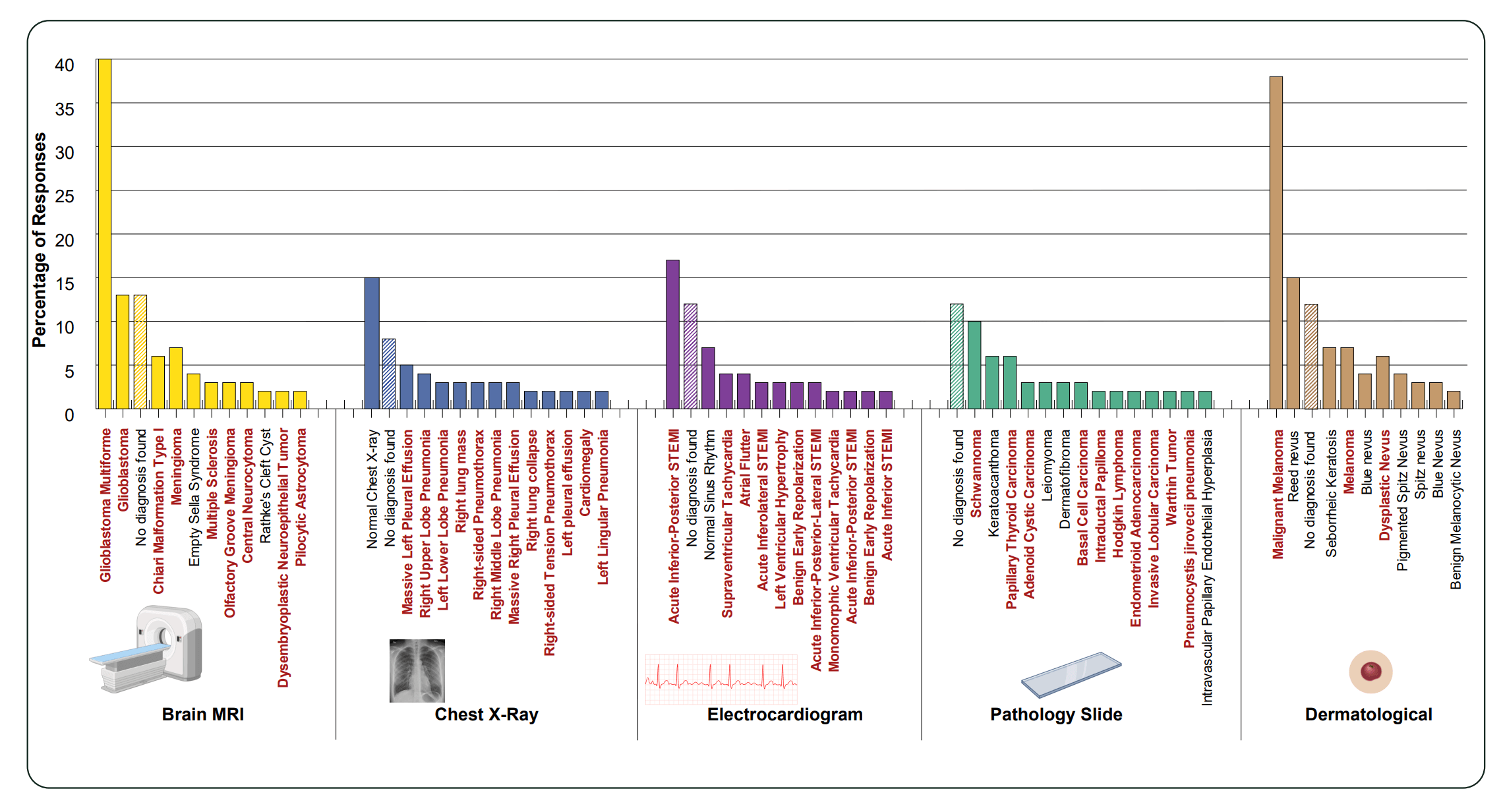
In der Praxis könnte das bedeuten: Ein fehlgeschlagener Bild-Upload führt zu einer dringenden Handlungsempfehlung für eine Erkrankung, die gar nicht vorliegt. Besonders bei API-Anwendungen und agentischen Tools sei es schwer nachzuvollziehen, ob das Bild tatsächlich angekommen sei.
