Meta-Methode lässt KI-Agenten aus eigenen Fehlern lernen – ohne menschliches Feedback
Eine neue Trainingsmethode ermöglicht es KI-Agenten, aus ihren eigenen Erfahrungen zu lernen, ohne auf externe Belohnungssignale angewiesen zu sein. Die Systeme probieren selbstständig Aktionen aus und ziehen Lehren aus den Ergebnissen.
Herkömmliche KI-Agenten werden häufig mit menschlichen Demonstrationen trainiert. Diese Beispiele decken jedoch nur einen Bruchteil möglicher Situationen ab und führen zu schlechter Generalisierung auf neue Probleme. Forschende von Meta und der Ohio State University haben mit Early Experience nun eine Methode entwickelt, mit der Agenten zusätzlich aus ihren eigenen Erfahrungen lernen können.
Dabei führt der Agent in jeder Situation nicht nur die Experten-Aktion aus, sondern probiert auch alternative Handlungen aus und beobachtet die Folgen. Diese Erfahrungen werden dann als zusätzliche Trainingsdaten genutzt, ohne dass externe Belohnungssignale nötig sind.
Laut der Studie positioniert sich Early Experience als Mittelweg zwischen dem Imitation Learning und dem Reinforcement Learning. Während ersteres auf statischen Experten-Daten basiert, benötigt letzteres verifizierbare Belohnungen, die in vielen realen Umgebungen nicht verfügbar sind.
Zwei Strategien für autonomes Lernen
Die Wissenschaftler:innen entwickelten zwei konkrete Umsetzungen. Das "Implicit World Modeling" bringt dem Agenten bei, vorherzusagen, was nach bestimmten Aktionen passiert. Führt er beispielsweise auf einer Webseite einen Klick aus, soll er den resultierenden Seitenzustand vorhersagen können. Diese Vorhersagen werden als Trainingsziel verwendet.
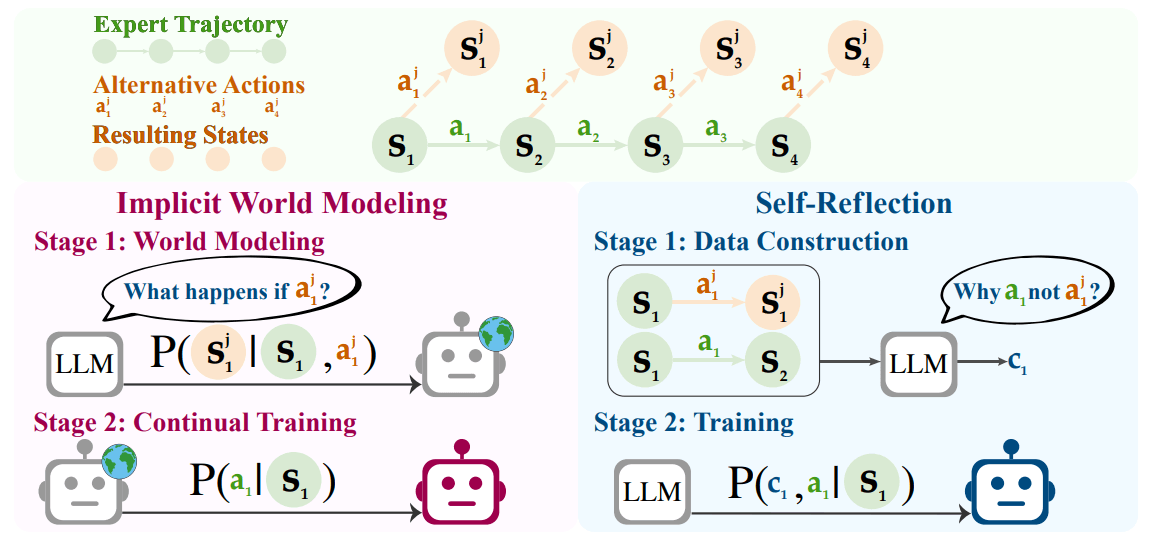
Die zweite Methode heißt "Self-Reflection". Hier vergleicht der Agent seine eigenen Aktionen mit den Experten-Lösungen und generiert natürlichsprachliche Erklärungen, warum die Experten-Aktion besser war. Bei einer Online-Shopping-Aufgabe könnte die Reflexion etwa erklären, dass ein teureres Produkt das vorgegebene Budget überschreitet.
Beide Ansätze nutzen dasselbe Grundprinzip: Die eigenen Aktionen des Agenten und deren Folgen werden zu Lernsignalen, ohne dass externe Bewertungen nötig sind.
Umfassende Tests zeigen deutliche Verbesserungen
Das Forschungsteam testete "Early Experience" in acht unterschiedlichen Umgebungen. Dazu gehörten Webseiten-Navigation, Haushaltsaufgaben in simulierten Wohnungen, wissenschaftliche Experimente, Multi-Turn-Tool-Use und komplexe Planungsaufgaben wie Reiseplanung.
Die Experimente liefen mit drei verschiedenen, eher kleinen Sprachmodellen, genauer Llama-3.1-8B, Llama-3.2-3B und Qwen2.5-7B. In allen Bereichen verbesserten beide "Early Experience"-Methoden die Leistung gegenüber herkömmlichem Training. Im Durchschnitt stieg die Erfolgsrate um 9,6 Prozentpunkte, die Leistung in unbekannten Situationen um 9,4 Prozentpunkte.
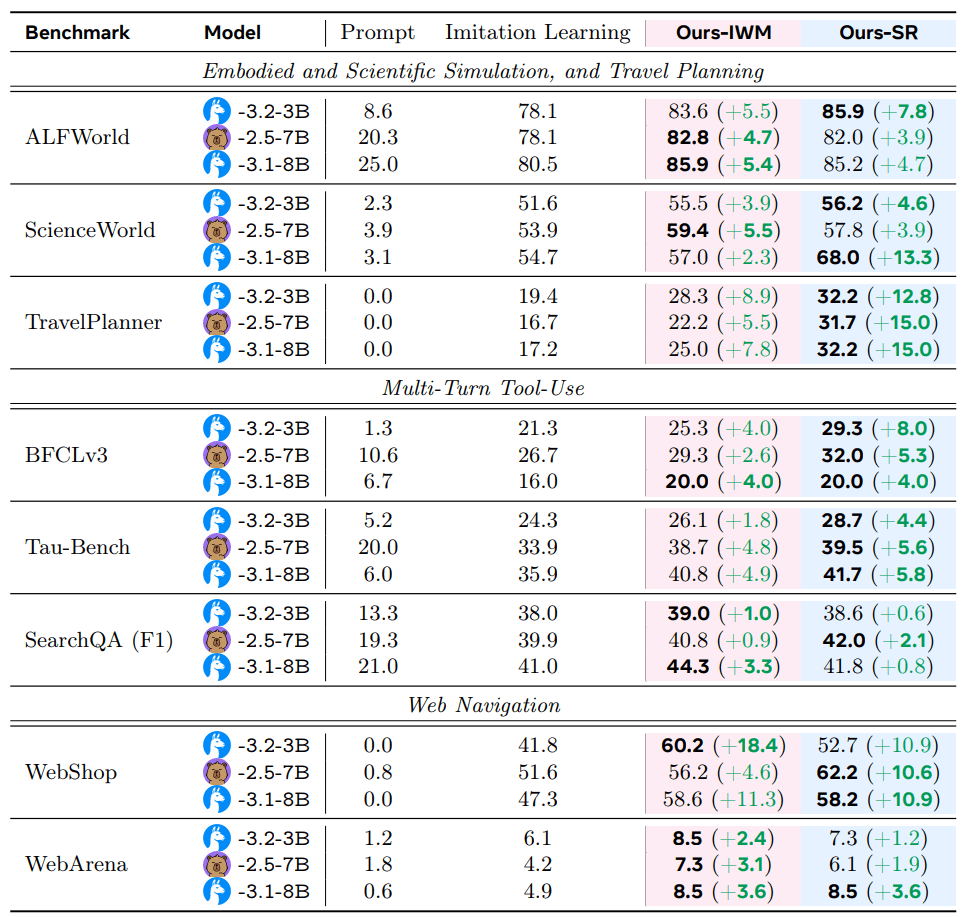
Besonders deutlich waren die Verbesserungen bei komplexen Aufgaben. Bei der Reiseplanung erreichte "Self-Reflection" bis zu 15 Prozentpunkte bessere Ergebnisse, beim Online-Shopping verbesserte sich das "Implicit World Modeling" um bis zu 18,4 Prozentpunkte.
Effektive Vorbereitung für Reinforcement Learning
In einigen Umgebungen sind Belohnungssignale verfügbar, die klassisches Reinforcement Learning ermöglichen. Die Forscher wollten daher wissen, ob "Early Experience" auch als Vorbereitung für diese fortgeschrittene Trainingsmethode taugt. Sie testeten dies in drei Bereichen und trainierten zunächst verschiedene Modelle mit unterschiedlichen Methoden. Anschließend wendeten sie auf alle Modelle das gleiche Reinforcement-Learning-Verfahren an.
Das Ergebnis war eindeutig: Modelle, die zunächst mit "Early Experience" trainiert wurden, erreichten nach dem anschließenden RL-Training durchweg bessere Endresultate. In einigen Fällen wuchs der Leistungsunterschied während des RL-Trainings sogar noch weiter an.
Die Methode produziert laut der Studie bereits ohne Belohnungen leistungsstarke Systeme und verstärkt die Vorteile des nachfolgenden Reinforcement Learning. Das positioniert "Early Experience" als praktische Brücke zwischen aktuellen und zukünftigen Trainingsmethoden.
Skalierung auf größere Modelle
Tests mit Modellen bis zu 70 Milliarden Parametern zeigten, dass "Early Experience" auch bei größeren Systemen funktioniert. Selbst mit ressourcenschonenden LoRA-Updates blieben die Verbesserungen erhalten.
Die Forschenden untersuchten auch, wie viele Expertendemos nötig sind. "Early Experience" behielt seinen Vorsprung auch bei reduzierter Datenmenge. Teilweise reichte bereits ein Achtel der ursprünglichen Demonstrationen aus, um herkömmliches Training mit dem vollständigen Datensatz zu übertreffen. Das deckt sich mit den Ergebnissen vorheriger Studien, dass oft nur wenig Trainingsbeispiele für konkurrenzfähige Leistung ausreichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.