Neue Studie unterstützt Apples Zweifel an "denkender" KI, bleibt aber optimistisch
Forscher der New York University haben mit RELIC (Recognition of Languages In-Context) einen neuen Test vorgestellt, der untersucht, wie gut große Sprachmodelle, komplexe, mehrteilige Anweisungen verstehen und umsetzen können. Das Team zeigt ähnliche Ergebnisse wie ein kürzlich veröffentlichtes Apple-Paper, sieht aber weiterhin Optimierungspotenzial.
Das KI-Modell bekommt eine formale Grammatik – im Grunde ein exaktes Regelwerk, das eine künstliche Sprache definiert – und eine Zeichenfolge. Dann soll es entscheiden, ob diese Zeichenfolge nach den Regeln der Grammatik korrekt gebildet ist.
Ein "Satz" (symbolisiert als S) besteht aus einem "Teil A" gefolgt von einem "Teil B" (Regel: S → A B). "Teil A" wiederum besteht aus "Symbol C" und "Symbol D" (A → C D), und so weiter, bis schließlich Regeln wie "'Symbol C' wird zu 't43'" (C → ‘t43’) auftauchen. Die KI muss nun prüfen, ob eine Zeichenfolge wie "t43 t51 t66 t72" durch diese Regeln erzeugt werden kann. Wichtig ist dabei: Die KI erhält keine Beispiele für richtige oder falsche Zeichenfolgen oder spezifisches Training für die jeweilige Grammatik, sie muss die Regeln "Zero-Shot" anwenden, nur anhand der im Kontext gegebenen Beschreibung.
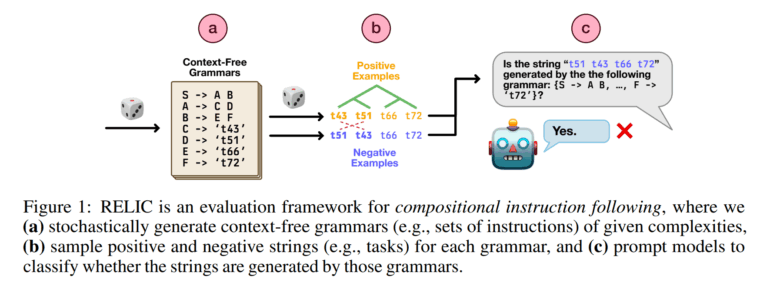
Um das zu schaffen, muss die KI viele einzelne Regeln (sogenannte Produktionsregeln) korrekt erkennen und in der richtigen, nicht vorab festgelegten Reihenfolge anwenden – oft auch mehrfach und verschachtelt. Das ähnelt laut dem Team der Überprüfung, ob ein Computerprogramm fehlerfrei geschrieben ist oder ein Satz grammatikalisch stimmt. Die Grammatikregeln sind dabei von zwei Arten: Solche, die abstrakte Platzhalter (Nichtterminale wie S, A, B) in andere Platzhalter aufteilen (z.B. S → A B), und solche, die einen Platzhalter durch ein konkretes Wort oder Symbol (Terminale wie 't43') ersetzen (z.B. C → ‘t43’). Mit RELIC können so unendlich viele neue Testaufgaben mit unterschiedlichem Schwierigkeitsgrad automatisch erstellt werden. Das verhindert, dass die Ergebnisse durch bereits bekannte Testdaten verzerrt werden.
RELIC zeigt ein bekanntes Muster
Die Wissenschaftler testeten acht verschiedene KI-Modelle, darunter OpenAIs GPT-4.1 und o3, Googles Gemma-Modelle und DeepSeek-R1. Für ihre Studie entwickelten sie den spezifischen Testdatensatz RELIC-500. Dieser enthält 200 verschiedene Grammatiken mit bis zu 500 Einzelregeln für abstrakte Satzteile und Test-Zeichenfolgen mit bis zu 50 Symbolen. Selbst diese komplexesten Grammatiken in RELIC-500 sind laut den Forschern aber noch deutlich einfacher als die Regelwerke, die reale Programmiersprachen oder menschliche Sprachen beschreiben.
Bei einfachen Grammatiken und kurzen Zeichenfolgen schnitten die Modelle noch recht gut ab. Wurde die Grammatik aber komplexer oder die Zeichenfolge länger, stürzte die Genauigkeit der KI-Antworten rapide ab – selbst bei Modellen, die eigentlich auf logisches Schlussfolgern spezialisiert sind, wie OpenAIs o3 oder DeepSeek-R1. Ein zentrales Ergebnis: Die Modelle scheinen oft theoretisch zu "wissen", wie sie die Aufgabe lösen müssten – zum Beispiel durch eine vollständige Analyse der Struktur (Parsing), also dem Nachvollziehen der Regelanwendungen –, wenden dieses Wissen in der Praxis aber nicht konsequent an.
Während die KI-Modelle einfache Aufgaben – also Grammatiken mit wenigen Regeln und kurze Zeichenfolgen – meist korrekt lösten, änderte sich ihre Strategie bei steigender Komplexität deutlich. Anstatt systematisch zu prüfen, ob die Zeichenfolge den Grammatikregeln entspricht (also einen korrekten "Ableitungsbaum" zu finden), griffen sie vermehrt auf vereinfachende heuristische Verfahren zurück.
