Neue KI-Architektur verspricht besseres "System 2-Denken"

Eine neue Architektur namens Energy-Based Transformer soll KI-Modellen beibringen, Probleme analytisch und schrittweise zu lösen.
Heutige KI-Modelle arbeiten nach der Ansicht vieler Experten ähnlich dem menschlichen "System 1-Denken" nach Daniel Kahneman: Sie sind schnell, intuitiv und stark in der Mustererkennung. Laut einer Studie von Forschern der UVA, UIUC, Stanford, Harvard und Amazon GenAI versagen sie jedoch oft bei Aufgaben, die das langsame, analytische "System 2-Denken" erfordern, wie komplexes logisches Schließen oder Mathematik.
Das Paper "Energy-Based Transformers are Scalable Learners and Thinkers" stellt die Frage, ob solche Denkfähigkeiten allein aus unüberwachtem Lernen entstehen können. Die Antwort der Forscher ist eine neue Architektur: die Energy-Based Transformers (EBTs).
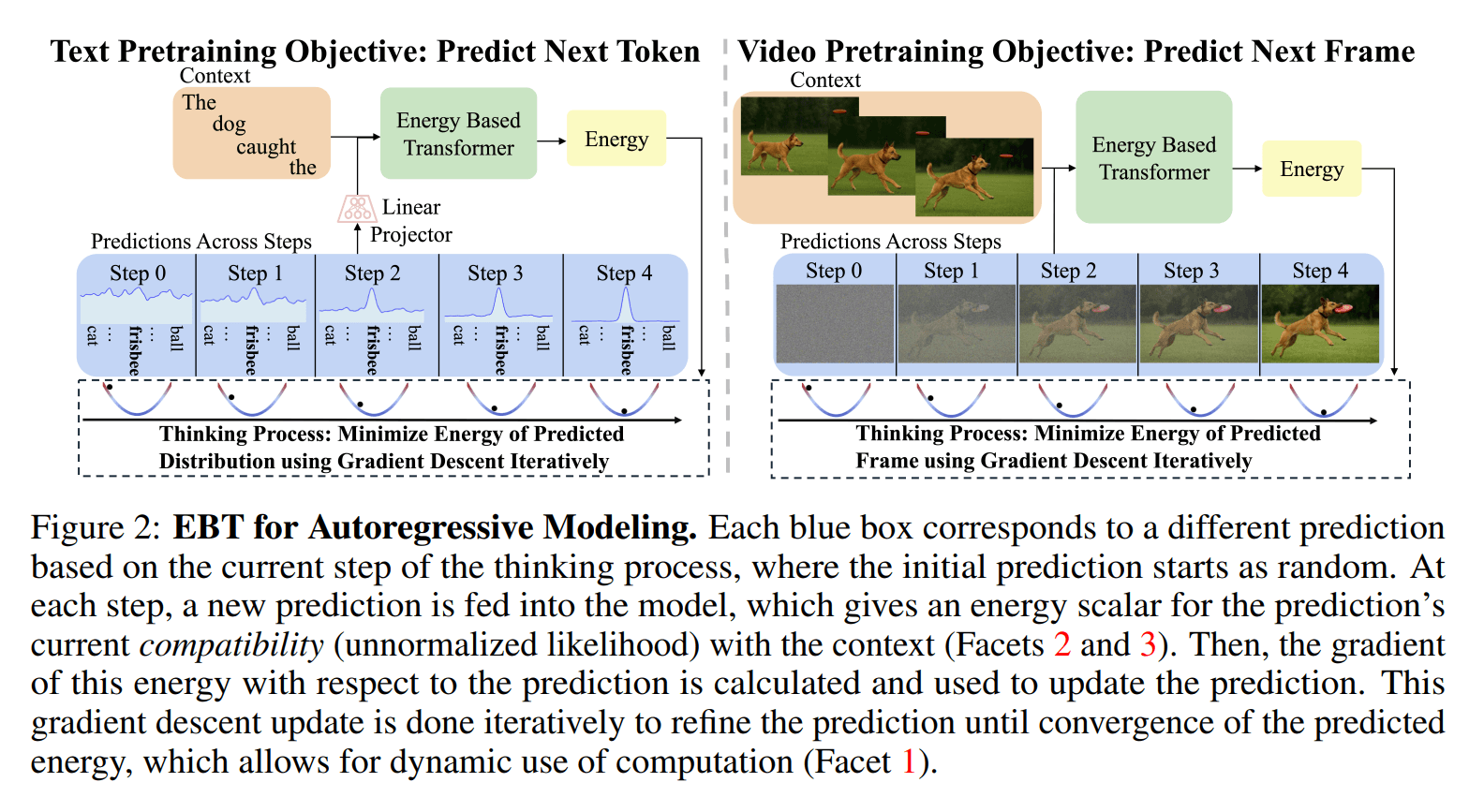
Der Ansatz der EBTs definiert das Denken als einen iterativen Optimierungsprozess. Statt eine Antwort in einem einzigen Schritt zu generieren, beginnt das Modell mit einer zufälligen Lösung. Anschließend bewertet es diese, indem es eine "Energie" berechnet.