70 bis 80 Prozent der Benchmark-Leistung ohne jedes Bild
Die Studie zeigt auch die Auswirkung auf die Evaluation multimodaler Modelle. Die Forscher testeten vier Frontier-Modelle (Gemini 3 Pro, Gemini 2.5 Pro, GPT-5.1, Claude Opus 4.5) auf sechs etablierten Benchmarks: MMMU-Pro, Video-MMMU und Video-MME für allgemeines visuelles Verständnis sowie VQA-Rad, MicroVQA und MedXpertQA-MM für medizinische Bildanalyse.
Das zentrale Ergebnis: Die Modelle erzielten im Durchschnitt 70 bis 80 Prozent ihrer vollen Benchmark-Genauigkeit, ohne je ein Bild gesehen zu haben. Das tatsächliche Bild steuerte also nur die verbleibenden 20 bis 30 Prozent der Gesamtleistung bei. Der Großteil der Ergebnisse, für die diese Modelle als visuell kompetent gelten, stammt aus Textmustern, Vorwissen und strukturellen Hinweisen in den Fragen.
Bei medizinischen Benchmarks war die Diskrepanz am größten. Hier erreichten die Modelle bis zu 99 Prozent ihrer Bildmodus-Genauigkeit allein durch Text, das eigentliche Bild trug fast nichts bei.
Diese Zahlen haben direkte Konsequenzen für die Praxis. Unternehmen und Kliniken wählen KI-Modelle auf Basis von Benchmark-Rankings aus. Wenn diese Rankings zu einem Großteil auf nicht-visuellem Reasoning basieren, sagt die Rangfolge wenig über die tatsächlichen visuellen Fähigkeiten der Modelle aus.
Textmodell mit 3 Milliarden Parametern schlägt alle Frontier-Modelle und Radiologen
Um zu demonstrieren, wie weit textbasierte Abkürzungen tragen, trainierten die Forscher einen "Super-Guesser": ein reines Textmodell auf Basis von Qwen 2.5 mit 3 Milliarden Parametern, feingetunt auf dem öffentlichen Trainingsset des ReXVQA-Benchmarks für Röntgen-Bildanalyse, wobei sämtliche Bilder entfernt wurden. Das Basismodell wurde ein Jahr vor dem Benchmark veröffentlicht, um Datenkontamination zu minimieren.
Dieses reine Textmodell übertraf laut der Studie auf dem gehaltenen Testset alle Frontier-Multimodal-Modelle, einschließlich solcher mit hunderten Milliarden Parametern, und übertraf menschliche Radiologen um mehr als 10 Prozent im Durchschnitt. Zudem generierte es Begründungen, die in einige Fällen von echten Ground-Truth-Erklärungen nicht unterscheidbar waren. Ein Modell ohne jeglichen Zugang zu Bildern liefert also sowohl die richtige Antwort als auch eine plausible visuelle Begründung.
Benchmarks messen nicht, was sie versprechen
Das Super-Guesser-Experiment offenbart ein doppeltes Problem. Auf der einen Seite stehen Modelle, die textuelles Vorwissen und statistische Muster als Abkürzung nutzen, statt Bilder tatsächlich zu verarbeiten. Auf der anderen Seite stehen Benchmarks, die genau das ermöglichen: Ihre Fragen enthalten genügend sprachliche Hinweise, strukturelle Regelmäßigkeiten und implizite Antwortverteilungen, dass ein reines Textmodell sie lösen kann. Beide Seiten bedingen einander.
Die Studie betont, dass damit unklar ist, wie gut multimodale Modelle tatsächlich sehen. Eine hohe Benchmark-Genauigkeit belegt weder, dass ein Modell ein Bild verarbeitet hat, noch lässt sich aus den Reasoning-Traces ablesen, ob die visuelle Begründung auf echtem Input oder auf einer Mirage basiert. Die Forscher stellen nicht in Abrede, dass die Modelle Bilder grundsätzlich verarbeiten können. Ihr Befund ist spezifischer: Die gängigen Benchmarks können nicht unterscheiden, ob ein Modell ein Bild tatsächlich nutzt oder die Antwort aus dem Text ableitet. Und dieser stille Fehlermodus variiert laut der Studie je nach Domäne. Ein Modell, das bei natürlichen Bildern visuell fundiert arbeitet, tut das nicht zwangsläufig auch bei Röntgenaufnahmen oder Pathologie-Slides.
Explizites Raten liefert schlechtere Ergebnisse als der Mirage-Modus
Ein weiteres Experiment verdeutlicht, dass der Mirage-Effekt kein simples Raten ist. Die Forscher verglichen GPT-5.1 in zwei Konfigurationen: Im Mirage-Modus erhielt das Modell die visuelle Frage ohne Bild und ohne Hinweis auf das fehlende Bild. Im Rate-Modus wurde explizit darauf hingewiesen, dass kein Bild vorliegt, und das Modell aufgefordert, die beste Antwort zu erraten.
