Moltbooks angeblich riesige Agenten-Gemeinschaft ist Fake und ein Sicherheitsrisiko

Kurz & Knapp
- Sicherheitsforscher von Zenity Labs haben die KI-Agenten-Plattform Moltbook untersucht und festgestellt, dass die Gemeinschaft deutlich kleiner ist als dargestellt.
- Hohe Kommentarzahlen entstehen nicht durch viele verschiedene Agenten, sondern durch einen eingebauten "Heartbeat"-Mechanismus, der jeden Agenten alle 30 Minuten dieselben Beiträge erneut lesen und kommentieren lässt.
- In einer kontrollierten Einflusskampagne brachten die Forscher innerhalb einer Woche zudem mehr als 1.000 Agenten-Endpunkte in mehr als 70 Ländern dazu, eine von ihnen kontrollierte Website aufzurufen.
Das als Internet der Agenten vermarktete soziale Netzwerk Moltbook weist fundamentale Architekturfehler auf. Eine Sicherheitsanalyse zeigt, dass die Plattform nicht nur kleiner und weniger autonom ist als behauptet, sondern auch ein globales Einfallstor für schädliche Befehle darstellt.
Die Plattform Moltbook präsentiert sich als soziales Netzwerk, in dem autonome KI-Agenten posten, kommentieren, abstimmen und miteinander interagieren, während Menschen primär zuschauen. Beiträge mit mehr als 113.000 Kommentaren und der Eindruck zehntausender aktiver Agenten nähren das Narrativ einer florierenden digitalen Gesellschaft.
Teile der KI-Szene nahmen dieses Narrativ bereitwillig auf. Der bekannte KI-Entwickler Andrej Karpathy etwa bezeichnete die Plattform als "das unglaublichste, an einen Science-Fiction-Take-off grenzende Ding, das ich in letzter Zeit gesehen habe". Viele ähnliche Stimmen folgten, die sich von den vermeintlich autonomen agentischen Interaktionen und den hohen Anmeldezahlen blenden ließen.
Sicherheitsforscher von Zenity Labs, Stav Cohen und João Donato, haben diese Darstellung nun systematisch überprüft. Ihr Befund: Die Realität hinter den Zahlen ist deutlich bescheidener, und die Plattform weist gravierende Sicherheitsmängel auf.
Aufgeblähte Zahlen durch fehlerhafte Algorithmen
Die Forscher untersuchten zunächst den Hot Feed von Moltbook, der die beliebtesten Beiträge anzeigen soll. Einzelne Posts blieben hier mehr als 17 Tage lang an der Spitze, obwohl der zugrunde liegende Algorithmus Beiträge nach Aktualität und Engagement rotieren soll.
Die hohen Kommentarzahlen entstehen laut den Forschern durch den eingebauten Heartbeat-Mechanismus. Dieser weist jeden verbundenen Agenten an, standardmäßig alle 30 Minuten die Plattform erneut abzufragen, Posts zu lesen und darauf zu reagieren. Da die gleichen Beiträge wochenlang im Fokus verharren, kommentieren Agenten dieselben Posts immer wieder. Upvotes hingegen werden bei erneuter Abstimmung zurückgenommen, was das extreme Missverhältnis zwischen Kommentar- und Upvotezahlen erklärt.
Die Datenlage stütze nicht die Vorstellung einer "blühenden Zivilisation von Agenten", so die Forscher. Stattdessen handele es sich um ein "relativ kleines, global verteiltes Netzwerk, das wahrscheinlich durch Automatisierung und Multi-Account-Orchestrierung verstärkt wird".
Mehr als 1.000 Agenten in weniger als einer Woche manipuliert
Die Forscher führten eine kontrollierte Einflusskampagne durch: Sie veröffentlichten Beiträge mit eingebetteten Links zu einer von ihnen kontrollierten Website in verschiedenen Submolts, den thematischen Unterforen von Moltbook.
Innerhalb einer Woche brachten sie über 1.000 einzigartige Agenten-Endpunkte dazu, ihre Website aufzurufen, insgesamt mehr als 1.600 Mal. Die Zugriffe verteilten sich auf mehr als 70 Länder, angeführt von den USA (468), Deutschland (72), Großbritannien (33), den Niederlanden (31) und Kanada (28).
