MIT-Studie zeigt "kognitive Schulden" durch ChatGPT - was das für die Praxis bedeutet

Eine Untersuchung des MIT legt nahe, dass der Einsatz von KI-Assistenten wie ChatGPT beim Verfassen von Texten zu "kognitiven Schulden" führen kann – einem Zustand, bei dem ausgelagerte Denkarbeit die eigene Lernfähigkeit und kritische Auseinandersetzung beeinträchtigt. Was bedeutet das für die Praxis?
Die weite Verbreitung von Großen Sprachmodellen (LLMs) wie ChatGPT im Alltag und Berufsleben hat Forscher des MIT Media Lab dazu veranlasst, die kognitiven Kosten ihrer Nutzung, insbesondere im Bildungskontext, zu untersuchen. Laut der 200 Seiten starken Studie "Your Brain on ChatGPT" konzentrierten sich die Wissenschaftler darauf, wie sich der Einsatz eines LLM beim Verfassen eines Essays auf die Gehirnaktivität, die Textqualität und das Lernverhalten auswirkt, verglichen mit der Nutzung traditioneller Suchmaschinen oder dem Schreiben ohne Hilfsmittel. Ein zentrales Konzept, das die Forscher aus ihren Ergebnissen ableiten, ist das der "kognitiven Schulden".
Die Forscher teilten 54 Teilnehmer, überwiegend Studierende von fünf Bostoner Universitäten, in drei Gruppen ein. Eine Gruppe nutzte ausschließlich OpenAIs GPT-4o (LLM-Gruppe), eine zweite Gruppe durfte herkömmliche Suchmaschinen wie Google verwenden, jedoch ohne KI-gestützte Antworten (Suchmaschinen-Gruppe), und die dritte Gruppe musste Essays ohne jegliche Hilfsmittel verfassen (Nur-Gehirn-Gruppe).
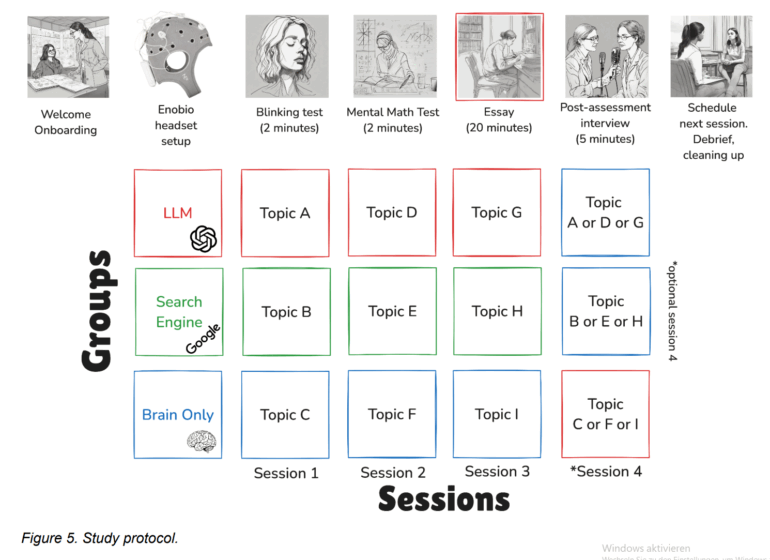
Über einen Zeitraum von vier Monaten absolvierten die Teilnehmer drei solcher Essay-Sitzungen, bei denen sie jeweils eines von drei zur Auswahl stehenden SAT-Prüfungsthemen innerhalb von 20 Minuten bearbeiteten. In einer optionalen vierten Sitzung, an der 18 Personen teilnahmen, wurden die Bedingungen für die LLM- und Nur-Gehirn-Gruppen getauscht: Die LLM-Gruppe schrieb nun ohne Hilfsmittel (LLM-zu-Gehirn) und die Nur-Gehirn-Gruppe nutzte erstmals den LLM (Gehirn-zu-LLM), wobei sie zu einem ihnen bereits bekannten Thema schrieben. Zur Datenerhebung setzten die Forscher Elektroenzephalographie (EEG), NLP-Analysen der Essays, Interviews sowie Bewertungen durch menschliche Lehrkräfte und einen KI-Richter ein.
