Neuer Benchmark entlarvt große Wissenslücken bei KI-Modellen – nur vier schaffen positive Bewertung

Ein neuer Benchmark von Artificial Analysis zeigt erschreckende Schwächen bei der faktischen Zuverlässigkeit von KI-Modellen auf. Von 40 getesteten Modellen erreichen nur vier einen positiven Score, Googles neues Gemini 3 Pro führt deutlich.
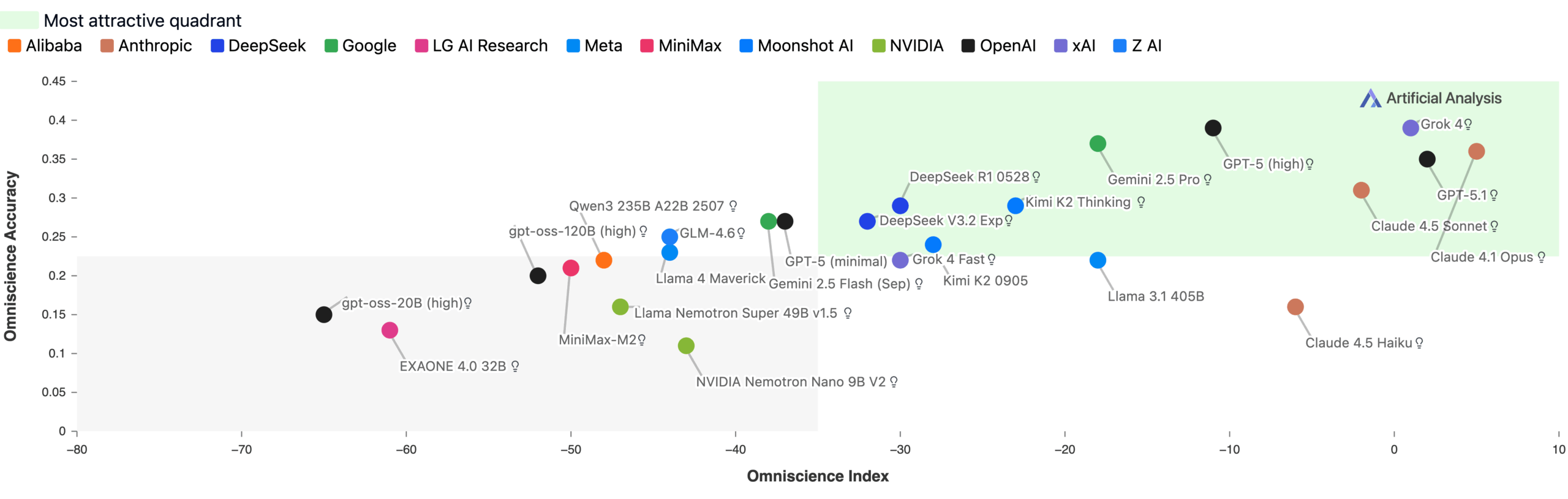
Gemini 3 Pro erreichte 13 Punkte auf der neuen Omniscience-Index-Skala von −100 bis 100 und liegt damit deutlich vor Claude 4.1 Opus (4,8), GPT‑5.1 und Grok 4. Der neue Spitzenwert basiert vor allem auf der sehr hohen Accuracy: Gemini 3 Pro lag hier 14 Punkte über Grok 4, dem zuvor genauesten Modell. Ein Score von 0 bedeutet, dass ein Modell genauso oft richtig wie falsch antwortet. Der AA‑Omniscience Benchmark misst die Zuverlässigkeit, korrektes Wissen abzurufen, über verschiedene Fachdomänen hinweg.
