Neue Methode von Deepseek stabilisiert Signale beim Training großer KI-Modelle
Forscher von Deepseek haben eine Methode entwickelt, die das Training großer Sprachmodelle stabiler macht. Der Ansatz nutzt mathematische Einschränkungen, um ein bekanntes Problem bei erweiterten Netzwerkarchitekturen zu lösen.
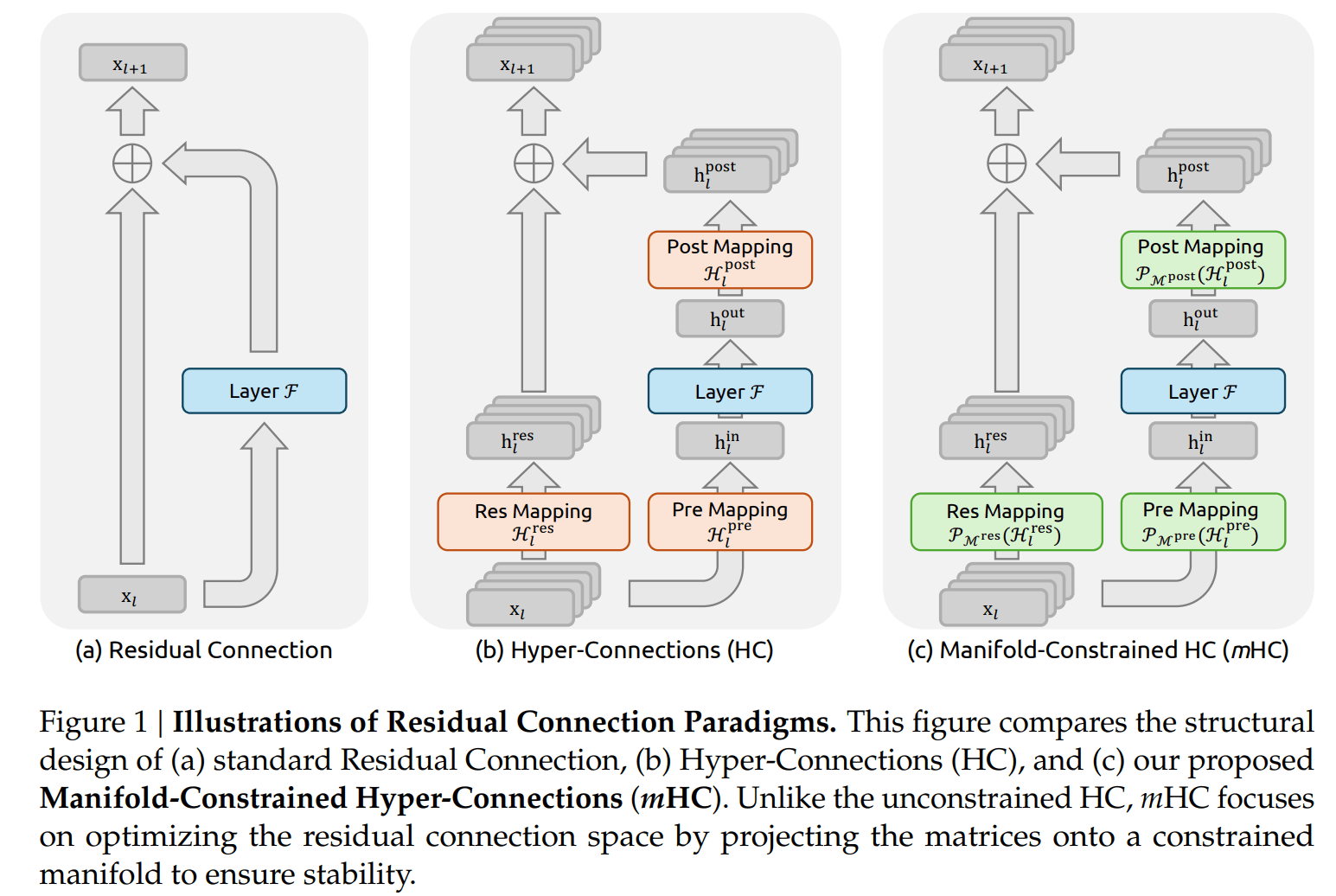
Neuronale Netze nutzen seit einem Jahrzehnt sogenannte Residual Connections, um Informationen durch tiefe Architekturen zu leiten. Man kann sich diese Verbindungen als Abkürzungen vorstellen: Informationen aus frühen Schichten des Netzwerks gelangen direkt zu späteren Schichten, was das Training stabiler macht. Neuere Ansätze wie "Hyper-Connections" (HC) erweitern dieses Prinzip, indem sie den Informationsfluss verbreitern und komplexere Verbindungsmuster einführen.
Das Problem laut den Forschern: Diese Erweiterungen bringen zwar Leistungsgewinne, destabilisieren aber das Training bei größeren Modellen. Die Forscher von Deepseek haben nun mit "Manifold-Constrained Hyper-Connections" (mHC) eine Lösung vorgestellt, die beide Vorteile vereinen soll.
Warum erweiterte Verbindungen das Training zum Entgleisen bringen
Bei klassischen Residual Connections bleibt das Signal auf seinem Weg durch das Netzwerk im Wesentlichen unverändert. Diese Eigenschaft sorgt dafür, dass das Training stabil bleibt: Die Fehler, aus denen das Modell lernt, werden zuverlässig durch alle Schichten zurückgeleitet, und die Anpassungen bleiben meistens im Rahmen des Gewünschten.
