Neue Methode passt Sprachmodelle ohne Training an

Forschende haben Text-to-LoRA entwickelt, das Anpassungsmodule für Large Language Models automatisch erstellt. Eine einfache Textbeschreibung der gewünschten Aufgabe soll ausreichen.
Große Sprachmodelle werden oft mit effizienten Methoden wie LoRA (Low-Rank Adaptation) an bestimmte Aufgaben angepasst. Dafür braucht man jedoch für jede neue Aufgabe eigene Trainingsdaten, passende Einstellungen, sogenannte Hyperparameter.
Diese legen zum Beispiel fest, wie schnell das Modell lernt oder wie oft es durch die Daten geht. Damit das Modell gute Ergebnisse liefert, müssen diese Einstellungen sorgfältig angepasst werden; ein zeitaufwendiger und rechenintensiver Prozess.
Text-to-LoRA (T2L) von dem japanischen KI-Start-up Sakana AI soll genau diesen Schritt automatisieren und damit die Anpassung deutlich vereinfachen.
Video: Sakana AI
LoRA-Adapter als effiziente Spezialisierungsmethode
LoRA-Adapter passen das Verhalten großer Sprachmodelle an, indem sie kleine, sogenannte niedrig-rangige Matrizen zu bestimmten Schichten des Modells hinzufügen. Im Vergleich zum vollständigen Fine-Tuning ist diese Methode viel effizienter, da nur wenige Millionen statt Milliarden von Modellparametern verändert werden müssen.
Text-to-LoRA (T2L) nutzt dafür ein sogenanntes Hypernetwork, ein lernendes System, das auf 479 Aufgaben aus dem Super Natural Instructions Dataset trainiert wurde. Dieses System hat gelernt, wie sich Aufgabenbeschreibungen mit passenden LoRA-Einstellungen (Adaptern) verknüpfen lassen. Für eine neue Aufgabe kann es so in nur einem Rechenschritt die passenden LoRA-Gewichte erzeugen, selbst wenn es diese Aufgabe noch nie gesehen hat.

Sakana AI hat drei Architekturvarianten entwickelt: T2L-L mit 55 Millionen Parametern generiert beide LoRA-Matrizen (A und B) simultan, T2L-M mit 34 Millionen teilt sich eine Ausgabeschicht für beide Matrizen, während T2L-S mit 5 Millionen Parametern nur einzelne Ränge der Matrizen erzeugt.
Supervised Fine-Tuning übertrifft Rekonstruktionstraining
Die Forscher:innen verglichen zwei Trainingsmethoden für T2L: Beim Rekonstruktionstraining lernt das System, bereits existierende LoRA-Adapter nachzubilden. Beim Supervised Fine-Tuning (SFT) wird T2L hingegen direkt auf die Zielaufgaben trainiert.
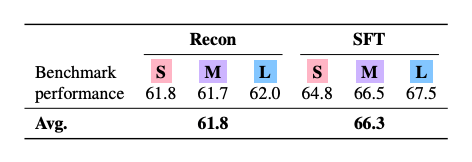
Die Ergebnisse zeigen klare Vorteile für SFT: Während rekonstruktionstrainierte Modelle im Schnitt 61,8 Prozent der Benchmark-Leistung erreichten, kamen SFT-Modelle auf 66,3 Prozent. Die Forschenden erklären das damit, dass SFT ähnliche Aufgaben automatisch gruppieren kann, während Rekonstruktion auf bereits optimierte, aber teils uneinheitliche Adapter angewiesen ist.
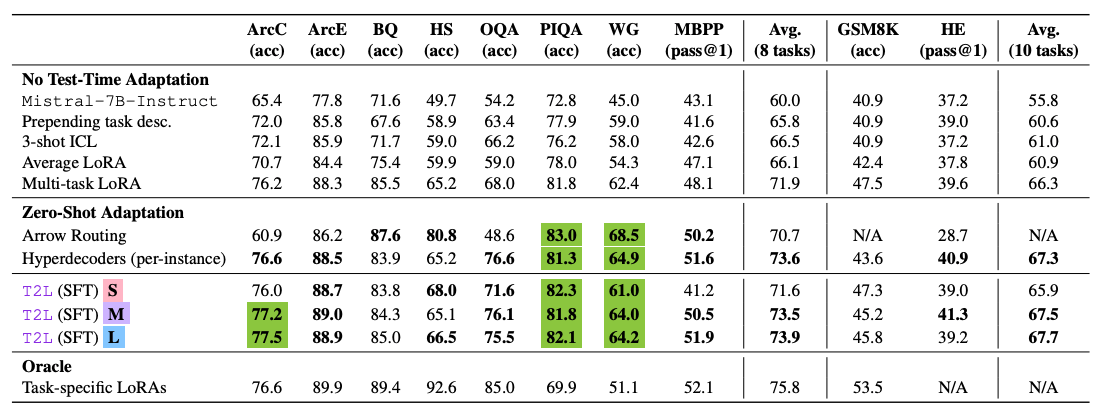
In Tests auf zehn Standard-Benchmarks erreichte das beste T2L-Modell 67,7 Prozent durchschnittliche Leistung. Bei einem direkteren Vergleich auf acht Benchmarks erzielte T2L 74,0 Prozent gegenüber 75,8 Prozent bei aufgabenspezifischen LoRA-Adaptern. Das entspricht etwa 98 Prozent der Referenzleistung bei eliminiertem Trainingsaufwand.
Generalisierung auf unbekannte Aufgaben mit Einschränkungen
T2L kann LoRA-Adapter auch für gänzlich neue, zuvor nicht gesehene Aufgaben erzeugen. Dabei übertraf es sowohl Multi-Task-LoRA-Baselines als auch andere Vergleichsmethoden. Allerdings hängt die Leistung stark davon ab, wie ähnlich die neue Aufgabe den Aufgaben aus den Trainingsdaten ist. Je größer die inhaltliche Nähe, desto besser funktioniert die Generalisierung.
Ein zentraler Faktor für die Leistung war die Qualität der Aufgabenbeschreibung: Präzise und aufgabenorientierte Formulierungen führten zu Ergebnissen, die nahe an spezialisierten Adaptern lagen. Ungenaue oder unpassende Beschreibungen hingegen führten zu deutlich schlechteren Resultaten.
T2L bietet laut der Studie erhebliche Effizienzvorteile: Es benötigt über viermal weniger Rechenoperationen als klassische Fine-Tuning-Methoden und kommt vollständig ohne aufgabenspezifische Trainingsdaten aus. Die Robustheit des Ansatzes wurde auch in Kombination mit verschiedenen Basismodellen wie Llama-3.1-8B und Gemma-2-2B bestätigt.
Die Hauptgrenzen des Systems liegen laut den Forschenden in zwei Bereichen: der starken Abhängigkeit von der Formulierung der Aufgabenbeschreibung und einer noch bestehenden Leistungslücke zu spezialisierten LoRA-Adaptern, insbesondere bei komplexen Aufgaben, die stark von den Trainingsdaten abweichen. Trotzdem sehen sie in T2L einen wichtigen Schritt hin zur automatisierten Anpassung großer Sprachmodelle.
Den Code samt Installationsanleitung stellt Sakana AI auf GitHub zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.