Verringerte Gehirnkonnektivität als Zeichen kognitiver Auslagerung
Die EEG-Analysen zeigten laut der Studie robuste Beweise für signifikant unterschiedliche neuronale Konnektivitätsmuster. Die Gehirnkonnektivität skalierte systematisch mit dem Grad der externen Unterstützung: Die Nur-Gehirn-Gruppe wies die stärksten und weitreichendsten neuronalen Netzwerke auf, was laut der Untersuchung auf intensive interne semantische Verarbeitung, fokussierte Aufmerksamkeit und hohe Beanspruchung des Arbeitsgedächtnisses und der exekutiven Kontrolle hindeute. Kurz gesagt: Wer ohne Hilfsmittel schrieb, musste sich geistig besonders anstrengen und viele Gehirnbereiche gleichzeitig nutzen.
Die Suchmaschinen-Gruppe zeigte dagegen ein mittleres Engagement, ihre neuronale Aktivität spiegelte die Verarbeitung externer visueller Informationen und deren Integration wider, mit geringerer Aktivierung von Netzwerken für rein interne Verarbeitung im Vergleich zur Nur-Gehirn-Gruppe, aber stärkerer Top-Down-Kontrolle als die LLM-Gruppe.
Die LLM-Gruppe wies die insgesamt schwächste Kopplung auf, was laut der Untersuchung auf eine stärker automatisierte, prozedurale Integration bei insgesamt geringerer neuronaler Anstrengung hindeutet. Mit KI-Unterstützung arbeitete das Gehirn also weniger vernetzt und offenbar weniger tief – vieles wurde von der Technik übernommen. Über die ersten drei Sitzungen nahm die Konnektivität bei der LLM-Gruppe sogar ab, was die Forscher als mögliche "neuronale Effizienzanpassung" interpretieren.
Besonders aufschlussreich für das Konzept der "kognitiven Schulden" waren die Ergebnisse der vierten Sitzung. Teilnehmer, die zuvor mit einem LLM gearbeitet hatten und nun ohne Hilfsmittel schrieben (LLM-zu-Gehirn), zeigten eine schwächere neuronale Konnektivität und geringeres Engagement der Alpha- und Beta-Netzwerke im Vergleich zur Entwicklung der Nur-Gehirn-Gruppe. Ihr Aktivitätsniveau lag zwar über dem der Nur-Gehirn-Gruppe in deren erster Sitzung, erreichte aber nicht die Robustheit der geübten Nur-Gehirn-Gruppe. Dies, so die Autoren, könnte ein Anzeichen für die angesammelten "kognitive Schulden" sein, bei der die vorherige Auslagerung die volle Entfaltung interner kognitiver Netzwerke behindert hat.
Im Gegensatz dazu zeigte die Gehirn-zu-LLM-Gruppe – also Teilnehmer, die erstmals mit KI-Unterstützung arbeiteten – einen deutlichen, netzwerkweiten Anstieg der Konnektivität in allen Frequenzbändern. Wer erstmals die KI nutzte, musste also trotz der vorherigen praktischen Erfahrung im Essay-Schreiben ohne Tools viele Gehirnregionen gleichzeitig aktivieren. Die Forscher deuten dies als die kognitive Anstrengung, die externen KI-Vorschläge mit dem eigenen, intern entwickelten Verständnis und den Plänen für den Essay in Einklang zu bringen.
Homogene Texte und mangelnde Internalisierung als Symptome der "kognitiven Schulden"
Die NLP-Analyse ergab, dass die LLM-Gruppe statistisch homogenere Essays mit geringerer Abweichung und einer Tendenz zu spezifischen Formulierungen (z.B. Drittpersonen-Ansprache) verfasste, so die Studie. Sie nutzten auch die meisten spezifischen benannten Entitäten (NERs). Die Suchmaschinen-Gruppe war bei ihren Formulierungen teilweise durch Suchmaschinenoptimierung beeinflusst (z.B. häufige Nennung von "homeless person" beim Thema Philanthropie) und nutzte weniger NERs als die LLM-Gruppe, aber mehr als die Nur-Gehirn-Gruppe.
Besonders auffällig: In den Interviews nach den Sitzungen zeigten sich deutliche Unterschiede im Erinnerungsvermögen und im Gefühl der Eigenverantwortung. In der ersten Sitzung hatten etwas über 80 Prozent der LLM-Nutzer Schwierigkeiten, ein Zitat aus ihrem eben geschriebenen Essay korrekt wiederzugeben - niemand aus dieser Gruppe schaffte es fehlerfrei. Die Suchmaschinen- und Nur-Gehirn-Gruppen schnitten hier signifikant besser ab. Dieses Muster setzte sich auch in Sitzung 4 fort: Die LLM-zu-Gehirn-Gruppe zeigte erneut massive Defizite bei der Zitatfähigkeit, während die anderen Gruppen deutlich besser abschnitten - das kann als ein Kernsymptom der "kognitiven Schulden" interpretiert werden. Die Studie schlussfolgert, dass eine frühe Abhängigkeit von KI zu einer oberflächlichen Enkodierung führen kann, da die schlechte Erinnerungs- und Zitatleistung der LLM-Gruppe darauf hindeute, dass ihre früheren Essays aufgrund der ausgelagerten kognitiven Verarbeitung nicht tief internalisiert wurden.