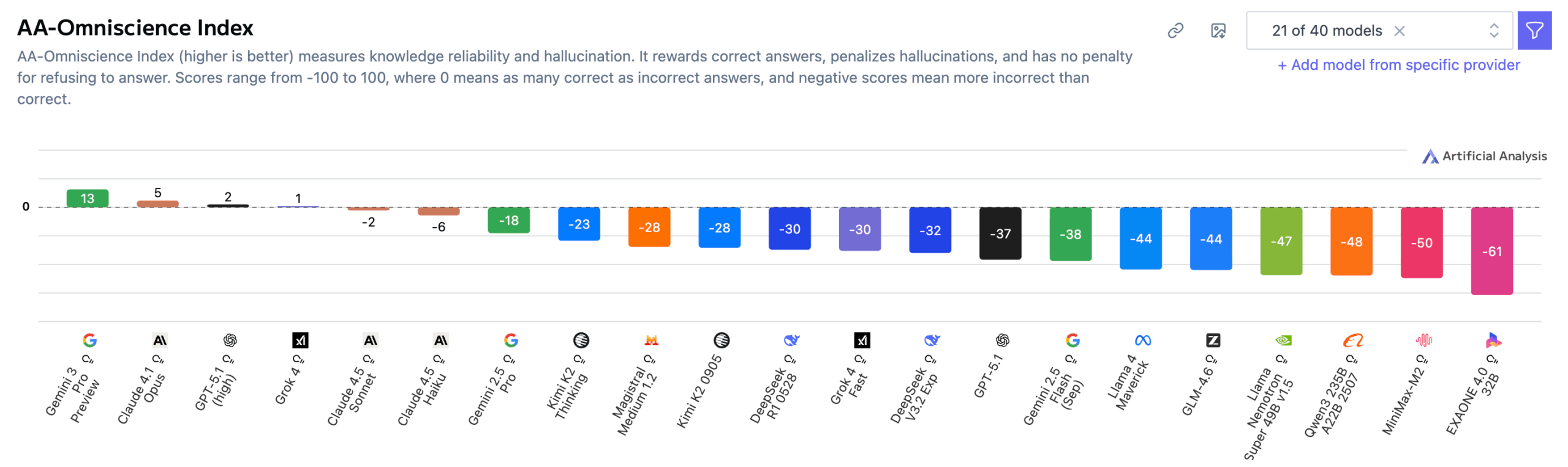
Laut Artificial Analysis basiert die neue Führung von Gemini 3 Pro vor allem auf einer stark erhöhten Accuracy: Das Modell lag ganze 14 Punkte über Grok 4, dem bis dahin genauesten Modell im Benchmark. Die Forscher interpretieren diese hohe Accuracy als Hinweis auf eine sehr große Modellgröße, da Accuracy im Benchmark stark mit Modellgröße korreliert.
Halluzinationen als Hauptproblem
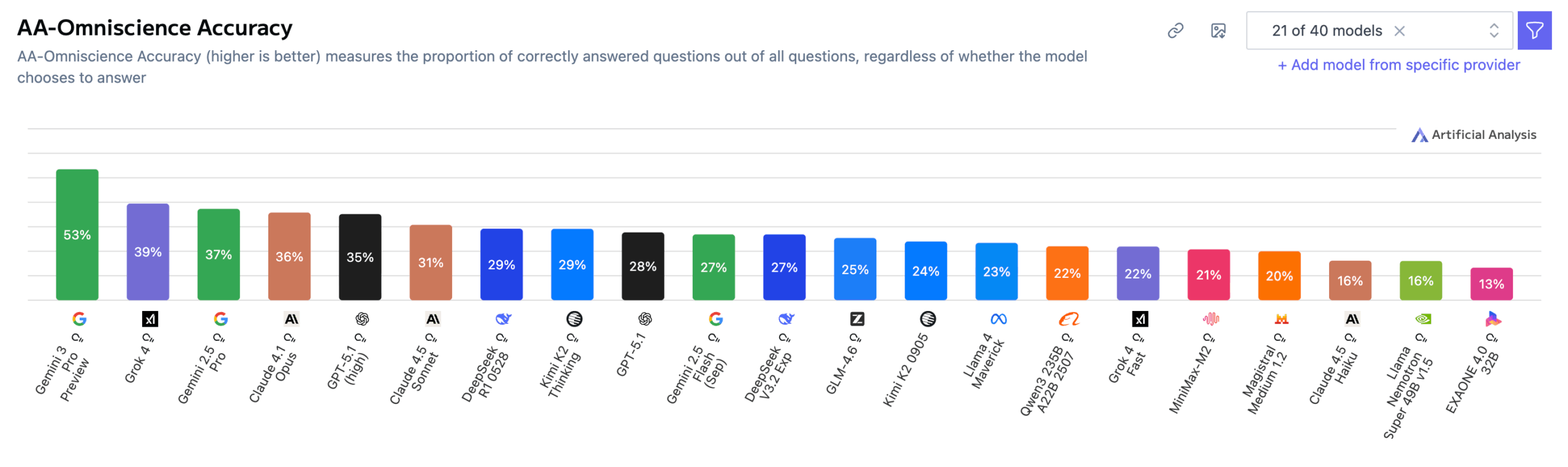
Das schlechte Abschneiden liegt hauptsächlich an hohen Halluzinationsraten. Gemini 3 Pro erreicht zwar mit 53 Prozent die höchste Accuracy im gesamten Testfeld und liegt damit deutlich vor früheren Spitzenmodellen wie GPT‑5.1 (high) und Grok 4 (jeweils 39 Prozent), zeigt jedoch gleichzeitig eine Halluzinationsrate von 88 Prozent – identisch mit Gemini 2.5 Pro und Gemini 2.5 Flash.
GPT‑5.1 (high) und Grok 4 lagen mit 81 beziehungsweise 64 Prozent ebenfalls hoch, doch Gemini 3 Pro übertrifft sie nochmals deutlich. Artificial Analysis schließt daraus, dass Gemini 3 Pro zwar erheblich mehr abrufbares Wissen besitzt, seine Bereitschaft, falsche Antworten statt einer Verweigerung auszugeben, aber unverändert hoch ist.
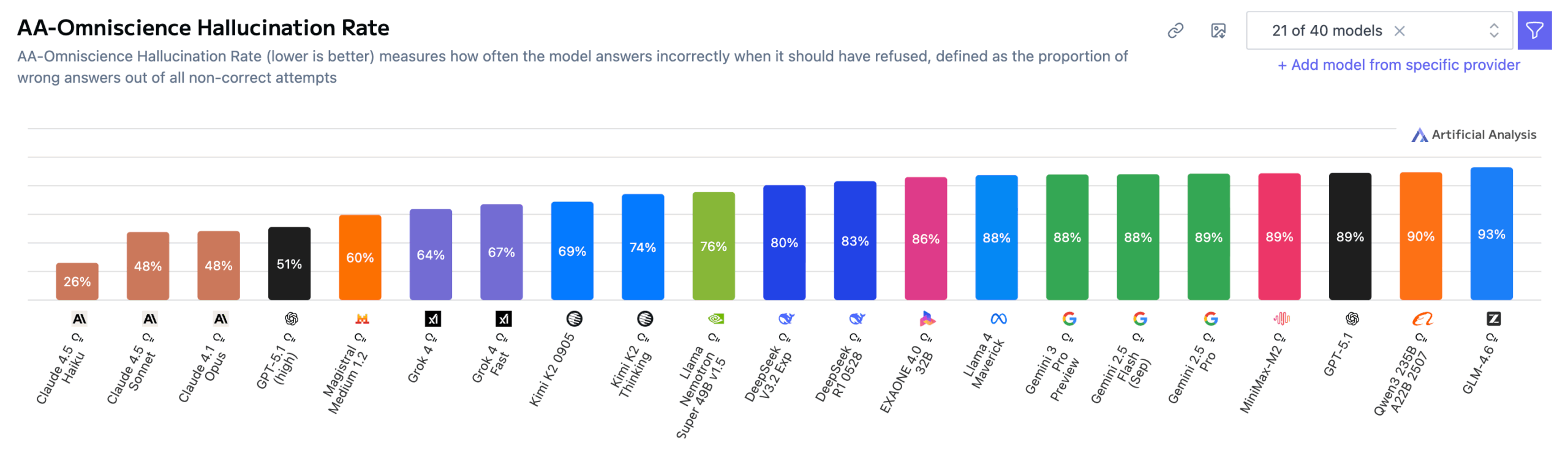
Die Halluzinationsrate wird also definiert als der Anteil falscher Antworten an allen nicht-korrekten Versuchen. Ein hoher Wert bedeutet daher nicht Unwissen, sondern eine mangelnde Zurückhaltung.