Bei Hyper-Connections hingegen durchläuft das Signal lernbare Matrizen, die es transformieren. Das ist gewollt, denn so kann das Netzwerk komplexere Muster lernen. Das Problem entsteht jedoch, wenn sich diese Veränderungen über viele Schichten hinweg aufschaukeln. Statt das Signal unverändert weiterzuleiten, kann es mit jeder Schicht stärker verstärkt oder abgeschwächt werden.
Die Forscher dokumentieren das Problem anhand eines 27-Milliarden-Parameter-Modells: Bei etwa 12.000 Trainingsschritten zeigt HC einen plötzlichen Anstieg des Verlusts, also der Fehlerrate, aus der das Modell lernt. Ein solcher Sprung ist vor allem ein Warnsignal: Das Training wird instabil – und die Lernsignale (Gradienten) geraten aus dem Takt.
Die Ursache liegt laut dem Team darin, wie stark Signale auf ihrem Weg durch das Netzwerk verstärkt werden. Die Forscher messen dies mit einer Kennzahl, die idealerweise bei 1 liegen sollte: Das Signal kommt genauso stark an, wie es losgeschickt wurde. Bei HC erreicht dieser Wert jedoch Spitzen von 3.000. Das bedeutet, dass Signale um das Dreitausendfache verstärkt werden, was unweigerlich zu Problemen führt.
Zusätzlich verursacht HC erheblichen Overhead beim Speicherzugriff. Da der Informationsfluss um einen Faktor von etwa 4 verbreitert wird, steigen auch die Speicherzugriffe entsprechend an.
Mathematische Leitplanken halten Signale unter Kontrolle
Der Kern von mHC besteht darin, die lernbaren Verbindungsmatrizen mathematisch einzuschränken. Die Forscher nutzen dafür Matrizen mit einer besonderen Eigenschaft: Alle Einträge sind nicht-negativ, und sowohl die Zeilen- als auch die Spaltensummen ergeben exakt 1.
Was bedeutet das praktisch? Wenn eine solche Matrix auf ein Signal angewendet wird, entsteht eine gewichtete Mischung der Eingangswerte. Da die Gewichte positiv sind und zusammen 1 ergeben, entsteht eine Art gewichtete Mischung der Eingangswerte. Dadurch werden die Signale zwar umverteilt, aber nicht unkontrolliert verstärkt – selbst dann nicht, wenn viele solcher Schritte hintereinander folgen. Auch wenn viele solcher Matrizen hintereinander angewendet werden, bleibt diese Eigenschaft erhalten.
Um eine beliebige Matrix in diese Form zu bringen, verwenden die Forscher ein iteratives Verfahren namens Sinkhorn-Knopp-Algorithmus. Dieser normalisiert abwechselnd Zeilen und Spalten, bis beide auf 1 summieren. In der Implementierung werden 20 solcher Durchläufe verwendet, was laut den Experimenten einen guten Kompromiss zwischen Genauigkeit und Rechenaufwand darstellt.
Das Ergebnis: Die Signalverstärkung sinkt von 3000 auf etwa 1.6, also um drei Größenordnungen. Die Signale bleiben damit nahe an ihrer ursprünglichen Stärke, und das Training verläuft stabil.
Bessere Ergebnisse bei stabilerem Training
Die Forscher haben mHC an Modellen mit 3, 9 und 27 Milliarden Parametern getestet, basierend auf der Deepseek-V3-Architektur. Das 27B-Modell zeigt stabile Trainingskurven ohne die bei HC beobachteten Einbrüche.
Bei den Benchmark-Ergebnissen übertrifft mHC sowohl die Baseline als auch HC auf den meisten Tests. Auf dem BBH-Benchmark, der komplexe Reasoning-Aufgaben testet, erreicht mHC 51,0 Prozent gegenüber 48,9 bei HC und 43,8 bei der Baseline. Beim DROP-Benchmark, der Leseverständnis mit numerischem Schlussfolgern kombiniert, sind es 53,9 gegenüber 51,6 und 47,0. Die Verbesserungen gegenüber HC fallen mit 2,1 beziehungsweise 2,3 Prozentpunkten moderat aus, die Stabilität während des Trainings ist jedoch deutlich besser.
Die Skalierungsexperimente zeigen, dass die Vorteile von mHC über verschiedene Modellgrößen und Trainingsbudgets hinweg erhalten bleiben. Die relative Verbesserung gegenüber der Baseline nimmt bei größeren Modellen nur geringfügig ab.
Optimierungen halten den Mehraufwand gering
Um mHC praxistauglich zu machen, haben die Forscher erheblichen Aufwand in die technische Umsetzung gesteckt. Durch geschickte Zusammenfassung von Rechenoperationen werden Speicherzugriffe reduziert. Ein selektives Verfahren speichert nur die notwendigsten Zwischenergebnisse und berechnet den Rest bei Bedarf neu, was den Speicherbedarf senkt.
Besondere Aufmerksamkeit galt der Integration in das DualPipe-Verfahren, das bei Deepseek-V3 für die Verteilung des Trainings auf viele GPUs verwendet wird. Die Forscher haben die Kommunikation zwischen den Recheneinheiten so optimiert, dass sie parallel zur eigentlichen Berechnung stattfindet.
Das Ergebnis: mHC verursacht nur 6,7 Prozent zusätzlichen Zeitaufwand gegenüber der Standard-Architektur. Angesichts der Stabilitäts- und Leistungsgewinne erscheine dieser Overhead vertretbar.
Die Forscher sehen in mHC einen Ausgangspunkt für weitere Untersuchungen zu Netzwerktopologien. Das Framework erlaube die Exploration verschiedener mathematischer Einschränkungen, die auf spezifische Lernziele zugeschnitten werden könnten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.