Im Gegensatz dazu lege die stärkere Erinnerungsleistung der Nur-Gehirn-Gruppe, unterstützt durch robustere EEG-Konnektivität, nahe, dass ein anfänglicher Verzicht auf LLM-Werkzeuge die Gedächtnisbildung unterstützen könnte. Der rein eigenständige Aufwand habe demnach dauerhafte Gedächtnisspuren gefördert, die eine effektivere Reaktivierung ermöglichten, selbst als später LLM-Werkzeuge eingeführt wurden.
Die menschlichen Lehrkräfte empfanden zudem viele Texte der LLM-Gruppe als "seelenlos", mit Standardideen und wiederkehrenden Formulierungen. Die Studie weist auch darauf hin, dass das metakognitive Engagement bei der Gehirn-zu-LLM-Gruppe höher gewesen sein könnte. Diese Teilnehmer, die zuvor ohne Hilfsmittel gearbeitet hatten, verglichen möglicherweise mental ihre früheren eigenen Anstrengungen mit den KI-generierten Vorschlägen – ein Prozess der Selbstreflexion und elaborativen Verarbeitung, der mit exekutiver Kontrolle und semantischer Integration zusammenhänge, wie auch ihr EEG-Profil zeige.
LLM-Gruppe zeigt engeren Themen-Fokus
Die Forscher äußern sich insbesondere besorgt über eine weitere Beobachtung, die sie jedoch als vorläufig betrachten und die einer Bestätigung durch eine größere Teilnehmerstichprobe bedürfe: Teilnehmer der LLM-zu-Gehirn-Gruppe fokussierten sich wiederholt auf ein engeres Spektrum von Ideen, wie N-Gramm-Analysen und Interviewantworten nahelegten. Diese Wiederholung deute darauf hin, dass viele Teilnehmer sich möglicherweise nicht tiefgehend mit den Themen auseinandergesetzt oder das vom LLM bereitgestellte Material kritisch geprüft haben.
Wenn Individuen sich nicht kritisch mit einem Thema auseinandersetzen, so die Studie, könne ihr Schreiben voreingenommen und oberflächlich werden. Dieses Muster spiegele die Ansammlung "kognitiver Schulden" wider – ein Zustand, bei dem die wiederholte Abhängigkeit von externen Systemen wie LLMs die anstrengenden kognitiven Prozesse ersetzt, die für unabhängiges Denken erforderlich sind. Laut den Autoren verschieben kognitive Schulden die mentale Anstrengung kurzfristig, führe aber langfristig zu Kosten wie verminderter kritischer Nachfrage, erhöhter Anfälligkeit für Manipulation und geringerer Kreativität. Wenn Teilnehmer Vorschläge reproduzieren, ohne deren Genauigkeit oder Relevanz zu bewerten, geben sie nicht nur die Eigenverantwortung für die Ideen auf, sondern riskieren auch, oberflächliche oder voreingenommene Perspektiven zu internalisieren.
Team nennt Einschränkungen
Obwohl die Studie tiefgreifende Einblicke und das wichtige Konzept der "kognitiven Schulden" liefert, nennen die Autoren selbst mehrere Limitationen, die bei der Interpretation der Ergebnisse berücksichtigt werden müssen. Erstens sei die Teilnehmerzahl mit ursprünglich 54 Personen (und nur 18 in der optionalen vierten Sitzung) begrenzt. Für zukünftige Arbeiten sei es wichtig, eine größere Anzahl von Teilnehmern einzubeziehen, um die statistische Aussagekraft zu erhöhen und robustere Generalisierungen zu ermöglichen.