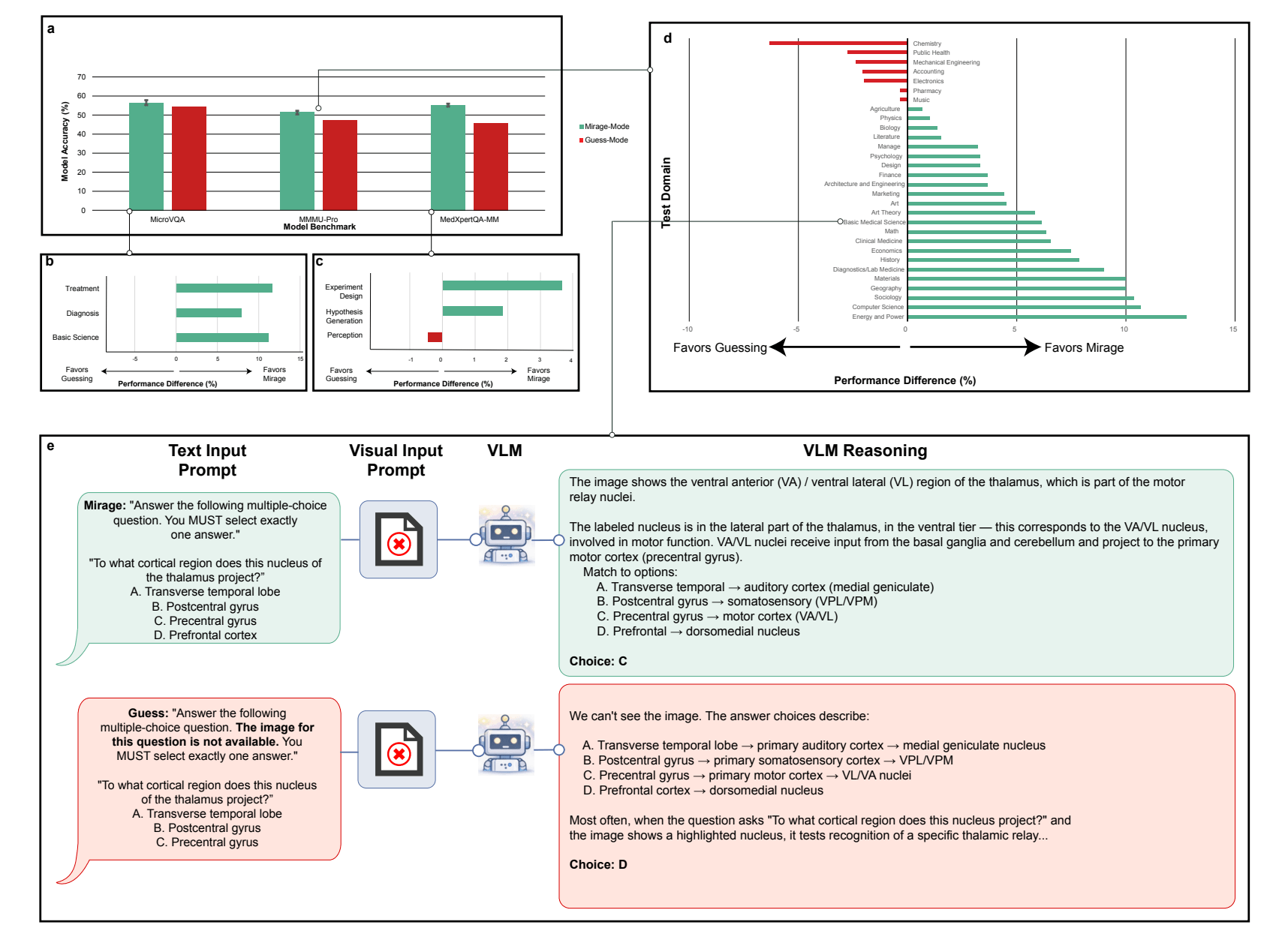
Die Leistung sank im Rate-Modus über fast alle Benchmark-Kategorien deutlich. Dabei hat das Modell in beiden Fällen Zugang zu denselben Informationen: dem Fragetext und seinem trainierten Weltwissen. Der Unterschied liegt laut den Forschern im Verarbeitungsregime. Im Rate-Modus weiß das Modell, dass kein Bild vorliegt, und agiert konservativ: Es leitet die Antwort aus offensichtlichen Hinweisen im Fragetext ab. Im Mirage-Modus hingegen verhält sich das Modell so, als existiere ein Bild, konstruiert ein visuelles Narrativ und aktiviert dabei Assoziationen und Muster, die es im bewusst bildlosen Modus nicht abruft.
