Neue Methode "ComfyGen" erstellt aus Prompts Text-zu-Bild-Workflows

Forschende von Nvidia und der Universität Tel Aviv haben eine neue KI-Methode namens ComfyGen entwickelt, die aus Prompts Text-zu-Bild-Workflows erstellt. ComfyGen wählt etwa eigenständig das Modell, formuliert einen Prompt und kombiniert das Bild mit Tools wie Upscalern.
Bei der traditionellen Text-zu-Bild-Generierung nutzen Anwender:innen meist ein einzelnes Modell, um einen Textprompt in ein Bild umzuwandeln. In der Praxis setzen erfahrene Prompt Engineers jedoch häufig auf komplexe, mehrstufige Workflows, die verschiedene Komponenten wie Basismodelle, LoRAs, Prompt-Erweiterungen und Upscaling-Modelle kombinieren.
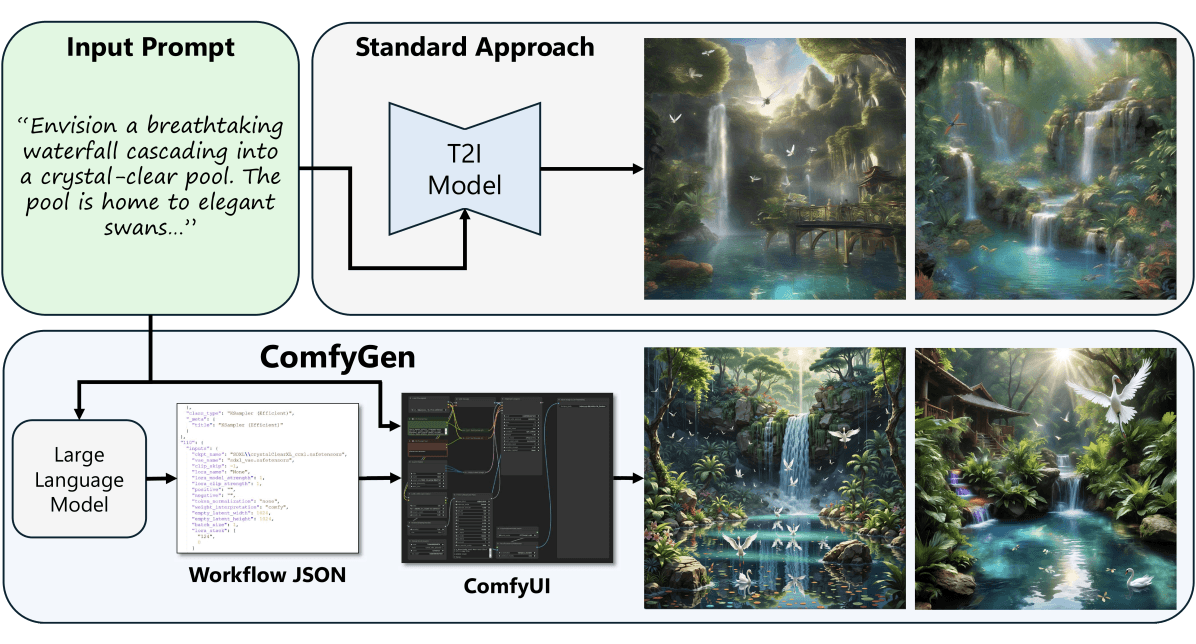
Die Wahl der Komponenten hängt dabei oft vom Inhalt des Prompts und dem zu generierenden Bild ab. Beispielsweise werden für fotorealistische Bilder andere Modelle benötigt als für Anime-Grafiken oder die Korrektur von Gesichtern und Händen. Das Forschungsteam nutzt nun ein wie Claude 3.5 Sonnet, um ausgehend von einem einzigen, kurzen Textprompt automatisch einen geeigneten Workflow zusammenzustellen.
ComfyGen baut auf dem beliebten Open-Source-Tool ComfyUI auf, mit dem Nutzer:innen Workflows im strukturierten JSON-Format definieren und austauschen können. Die Popularität von ComfyUI in der Stable-Diffusion-Community ermöglicht den Forschenden den Zugriff auf viele von Menschen erstellte Workflows als Trainingsdaten.
Um die Leistung der Arbeitsabläufe zu bewerten, sammelten die Forscher:innen 500 beliebte Prompts und generierten damit Bilder mit jedem Workflow. Die Ergebnisse wurden dann mit einer Mischung aus ästhetischen Prädiktoren und Modellen zur Schätzung menschlicher Präferenzen bewertet.
In-Context-Learning oder Finetuning
Das finale Modell erhält als Eingabe einen Prompt und eine Zielbewertung und generiert einen JSON-Workflow, der bei diesem Prompt die gewünschte Bewertung erreichen soll. Die Forscher testen zwei Ansätze:
- Beim In-Context-Learning erhält ein bestehendes LLM (Claude 3.5 Sonnet) eine Tabelle mit Workflows und deren durchschnittlichen Bewertungen für verschiedene Prompt-Kategorien. Bei Inferenz wählt das LLM dann für einen neuen Prompt den am besten passenden Arbeitsablauf aus.
- Beim Finetuning wird ein LLM (Llama-3.1-8B und -70B) direkt darauf trainiert, für einen gegebenen Prompt und eine Zielbewertung einen passenden Workflow vorherzusagen.
In Experimenten verglichen die Forscher ihren Ansatz mit monolithischen Modellen wie Stable Diffusion XL und dessen Varianten sowie mit festen, beliebten Workflows. Dabei schnitt ComfyGen sowohl bei automatischen Metriken als auch in Nutzer:innenstudien am besten ab. Die feinabgestimmte Variante schneidet dabei noch etwas besser ab als der Ansatz mit In-Context-Learning.
Die folgenden drei Bilder gingen alle vom Prompt "A photo of a cake and a stop sign" aus:



Eine Analyse der ausgewählten Workflows zeigte, dass die Modellauswahl oft zur Prompt-Kategorie passte. Beispielsweise werden für die Kategorie "People" verstärkt Gesichts-Upscaling-Modelle und für "Anime" anatomisch korrekte Modelle ausgewählt.
Vielversprechender Ansatz mit Verbesserungspotenzial
Der Vorteil der Methode ist, dass sie direkt auf bestehenden Arbeitsabläufen und Bewertungsmodellen aufbaut, die die Community erstellt hat. Damit lässt sich der Ansatz relativ einfach auf neue, erweiterte Workflows übertragen.
Das hat jedoch auch zur Folge, dass die Vielfalt und Originalität der generierten Workflows zu wünschen übrig lässt. Aktuell werden hauptsächlich aus den Trainingsdaten bekannte Arbeitsabläufe ausgewählt. Zukünftig wollen die Forscher:innen die Methode weiterentwickeln, um auch gänzlich neue Arbeitsabläufe zu generieren und sie auf Bild-zu-Bild-Aufgaben zu erweitern.
Solche promptabhängigen Workflows könnten die Einstiegshürde für Einsteiger:innen senken und gleichzeitig die Bildqualität verbessern. Spannend wäre den Forschenden zufolge auch eine Kombination mit agentenbasierten Ansätzen, bei denen das LLM im Dialog mit Nutzer:innen den Arbeitsablauf iterativ verfeinert.
Code oder eine Demo von ComfyGen haben die Forschenden bislang nicht veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.