Sie schauten beispielsweise nur, ob die Zeichenfolge besonders lang ist (und nahmen dann fälschlich an, sie sei korrekt) oder ob einzelne Wörter oder Symbole der Zeichenfolge irgendwo auf der rechten Seite der Grammatikregeln auftauchen. Letzteres sagt aber nichts darüber aus, ob die Reihenfolge korrekt ist.
Studie zeigt "Underthinking" bei hoher Komplexität
Um die "Denk"-Strategien der Modelle zu untersuchen, setzten die Forscher ein weiteres KI-Modell – OpenAIs o4-mini – sozusagen als "KI-Richter" ein. Dieser sollte die Lösungsansätze der anderen Modelle bewerten. Die Urteile des KI-Richters wurden stichprobenartig mit menschlichen Einschätzungen verglichen und stimmten zu 70 Prozent überein, wobei o4-mini besonders gut darin war, oberflächliche Lösungsansätze zu erkennen.
Es zeigte sich: Bei kurzen und einfachen Beispielen versuchten die Modelle meist, die Regeln korrekt anzuwenden, etwa indem sie einen logischen Aufbau der Zeichenfolge (einen „Parse-Baum“) Schritt für Schritt erstellten. Bei längeren oder komplexeren Beispielen verfielen sie jedoch in die genannten oberflächlichen Heuristiken.
Ein Kernproblem, das die Studie aufdeckt, ist der Zusammenhang zwischen der Komplexität einer Aufgabe und dem Rechenaufwand, den die KI während des Tests betreibt (Test-Time Compute, TTC), gemessen an der Länge dieser Denk-Zwischenschritte. Theoretisch müsste dieser Aufwand bei Aufgaben wie der Grammatikerkennung mit der Länge der Eingabe deutlich ansteigen. Doch die Forscher beobachteten genau das Gegenteil: Bei kurzen Zeichenfolgen, beispielsweise bis zu einer Länge von 6 Symbolen bei GPT-4.1-mini oder 12 Symbolen bei o3, erzeugten die Modelle noch vergleichsweise viele Denk-Zwischenschritte. Wurden die Aufgaben aber länger und komplexer, nahm diese Anzahl ab.
Das bedeutet: Die Modelle brechen ihre Denkprozesse vorzeitig ab, bevor sie überhaupt eine Chance haben, die Struktur vollständig zu analysieren. Diese Verringerung der "Denktiefe" bei schwierigen Aufgaben erinnert stark an ein Phänomen, das Apple-Forscher kürzlich in einem viel beachtetem Paper beschrieben haben. Dort zeigten KI-Modelle wie Claude 3.7 oder DeepSeek-R1 bei steigender Schwierigkeit paradoxerweise ebenfalls weniger Denkaktivität.
KI-Modelle benötigen mehr Rechenleistung oder müssen effizientere Lösungswege finden
Beide Untersuchungen zeigen also, dass auch aktuelle Reasoning-Modelle zwar einfache Aufgaben lösen können, bei wachsender Komplexität jedoch grundlegend versagen – und dabei paradoxerweise weniger, statt mehr "nachdenken". RELIC geht aber über die eher spielerischen Testszenarien der Apple-Studie (wie virtuelle Puzzles) hinaus, indem es eine Fähigkeit prüft, die für den Alltag wichtiger ist: das Erlernen und Anwenden neuer Sprachen oder Regelwerke allein durch die im Kontext gegebenen Informationen.
RELIC testet dabei auch direkt eine anspruchsvollere Form der Kontextnutzung als bisherige Benchmarks, wie zum Beispiel sogenannte „Nadel im Heuhaufen“-Tests, bei denen es nur darum geht, eine einzelne Information in einem langen Text wiederzufinden. Bei RELIC sind die relevanten Regeln hingegen dicht im Text verteilt und müssen auf komplexe Weise kombiniert werden.
Die theoretische Analyse der Aufgabenkomplexität legt laut dem Team nahe, dass zukünftige Sprachmodelle entweder über deutlich mehr Rechenleistung - und damit Reasoning-Tokens - für die eigentliche Problemlösung (Inferenz) verfügen oder grundlegend effizientere Lösungsansätze für solche Probleme finden müssen. Die Fähigkeit, komplexe Anweisungen zu verstehen und umzusetzen, so betonen die Forscher, sei fundamental für die Weiterentwicklung wirklich intelligenter KI-Systeme.
"Wenn die aktuellen Modelle dazu nicht in der Lage sind, brauchen wir stärkere Modelle. Das bedeutet nicht, dass LLMs nicht 'schlussfolgern' können, oder dass LRMs nicht schlussfolgern, oder dass Deep Learning kaputt ist. Es heißt nur, dass die Fähigkeit dieser Modelle zu 'schlussfolgern' derzeit begrenzt ist, und wir sollten versuchen, sie zu verbessern", bringt Co-Autor Tal Linzen die Ergebnisse auf den Punkt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.