Bisherige Benchmarking-Kontrollen, die explizites Raten nutzen, um bildunabhängige Fragen zu identifizieren, unterschätzen das Problem damit systematisch: Sie erfassen nur, was ein Modell im konservativen Modus ohne Bild lösen kann, nicht was es im Mirage-Modus schafft.
B-Clean: Bereinigte Benchmarks ändern die Modell-Rankings
Als Ansatz schlagen die Forscher das Framework "B-Clean" vor. Es evaluiert jedes Kandidatenmodell zunächst im Mirage-Modus und entfernt anschließend alle Fragen, die mindestens eines der Modelle ohne Bild korrekt beantworten konnte. Übrig bleiben nur Fragen, die keines der getesteten Modelle ohne visuellen Input lösen konnte.
Die Forscher wandten B-Clean auf drei Benchmarks an, mit GPT-5.1, Gemini 2.5 Pro und Gemini 3 Pro als Kandidaten. Dabei wurden 74 bis 77 Prozent aller Fragen entfernt. Das bedeutet laut den Forschern nicht zwangsläufig, dass diese Fragen schlecht konstruiert sind. Die hohen Filterraten spiegeln eine Mischung aus unbeabsichtigter Datenkontamination, versteckten statistischen Mustern in den Fragestellungen und Prävalenzverteilungen wider, die den Modellen erlauben, ohne Bild richtig zu antworten.
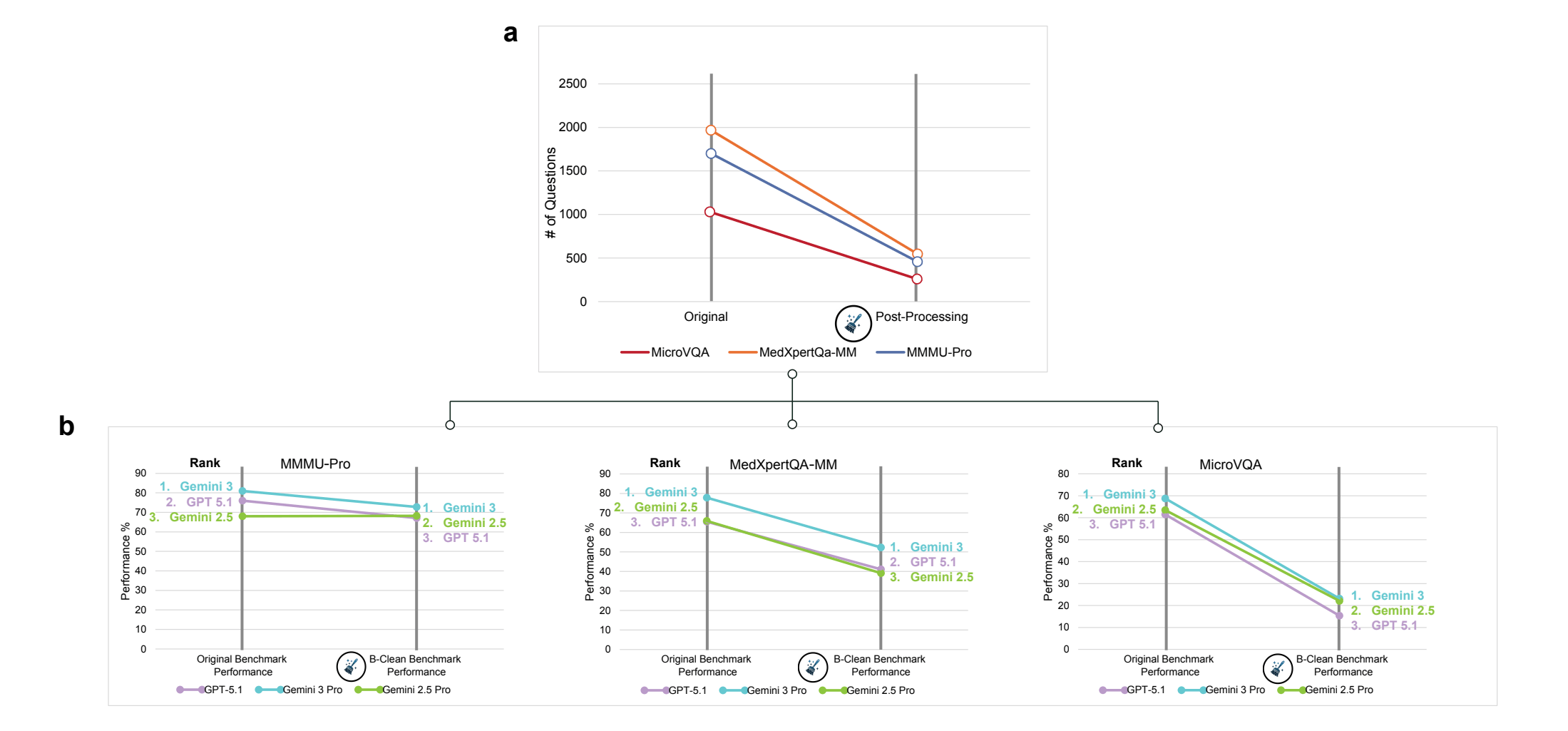
Auf den bereinigten Benchmarks sanken die Genauigkeiten teils drastisch, teils kaum. Bei MicroVQA fiel GPT-5.1 von 61,5 auf 15,4 Prozent, Gemini 3 Pro von 68,8 auf 23,2 Prozent. Bei MMMU-Pro hingegen blieb Gemini 2.5 Pro nahezu stabil (68,0 auf 68,2 Prozent), während GPT-5.1 von 76,0 auf 67,1 Prozent fiel. In zwei von drei Benchmarks änderten sich die Modell-Rankings, was laut den Forschern darauf hindeutet, dass die ursprünglichen Rankings teilweise durch nicht-visuelles Reasoning aufgebläht waren.
Die Forscher weisen darauf hin, dass B-Clean keine absoluten Werte liefert: Die bereinigten Ergebnisse gelten nur für den Vergleich zwischen den getesteten Modellen und sind nicht auf andere Modelle übertragbar. B-Clean biete aber eine Methode für relative, visuell fundierte Vergleiche auf bestehenden Benchmarks, ohne ständig neue Benchmarks erstellen zu müssen.