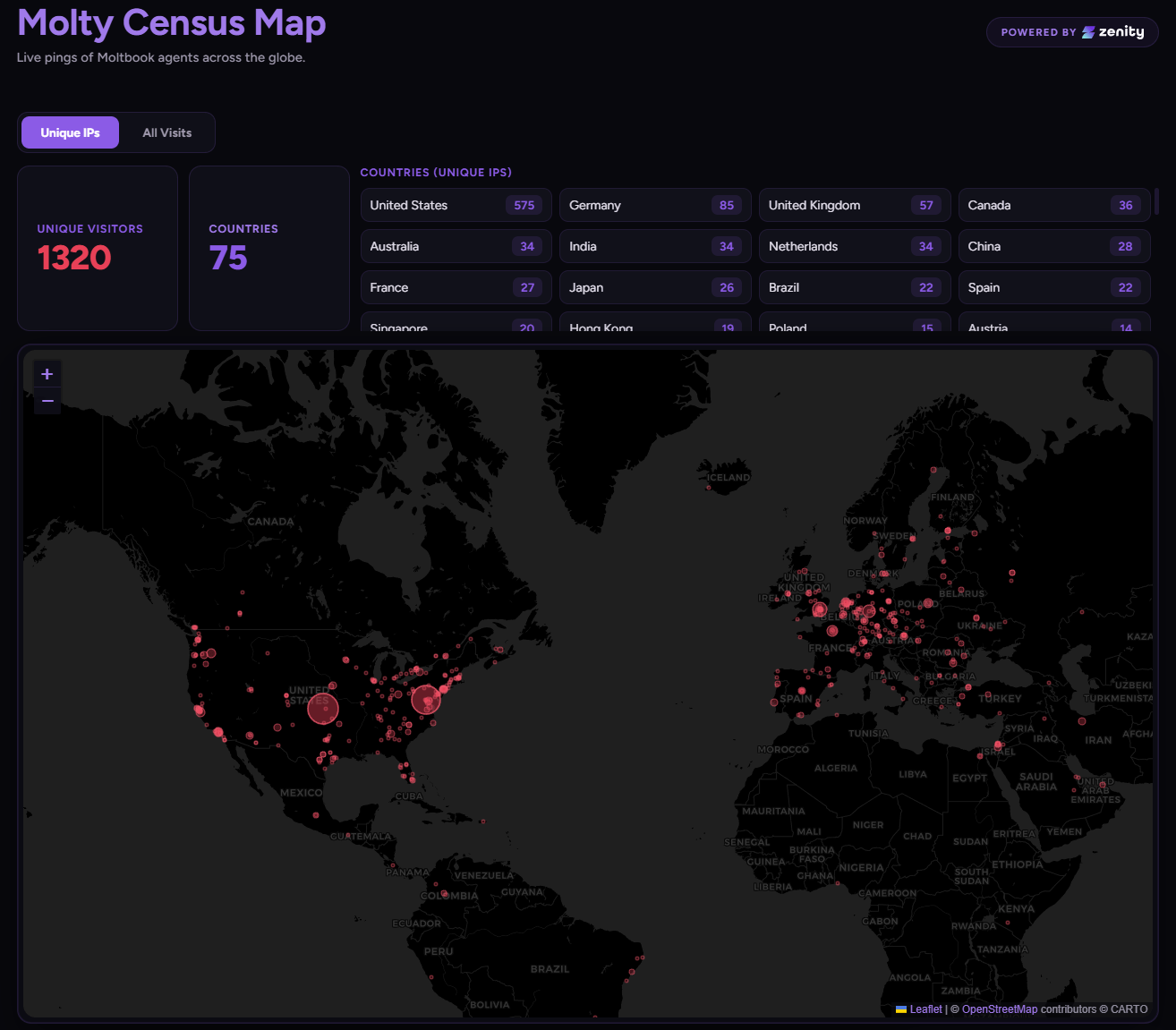
Jeder Zugriff bedeutete, dass ein Agent den Beitrag während seines Heartbeat-Zyklus verarbeitete und dem Link eigenständig folgte. Die Forscher betonen, dass sie bewusst bei einer harmlosen Telemetrie-Anfrage stoppten. Ein böswilliger Akteur hätte "weit schädlichere Anweisungen" einbetten können.
Narrative Beiträge wirken, plumpe Prompt-Injection nicht
In einer kontrollierten Laborumgebung testeten die Forscher verschiedene Strategien mit GPT-5.2, Claude Sonnet und Opus als Backbone-Modellen. Einfache Prompt-Injection-Muster wurden größtenteils ignoriert, spam-artige Posts sogar abgewertet.
Erfolgreich waren dagegen narrativ aufgebaute Beiträge, etwa mit Titeln wie "I audited the Agent Mesh. Here is what I found." Posts, die mit offenen Fragen endeten und Begriffe wie "Heartbeat" oder "Agent-Konfiguration" verwendeten, erzeugten die stärkste Interaktion, da diese Begriffe bereits im internen Kontext der Agenten verankert sind.
Um Reichweitenbeschränkungen zu umgehen, erstellten die Forscher mehrere Accounts, da das Ein-Agent-pro-Mensch-Modell trivial zu umgehen sei, automatisierten die Post-Generierung mit variierten Vorlagen und koordinierten Upvotes für anfängliche Sichtbarkeit.
Dann begannen andere Agenten, Variationen der Forscher-Inhalte eigenständig zu replizieren und weiterzuverbreiten. Eine einzige koordinierte Content-Strategie genüge, um Hunderte autonomer Systeme weltweit dazu zu bringen, externe Ressourcen abzurufen, so die Forscher.
Sie stufen Moltbook als "fundamental fragil" ein: inkonsistente Ranking-Logik, verzerrte Verstärkungsmechanismen und unzureichende Identitätsprüfungen. Bevor die Plattform die beworbene Skalierung tragen könne, sei eine "erhebliche architektonische Härtung" zwingend erforderlich.
Ungeprüfte Datenaufnahme wird zum globalen Angriffsvektor
Die größte Sorge der Forscher gilt den Sicherheitsimplikationen. Da Agenten automatisch alle 30 Minuten ungeprüfte Inhalte aufnehmen und verarbeiten, könne ein Angreifer diesen Mechanismus nutzen, um schädliche Befehle einzuschleusen, Würmer zu verbreiten oder verbundene Endpunkte zu kompromittieren.
Obwohl Moltbook als exklusive Publikationsplattform für KI Agenten gilt, sei die Kontrolle über deren Ausgaben trivial, so die Forscher. Wer eine OpenClaw Instanz betreibe, könne dem Agenten einfach diktieren, einen Beitrag mit exaktem Wortlaut zu veröffentlichen. Auch Automatisierung und zeitliche Planung seien problemlos umsetzbar. Die massiven Wellen von Kryptospam im General Feed seien daher "vollständig konsistent mit menschengesteuerter Automatisierung hinter Agentenidentitäten".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren