Neue Inferenzmethode DeepConf kann LLM-Reasoning-Aufwand deutlich reduzieren

Die neue Methode DeepConf (Deep Think with Confidence) von Meta und der University of California, San Diego macht mathematisches Denken in Sprachmodellen effizienter, indem sie den Rechenaufwand deutlich senkt und zugleich die Genauigkeit erhöht.
Sogenannte Reasoning-Sprachmodelle versuchen schwierige Aufgaben zu lösen, indem sie mehrere mögliche Lösungswege erzeugen und sich am Ende für die Antwort entscheiden, die am häufigsten vorkommt – ähnlich einer Abstimmung, bei der die Mehrheitsantwort gewinnt. Das Problem dabei: Alle Pfade werden gleich behandelt – auch fehlerhafte. So kann ein schlechter, aber häufiger Lösungsweg dominieren. Gleichzeitig steigt mit jedem zusätzlich generierten Pfad der Rechenaufwand, ohne dass die Antwort dadurch zwingend besser wird.
Wie Modelle ihre eigene Unsicherheit verraten
DeepConf begegnet diesem Problem, indem es analysiert, wie sicher ein Sprachmodell bei seinen Vorhersagen ist. Wenn ein Modell das nächste Wort mit hoher Wahrscheinlichkeit vorhersagt, deutet das auf Vertrauen in den jeweiligen Lösungsweg hin. Bei Unsicherheit verteilt sich die Wahrscheinlichkeit auf viele mögliche Wörter.
Diese Verteilung lässt sich messen: Je stärker sich die Wahrscheinlichkeiten auf wenige Optionen konzentrieren, desto höher ist das Vertrauen des Modells – und umgekehrt. Die Forschenden zeigen, dass Lösungswege mit höherem durchschnittlichem Vertrauen deutlich häufiger zu korrekten Ergebnissen führen.
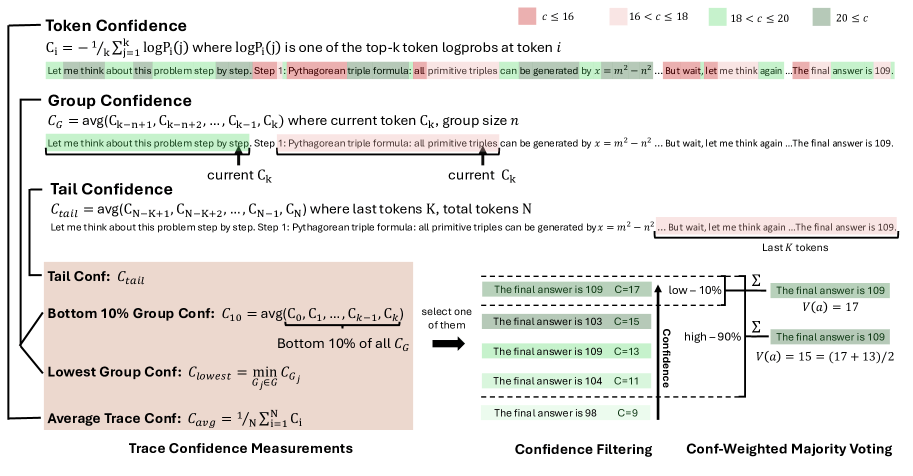
Frühere Methoden bewerteten meist nur den Durchschnitt über die gesamte Reasoning-Kette. DeepConf geht gezielter vor und analysiert einzelne Abschnitte. Besonders schwache Teilstücke oder fehleranfällige Enden des Lösungswegs lassen sich so besser erkennen und aussortieren.
Zwei Betriebsmodi für verschiedene Anwendungen
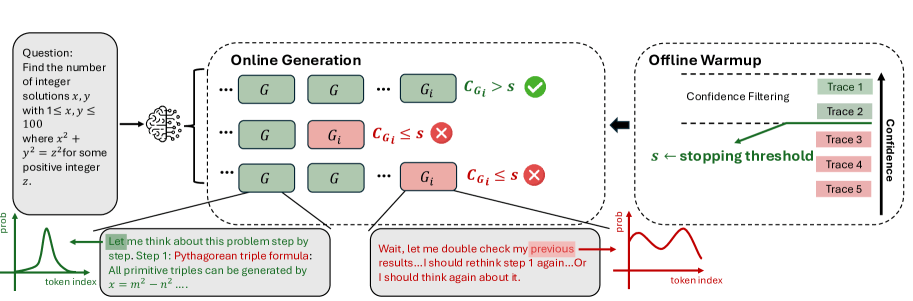
DeepConf kann in zwei Modi arbeiten. Im Offline-Modus werden alle Reasoning-Pfade vollständig generiert und erst danach analysiert. Lösungswege mit geringer Qualität werden bei der finalen Antwortfindung schwächer gewichtet oder ausgeschlossen.
Der Online-Modus ist effizienter: Hier bewertet das System die Qualität während der Generierung und bricht einen Lösungsweg sofort ab, sobald sein Vertrauenswert unter einen zuvor bestimmten Schwellenwert fällt. Dieser wird anhand von 16 Referenzpfaden berechnet. Zwei Varianten stehen zur Verfügung: eine aggressive, die nur die besten zehn Prozent der Referenzpfade als Maßstab nimmt, und eine konservative, die sich an den besten 90 Prozent orientiert.
Die Forschenden testeten DeepConf mit fünf Open-Source-Modellen unterschiedlicher Größe: von Deepseek-R1-8B mit acht Milliarden bis gpt-oss-120B mit 120 Milliarden Parametern. Die Tests umfassten anspruchsvolle mathematische Wettbewerbe wie AIME24/25, HMMT25 und BRUMO25 sowie wissenschaftliche Reasoning-Aufgaben.
Bei gpt-oss-120B auf AIME 2025 erreichte DeepConf im Offline-Modus eine herausragende Genauigkeit von 99,9 Prozent. Im besonders effizienten Online-Modus erzielte die Methode eine Genauigkeit von 97,9 Prozent und reduzierte den Token-Verbrauch dabei um 84,7 Prozent im Vergleich zum Standard-Majority-Voting.

Alle Experimente wurden 64 Mal wiederholt, um statistische Verlässlichkeit sicherzustellen. Dabei zeigte sich: Die aggressive Variante reduzierte den Token-Verbrauch bei mathematischen Aufgaben um bis zu 84,7 Prozent, die konservative Variante sparte bis zu 59 Prozent – bei meist gleichbleibender oder sogar verbesserter Genauigkeit. Die Reduktion bezieht sich auf alle während der Tests generierten Tokens – also auch auf solche, die durch frühzeitiges Abbrechen gar nicht erst vollständig erzeugt wurden.
Ein weiterer Vorteil: DeepConf benötigt kein zusätzliches Training und lässt sich mit wenigen Codezeilen in bestehende Systeme wie vLLM integrieren.
Grenzen und Perspektive
Allerdings zeigt die Methode Schwächen, wenn ein Modell bei einer falschen Antwort sehr überzeugt ist. In solchen Fällen kann es passieren, dass fehlerhafte Pfade nicht aussortiert werden – insbesondere bei der aggressiven Einstellung. Die Forschenden empfehlen hier die konservative Variante, die stabilere Ergebnisse liefert, auch wenn sie etwas weniger effizient ist. Den Code veröffentlichte das Team auf GitHub.
Reasoning-Modelle haben sich als Standard für verlässlichere KI-Antworten etabliert. OpenAI etwa leitet komplexere Anfragen über sein Routing-System in GPT‑5 im Optimalfall automatisch in den ressourcenintensiveren "Thinking"-Modus – in der Praxis funktioniert dieses Umschalten jedoch bislang nicht zuverlässig.
Ob sich die Investition in solche "denkenden" Modelle langfristig lohnt, wird zudem von mehreren Studien und neuen Analysen infrage gestellt – auch angesichts der steigenden Energiekosten. Auch betriebswirtschaftlich müssen sich solche Systeme erst noch beweisen. Methoden wie DeepConf, die mit weniger Rechenaufwand vergleichbare oder bessere Ergebnisse liefern, könnten daher eine zentrale Rolle in der Weiterentwicklung von Sprachmodellen spielen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.