Claude 4.1 Opus erreichte dagegen 36 Prozent Genauigkeit bei einer der niedrigsten Halluzinationsraten und erzielte so vor Veröffentlichung von Gemini 3 Pro den besten Gesamtscore.
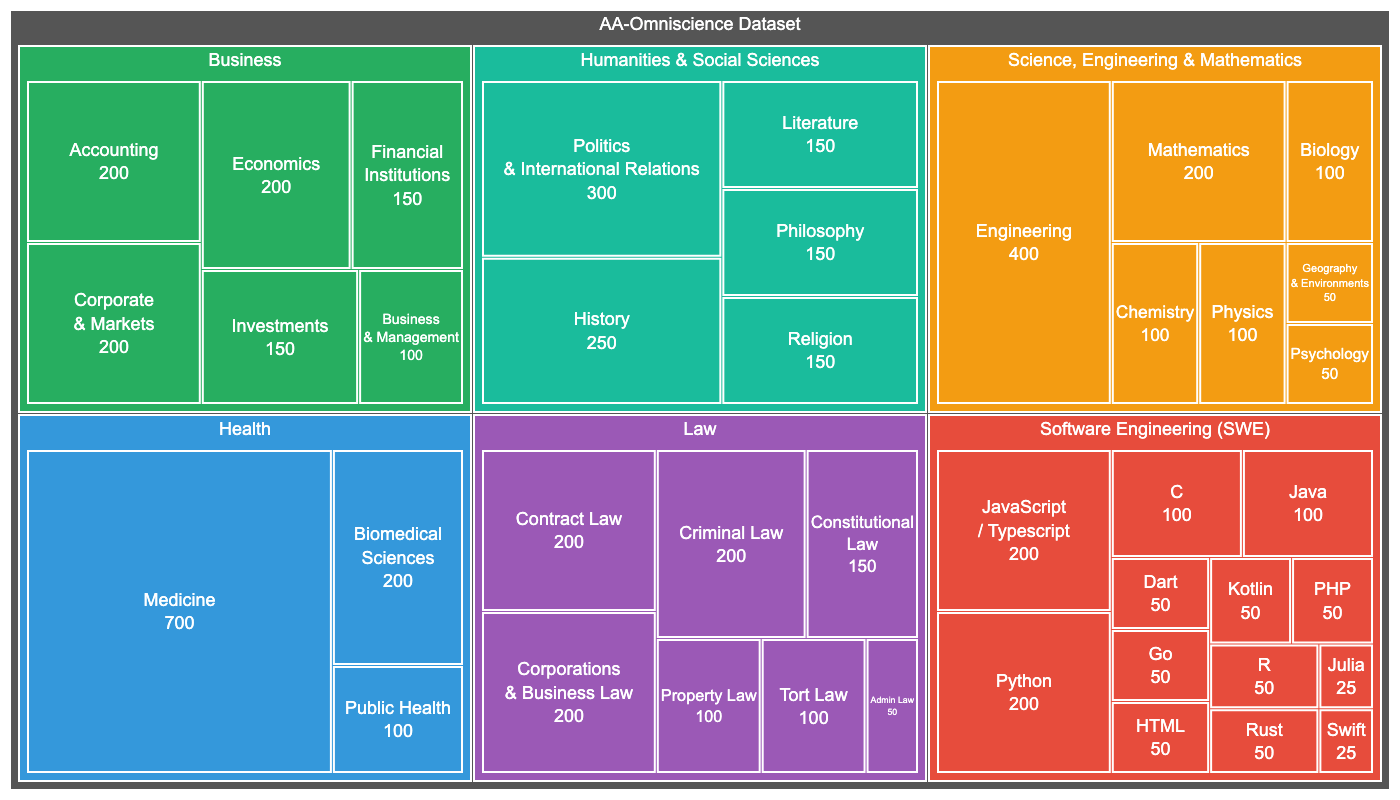
Der AA-Omniscience Benchmark umfasst 6.000 Fragen aus 42 ökonomisch relevanten Themenbereichen in sechs Domänen: Business, Geisteswissenschaften & Sozialwissenschaften, Gesundheit, Recht, Software Engineering sowie Naturwissenschaften & Mathematik. Die Fragen stammen aus autoritativen akademischen und industriellen Quellen und wurden automatisiert durch einen KI-Agenten generiert.
Neue Bewertungsmetrik bestraft Modell-Raten
Anders als herkömmliche Benchmarks bestraft der Omniscience Index falsche Antworten genauso stark, wie er korrekte belohnt. Die Forscher argumentieren, dass aktuelle Evaluierungen das Raten bei Unsicherheit belohnen und so Halluzinationstendenzen verstärken.
Die neue Metrik belohnt stattdessen Zurückhaltung: Modelle erhalten für das Eingestehen von Unwissen keine Punkte, aber auch keine Abzüge. Im Gegensatz dazu werden falsche Antworten stark bestraft.
