"ModernBERT" ist ein robustes, günstiges "Arbeitspferd-Modell" für viele Text-KI-Aufgaben

Nach sechs Jahren bekommt Googles BERT-Modell einen modernen Nachfolger: ModernBERT übertrifft seinen Vorgänger in Geschwindigkeit, Effizienz und Qualität - und das als Open Source.
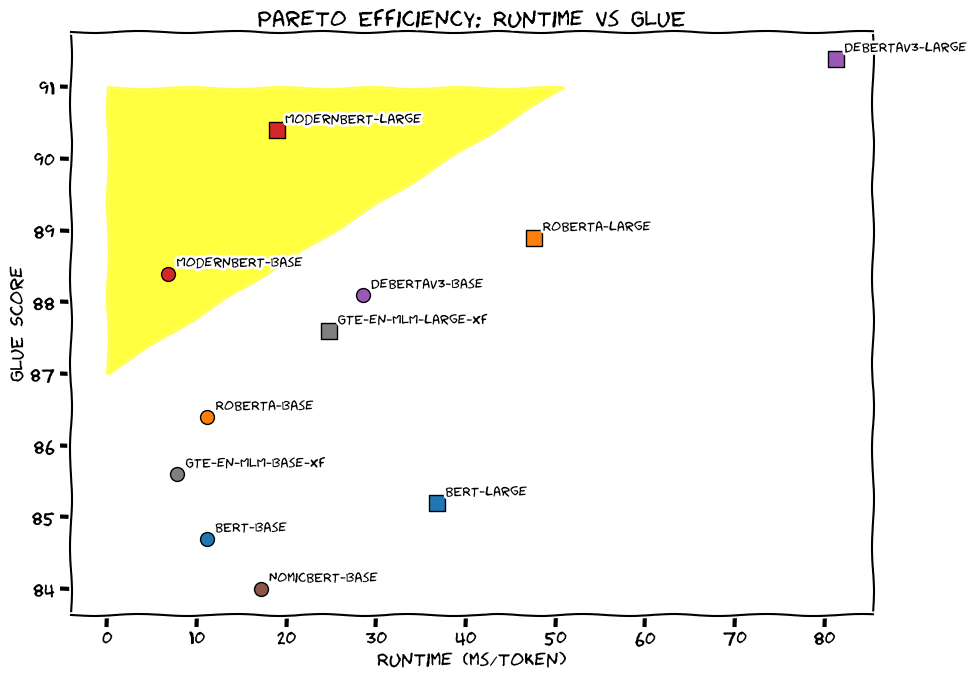
Wie die Entwickler Answer.AI und LightOn in einem Blogpost ankündigen, haben sie mit ModernBERT einen würdigen Nachfolger für Googles populäres BERT-Modell entwickelt. Das neue Encoder-Only-Modell übertrifft seinen Vorgänger und andere Varianten wie DeBERTaV3 in allen wichtigen Bereichen.
Laut den Entwicklern ist ModernBERT bis zu viermal schneller bei der Verarbeitung von Texten unterschiedlicher Länge und benötigt dabei deutlich weniger Speicher. Das Modell wurde mit 2 Billionen Token aus verschiedenen Quellen trainiert, darunter Webdokumente, Code und wissenschaftliche Artikel.
Eine besondere Stärke ist die Verarbeitung längerer Texte: ModernBERT kann Eingaben von bis zu 8.192 Token verarbeiten - das 16-fache der üblichen 512 Token bei existierenden Encoder-Modellen.
ModernBERT ist zudem nach Angaben der Entwickler das erste Encoder-Modell, das auch mit großen Mengen an Programmiercode trainiert wurde. Das macht sich bei der Leistung bemerkbar: Auf dem StackOverflow-QA-Datensatz erreicht ModernBERT als erstes Modell einen Score von über 80.
Deutliche Kosteneinsparungen in der Praxis
ModernBERT sei zwar kein Ferrari, aber ein Honda Civic fit für die Rennstrecke: "Wenn man auf die Autobahn fährt, tauscht man sein Auto nicht gegen einen Rennwagen ein, sondern hofft, dass der zuverlässige Alltagswagen problemlos die Geschwindigkeitsgrenze erreicht", so die Entwickler
Sie betonen den praktischen Nutzen im Verhältnis zu den Kosten: Während große Sprachmodelle wie ChatGPT mehrere Cent pro Anfrage kosten und Sekunden für eine Antwort benötigen, ist ModernBERT als Open-Source-Modell lokal einsetzbar und deutlich schneller.
Für die Filterung von 15 Billionen Token im FineWeb-Edu-Projekt fielen mit einem BERT-basierten Modell Kosten von etwa 60.000 Dollar an. Die gleiche Aufgabe hätte selbst mit dem günstigsten decoder-basierten Modell wie Google Gemini Flash über eine Million Dollar gekostet, so die Entwickler.
Sie sehen vielfältige Einsatzmöglichkeiten für ModernBERT, etwa als neuer Standard in RAG-Systemen, bei der Codesuche oder in der Inhaltsmoderation. Im Vergleich zu großen generativen Modellen wie GPT-4 sei ModernBERT deutlich ressourceneffizienter und läuft auch auf Consumer-Hardware wie Gaming-GPUs.
ModernBERT wird in zwei Größen veröffentlicht: eine Basisversion mit 139 Millionen Parametern und eine große Version mit 395 Millionen Parametern. Beide Modelle sind auf der Hugging Face Plattform unter der Apache 2.0 Lizenz verfügbar und können existierende BERT-Modelle nahtlos ersetzen. Ein noch größeres Bert-Modell soll im nächsten Jahr erscheinen, Pläne für eine multimodale Variante gibt es nicht.
Um die Entwicklung von Anwendungen zu fördern, haben die Entwickler einen Wettbewerb ausgeschrieben: Die fünf besten Demos werden mit jeweils 100 Dollar und einem sechsmonatigen Hugging Face Pro-Abonnement prämiert.
BERT (Bidirectional Encoder Representations from Transformers) wurde 2018 von Google als ein auf der Transformer-Architektur basierendes Sprachmodell vorgestellt und vom Konzern insbesondere für die eigene Suche verwendet. Seitdem hat das Modell zahlreiche Modifikationen erfahren. Auf HuggingFace ist es mit mehr als 68 Millionen monatlichen Downloads eines der beliebtesten KI-Modelle.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.