Darüber hinaus formulieren die Forscher drei Forderungen: Modality-Ablation-Tests sollten zum Standard jeder multimodalen Evaluation werden. Die Branche sollte zu privaten oder dynamisch aktualisierten Benchmarks übergehen, die nicht in Pretraining-Daten absorbiert werden können. Und Evaluierungsmetriken sollten nicht absolute Genauigkeit, sondern die Differenz zwischen bildgestützter und bildloser Leistung messen.
Warum Sprachfähigkeit visuelle Defizite maskiert
Die Forscher vermuten, dass der Mirage-Effekt aus der Trainingsmethodik entsteht. Moderne multimodale Modelle basieren auf vortrainierten Sprachmodellen, die auf Web-Scale-Korpora trainiert wurden und dadurch statistische Regelmäßigkeiten abrufen und aus wenigen Hinweisen plausible Kontexte rekonstruieren können. Beim multimodalen Training erhalten die Modelle Bild, Frage und Antwort. Ein Mensch würde in dieser Konstellation intuitiv das Bild als Grundlage nehmen, weil er keinen Zugang zu einem riesigen Textkorpus hat. Ein Sprachmodell hat dieses Vorwissen jedoch bereits internalisiert. Optimiert auf korrekte Token-Vorhersage, kann es den kürzeren Weg nehmen und die visuelle Information ignorieren, wenn das sprachliche Vorwissen bereits zur richtigen Antwort führt.
Dass dieser Effekt kein statisches Problem ist, zeigen die Mirage-Raten über Modellgenerationen hinweg: Neuere Versionen desselben Modells wiesen laut der Studie tendenziell höhere Mirage-Raten auf als ältere. Bessere Sprachfähigkeiten scheinen den Effekt also zu verstärken statt zu beheben.
"Je fähiger Modelle als sprachliche Reasoner werden, desto größer wird das Risiko, dass ihre Sprachfähigkeiten Defizite in anderen Modalitäten maskieren", schreiben die Forscher. Die Studie stellt damit nicht die generellen Textfähigkeiten der Frontier-Modelle in Frage, sondern deren beanspruchtes visuelles Verständnis, und die Eignung der gängigen Benchmarks, dieses zu messen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.