Je niedriger die Energie, desto besser passt die Vorhersage zum Kontext. Durch wiederholte Anpassungen mittels Gradientenabstieg wird die Antwort schrittweise verfeinert, bis die Energie ein Minimum erreicht. Dieser Mechanismus soll es dem Modell ermöglichen, für schwierige Probleme mehr Rechenzeit zu investieren.
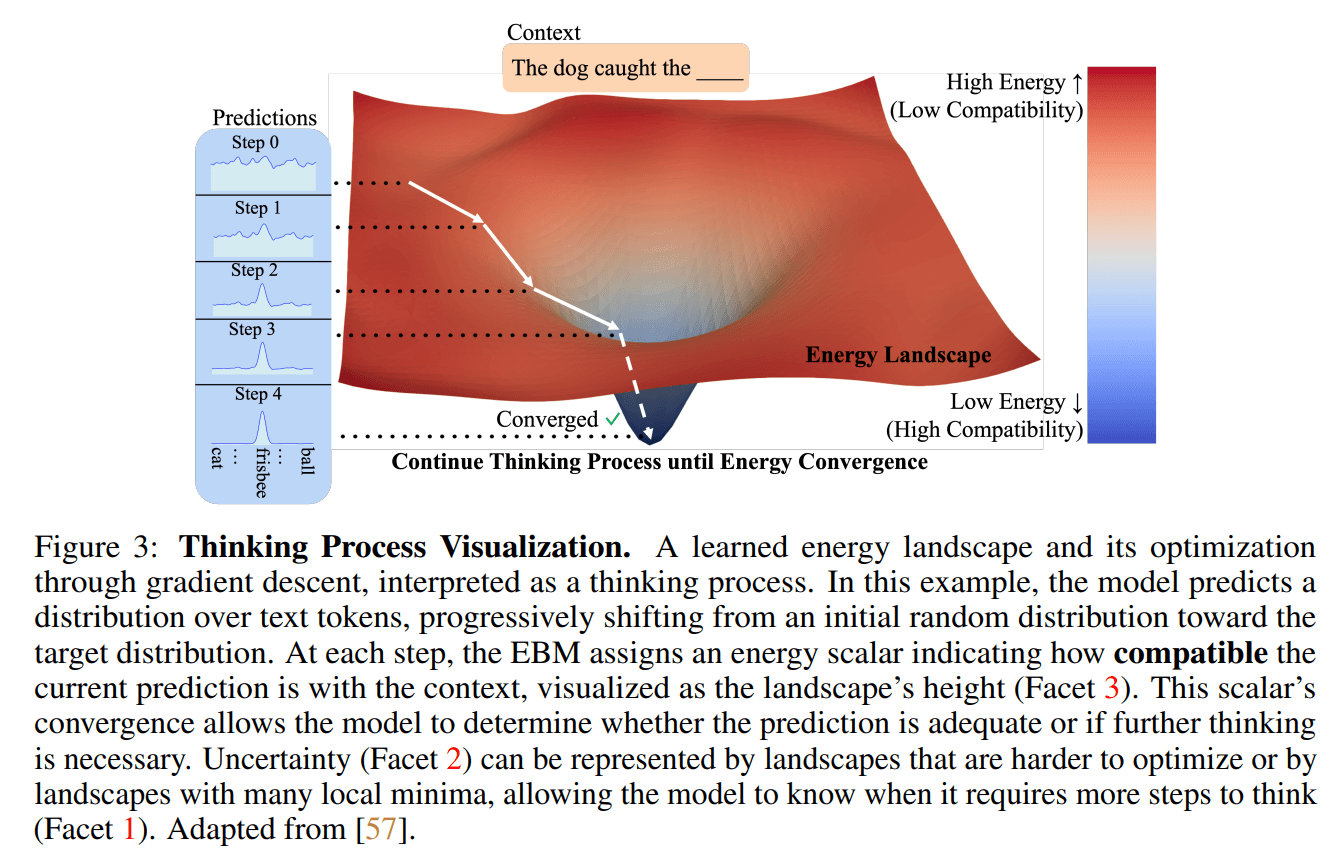
Die Idee, diesen Prozess in Begriffen der Energie zu beschreiben, ist nicht neu. Yann LeCun, der KI-Chefwissenschaftler von Meta, gehört zu den Forschern, die schon seit vielen Jahren über sogenannte „Energy-based Models” sprechen.
Effizienteres Lernen und bessere Generalisierung
In Experimenten verglichen die Forscher EBTs mit einer Transformer-Variante (Transformer++). Die Ergebnisse sollen zeigen, dass EBTs effizienter skalieren. Laut dem Paper erreichen sie eine bis zu 35 Prozent höhere Skalierungsrate in Bezug auf Datenmenge, Parameterzahl und Rechenaufwand. Das deute darauf hin, dass EBTs daten- und recheneffizienter sind.
Die eigentliche Stärke soll sich bei der "Denkskalierbarkeit" zeigen, also der Leistungssteigerung durch zusätzlichen Rechenaufwand zur Laufzeit. Hier konnten EBTs ihre Leistung bei Sprachaufgaben um bis zu 29 Prozent verbessern, insbesondere bei Aufgaben, die stark von den Trainingsdaten abweichen.