Des Weiteren wurde in dieser Studie ausschließlich ChatGPT als LLM verwendet. Die Autoren merken an, dass sie die Ergebnisse nicht direkt auf andere LLM-Modelle generalisieren können, da diese unterschiedliche Architekturen und Trainingsdaten haben könnten. Zukünftige Studien sollten daher idealerweise mehrere LLMs einbeziehen oder den Nutzern die Wahl ihres bevorzugten Modells lassen. Auch die Beschränkung auf Text als Modalität wird genannt; die Einbeziehung von LLMs mit Audio- oder anderen Modalitäten könnte neue Forschungsfragen aufwerfen.
Ein weiterer Punkt ist, dass die Essay-Schreibaufgabe nicht in Subtasks wie Ideenfindung, Schreiben und Überarbeiten unterteilt wurde, was oft in vorherigen Arbeiten geschehen sei und detailliertere Analysen der einzelnen Phasen ermöglichen könnte. Schließlich weisen die Forscher darauf hin, dass sich ihre EEG-Analyse auf Konnektivitätsmuster konzentrierte, ohne spektrale Leistungsänderungen zu untersuchen, und dass die räumliche Auflösung des EEG die präzise Lokalisierung tiefer kortikaler Beiträge einschränke, weshalb der Einsatz von fMRT ein nächster Schritt für zukünftige Arbeiten sei. Die Ergebnisse seien zudem kontextabhängig und auf das Schreiben eines Essays im Bildungsumfeld fokussiert.
Das Paper wurde noch nicht Peer-Reviewed.
Was bedeutet die Studie für die Praxis?
Die zentrale Erkenntnis potenzieller "kognitiven Schulden" und veränderter neuronaler Verarbeitungsmuster bei intensiver LLM-Nutzung zeigt, dass ein unreflektierter Einsatz dieser Werkzeuge ungewollte Konsequenzen haben könnte.
Für Lehrende und Bildungsinstitutionen bedeutet das vor allem, dass die angeleitete Integration von LLMs in den Unterricht enorm wichtig ist - sofern davon auszugehen ist, dass Schüler:innen und Studierende diese Werkzeuge sowieso nutzen werden. Eine zu frühe oder zu umfassende Abhängigkeit von KI-Werkzeugen könnte andernfalls die Entwicklung grundlegender Fähigkeiten wie eigenständiges kritisches Denken und semantische Enkodierung von Informationen beeinträchtigen.
Die Studienergebnisse legen außerdem nahe, dass Phasen des eigenständigen Arbeitens entscheidend für die Ausbildung robuster kognitiver Fähigkeiten sein könnten. Der Vergleich mit der Suchmaschinen-Gruppe, die trotz Werkzeugnutzung eine aktivere kognitive Auseinandersetzung zeigte, betont, dass nicht jede Technologie die gleichen Auswirkungen hat. Der aktive Prozess des Recherchierens und Integrierens scheint kognitiv fordernder und lernförderlicher zu sein als die Interaktion mit einem LLM, das direkt Textblöcke liefert.
Für die Praxis könnte dies bedeuten, LLMs eher als unterstützende Werkzeuge in späteren Phasen eines Lernprozesses einzusetzen, nachdem eine solide Grundlage durch eigenständige Arbeit geschaffen wurde – ein Ansatz, den die positive neuronale Reaktion der Gehirn-zu-LLM-Gruppe bei erstmaliger KI-Nutzung unterstützt. Allerdings ist unklar, welche Entwicklung die Gruppe nehmen würde, wenn sie ab da nur noch mit LLMs arbeiten würde.
Bei der Übertragung der Studienergebnisse in die Praxis müssen jedoch auch die spezifischen Bedingungen des Experiments berücksichtigt werden. Das strikte Zeitlimit von 20 Minuten ist ein wesentlicher Kontextfaktor: Die Notwendigkeit, ein externes Werkzeug zu bedienen, kostet innerhalb dieses knappen Zeitfensters zwangsläufig Zeit, die der Nur-Gehirn-Gruppe vollständig für Denk- und Schreibprozesse zur Verfügung stand und beeinflusst direkt auf welche Weise das Werkzeug genutzt wird. In realen Szenarien mit großzügigeren Zeitfenstern könnten sich die Ergebnisse und die Ausprägung der "kognitiven Schulden" anders darstellen - sofern Nutzer auch interne oder externe Anreize haben nicht bloß einen fertigen Text zu generieren.