Die Ergebnisse zeigen vier Kategorien von Modellen: Solche mit viel Wissen und höherer Zuverlässigkeit (wie Claude 4.1 Opus), solche mit viel Wissen aber niedriger Zuverlässigkeit (wie Claude 4.5 Haiku), Modelle mit wenig Wissen aber hoher Zuverlässigkeit (wie GPT-5.1) und schließlich Modelle mit sowohl wenig Wissen als auch niedriger Zuverlässigkeit wie OpenAIs kleine Version von gpt-oss.
Für Gemini 3 Pro liegen in der Studie keine domänenspezifischen Einzelwerte vor.
Überraschender Erfolg für älteres Llama-Modell
Allgemeine Intelligenz korreliert nicht zwangsläufig mit faktischer Zuverlässigkeit. Modelle wie Minimax M2 und gpt-oss-120b (high) erreichen laut der Studie starke Scores im aus mehreren industrieweiten Benchmarks aggregierten Artificial Analysis Intelligence Index, versagen aber aufgrund hoher Halluzinationsraten beim Omniscience Index.
Umgekehrt schnitt das mittlerweile schon etwas ältere Llama-3.1-405B beim Omniscience Index gut ab, obwohl es in allgemeinen Evaluierungen oft unter aktuellen Frontier-Modellen rangiert.
Kein einzelnes Modell zeigt durchgängig die beste Wissenszuverlässigkeit über alle sechs bewerteten Domänen hinweg. Während Claude 4.1 Opus in Recht, Software Engineering und Geisteswissenschaften führt, erreicht GPT-5.1.1 die höchste Zuverlässigkeit bei Business-Fragen. Grok 4 schneidet am besten in Gesundheit und Naturwissenschaften ab.