Im Vergleich mit Diffusion Transformers (DiTs) bei der Bildentrauschung sollen EBTs die Leistung der DiTs ebenfalls deutlich übertroffen und dafür 99 Prozent weniger Rechenschritte benötigt haben. Die von EBTs gelernten Bildrepräsentationen führten laut der Studie zu einer rund zehnmal höheren Klassifizierungsgenauigkeit auf ImageNet-1k, was auf ein besseres Verständnis der Inhalte hindeute.
Erhebliche Hürden in der Praxis
Trotz der vielversprechenden Ergebnisse gibt es offene Fragen. Ein zentrales Problem ist der Rechenaufwand: Das Training von EBTs erfordert laut dem Paper 3,3- bis 6,6-mal mehr Rechenleistung (FLOPs) als bei herkömmlichen Transformern. Dieser Mehraufwand könnte für viele praktische Anwendungen ein Hindernis sein. Zudem wird in der Studie die Fähigkeit zum "System 2-Denken" hauptsächlich durch Verbesserungen der Perplexität gemessen und nicht in tatsächlichen Reasoning-Aufgaben. Vergleiche mit modernen Reasoning-Modellen fehlen aufgrund von geringen Compute-Budgets für die Experimente ebenfalls.
Alle Vorhersagen zur Skalierung basieren aus dem gleichen Grund nur auf Experimenten mit Modellen von bis zu 800 Millionen Parametern. Das ist im Vergleich zu modernen KI-Modellen sehr klein. Ob die Vorteile bei solch großen Modellen bestehen bleiben, muss sich also erst zeigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.