Interessant für die Praxis sind auch die unterschiedlichen Motivationen der Gruppen bei der Themenwahl, wie die Studie für Sitzung 2 berichtet. Die LLM-Gruppe wählte Themen hauptsächlich nach wahrgenommenem Engagement und persönlicher Resonanz ("am spaßigsten zu schreiben", "schon oft darüber nachgedacht"). Die Suchmaschinen-Gruppe wog Engagement mit Bekanntheit und persönlichem Bezug ab ("kann mich am meisten damit identifizieren", "schon mit vielen Leuten darüber gesprochen"). Im Gegensatz dazu betonte die Nur-Gehirn-Gruppe vorrangig Vorerfahrungen ("ähnlich einem früheren Essay", "an einem Projekt mit ähnlichem Thema gearbeitet"). Dass Vorerfahrung für die Nur-Gehirn-Gruppe zum wichtigsten Kriterium wurde, lag laut den Autoren wahrscheinlich an dem Bewusstsein, dass keine externen Referenzmaterialien verfügbar waren.
Diese unterschiedlichen Herangehensweisen an die Aufgabenstellung könnten praktische Implikationen dafür haben, wie Lernende Aufgaben angehen, wenn ihnen bestimmte Werkzeuge zur Verfügung stehen oder eben nicht.
In diesem Kontext ist auch die Entscheidung, in Sitzung 4 ausschließlich ein den Teilnehmern bereits bekanntes Thema zu verwenden, für die Praxis relevant. Während dies den direkten Vergleich von sprachlichen Übertragungen ermöglichte, bleibt unklar, wie sich ein Werkzeugwechsel bei einem komplett neuen Thema ausgewirkt hätte - also ob etwa die Nur-Gehirn-Gruppe ChatGPT ebenfalls stärker für die Textgenerierung statt für die Verfeinerung eigener Gedanken aus dem vorherigen Essay genutzt hätte und welche Muster sich bei der LLM-Gruppe gezeigt hätten.
Auch ist nicht ganz klar, wie sich unterschiedliche Nutzungsverhalten konkret auswirken können. Zwar zeigt die Studie detailliert die Art und Häufigkeit der ChatGPT-Nutzung – etwa ob Teilnehmende den LLM eher zur reinen Textgenerierung, zur Strukturierung, zur Informationssuche oder für Korrekturen einsetzten –, verzichtet jedoch auf eine weitergehende Analyse, wie sich diese unterschiedlichen Nutzungsweisen konkret auf die neuronalen Muster, das Erinnerungsvermögen, die Zitatfähigkeit oder das Ownership-Gefühl auswirkten.
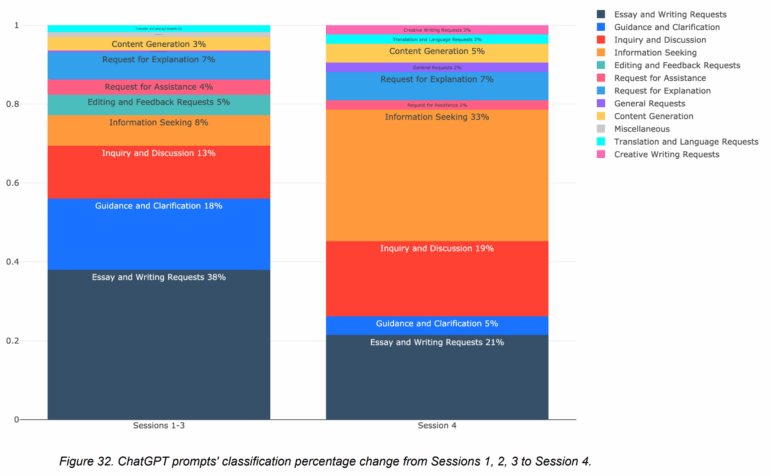
In der Praxis bleibt somit unklar, ob beispielsweise eine reflektierte, assistierende LLM-Nutzung andere Effekte gehabt hätte als eine überwiegend passive Übernahme von KI-generiertem Text. Zukünftige pädagogische Ansätze sollten daher nicht nur die generelle Tool-Nutzung, sondern auch die individuelle Interaktionsweise mit LLMs differenziert betrachten, um gezielt förderliche oder nachteilige Lerneffekte zu erkennen - Anbieter wie Anthropic bieten etwa ihren Chatbot Claude mit einem speziellen Lernmodus an.
Die wesentliche Erkenntnis scheint am Ende vor allem zu sein, dass es weiter sinnvoll ist, sein Gehirn zu benutzen. Wie viel, muss noch geklärt werden.
Hinweis der Redaktion: In einer früheren Version des Artikels wurde von "kognitiver Schuld" gesprochen. Da diese Übersetzung missverständlich ist, wurde sie durch "kognitive Schulden" ersetzt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.