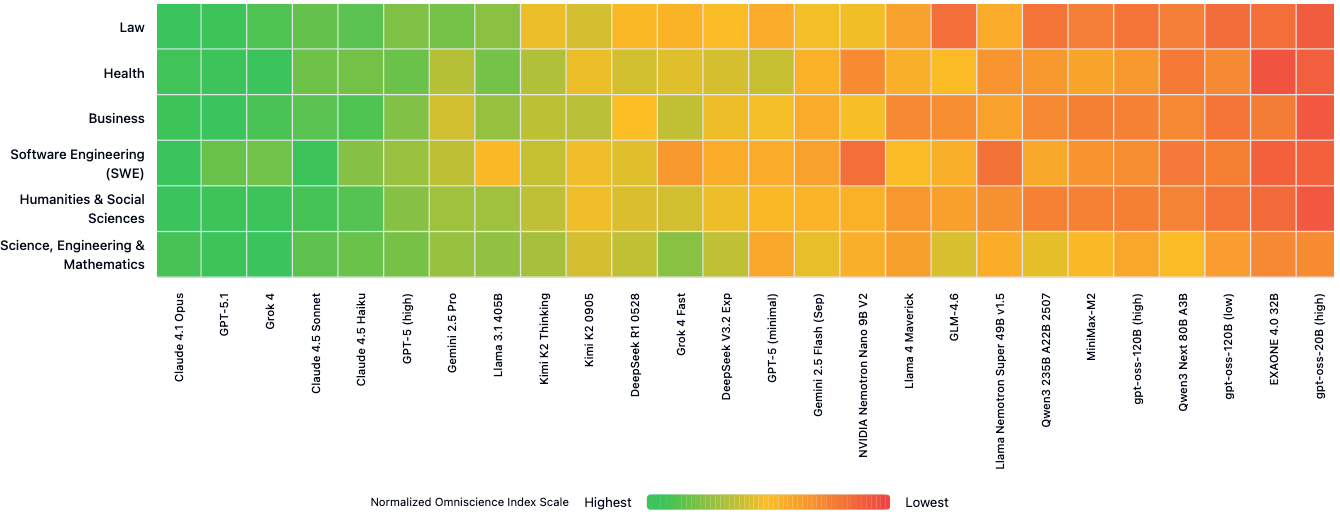
Diese Ergebnisse zeigen laut der Studie, dass die Modellauswahl basierend auf der Gesamtleistung wichtige Unterschiede auf Domänenebene verschleiert. "Für Anwendungen, die spezialisiertes Wissen erfordern, ist domänenspezifische Evaluierung unerlässlich", heißt es in dem Forschungspapier.
Größe garantiert keine Zuverlässigkeit
Obwohl größere Modelle tendenziell genauer sind, zeigen sie nicht zwangsläufig niedrigere Halluzinationsraten. Mehrere kleinere Modelle wie Nvidias Nemotron Nano 9B V2 und Llama Nemotron Super 49B v1.5 übertreffen gleich große oder größere Konkurrenten beim Omniscience Index.
Artificial Analysis bestätigt zusätzlich, dass Accuracy stark mit Modellgröße korreliert, die Halluzinationsrate jedoch nicht. Das erklärt, warum Gemini 3 Pro trotz sehr hoher Accuracy weiterhin eine starke Halluzinationsneigung zeigt.
Bei der Kosteneffizienz sticht Claude 4.5 Haiku hervor: Es erreicht einen höheren Omniscience Index als mehrere deutlich teurere Modelle wie GPT-5.1 (high) und Kimi K2 Thinking.
Die Forscher haben 10 Prozent der Fragen als öffentlichen Datensatz veröffentlicht, um weitere Forschung zu ermöglichen, während der Großteil privat bleibt, um Kontamination der Trainingsdaten zu verhindern.
Erst kürzlich hatte eine andere Studie fundamentale Schwächen in KI-Benchmarks aufgedeckt. Die Forscher kritisierten dabei vor allem unklare Definitionen von Schlüsselkonzepten wie "Reasoning", bequeme Stichprobenauswahl ohne Repräsentativitätsprüfung und fehlende statistische Validierung bei Modellvergleichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.