Neuer Benchmark zeigt: KI-Modelle halluzinieren immer noch viel zu oft

Ein neuer Benchmark von Forschern aus der Schweiz und Deutschland zeigt, dass selbst Spitzenmodelle wie Claude Opus 4.5 mit aktivierter Websuche noch in knapp einem Drittel aller Fälle falsche Informationen produzieren. Besonders das sogenannte Content Grounding bleibt ein ungelöstes Problem.
Große Sprachmodelle erreichen mittlerweile Goldmedaillen-Niveau bei mathematischen Olympiaden, doch ihre Zuverlässigkeit hält mit diesen Fähigkeiten nicht Schritt. Forscher der Schweizer Universität EPFL, des ELLIS Institute Tübingen und des Max-Planck-Instituts für Intelligente Systeme haben mit "Halluhard" einen neuen Benchmark entwickelt, der Halluzinationen in realistischen Gesprächen mit mehreren Frage-Antwort-Runden misst.
Der Benchmark umfasst 950 Ausgangsfragen in vier sensiblen Wissensgebieten: Rechtsfälle, Forschungsfragen, medizinische Leitlinien und Programmierung. Für jede Ausgangsfrage generierte ein separates Nutzermodell zwei Folgefragen, sodass realistische Konversationen mit jeweils drei Gesprächsrunden entstanden.
Selbst die stärkste getestete Konfiguration, Claude Opus 4.5 mit aktivierter Websuche, halluzinierte laut der Studie noch in rund 30 Prozent der Fälle. Ohne Websuche lag die Rate bei etwa 60 Prozent. GPT-5.2 Thinking mit Websuche kam auf eine Halluzinationsrate von 38,2 Prozent.
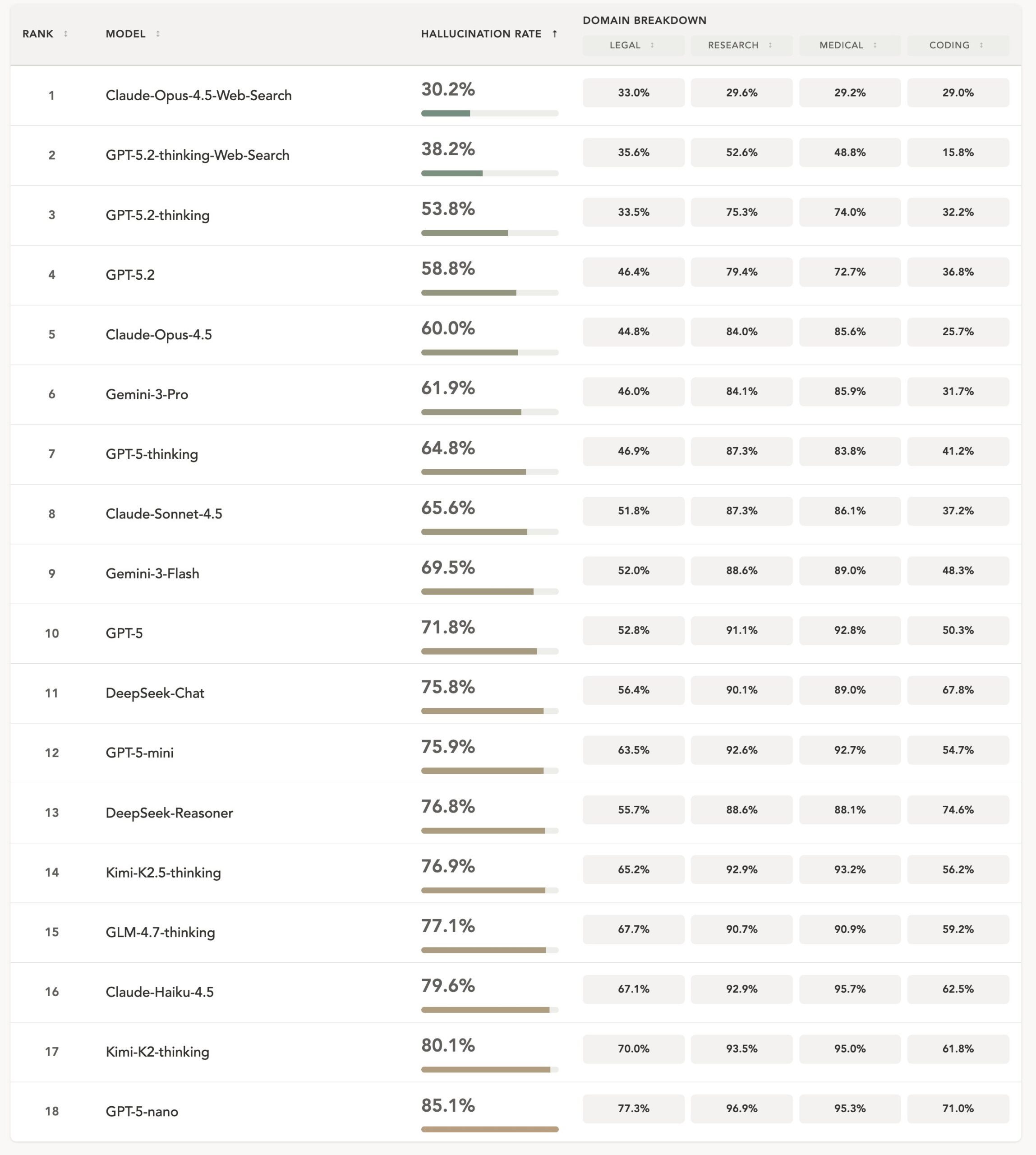
Am schlechtesten schnitten chinesische Reasoning-Topmodelle wie Kimi-K2-Thinking und GLM-4.7-Thinking ab im Vergleich zu westlichen Reasoning-Modellen. Häufig handelt es sich dabei um offene Modelle, die in anderen Benchmarks mit westlichen Spitzenmodellen mithalten können. Das nährt den Verdacht, dass sie gezielt für Benchmarkergebnisse optimiert wurden.
Größere Modelle halluzinieren weniger, Reasoning hilft nur bedingt
Größere Modelle halluzinieren tendenziell seltener. Innerhalb der GPT-5-Familie sank die durchschnittliche Halluzinationsrate von 85,1 Prozent bei GPT-5-nano auf 71,8 Prozent bei GPT-5 und weiter auf 53,8 Prozent bei GPT-5.2 Thinking. Bei Claude zeigte sich ein ähnliches Muster: 79,5 Prozent für Haiku, 65,6 Prozent für Sonnet und 60 Prozent für Opus.
Reasoning, also das "längere Nachdenken" vor einer Antwort, reduziert Halluzinationen – doch mehr Rechenaufwand für das Nachdenken bringt nicht zwangsläufig weitere Verbesserungen. Modelle mit stärkerem Reasoning produzierten längere, detailliertere Antworten mit mehr Behauptungen, was wiederum mehr Angriffsfläche für Fehler bot.
Bemerkenswert: DeepSeek-Reasoner zeigte trotz Reasoning-Fähigkeiten keine Verbesserung gegenüber DeepSeek-Chat. Die Forscher sprechen von einer anhaltenden Lücke zwischen proprietären Modellen und Open-Source-Alternativen.
Websuche reduziert KI-Halluzinationen, beseitigt sie aber nicht
Die Forscher unterscheiden zwischen zwei Arten von Halluzinationen: Reference Grounding prüft, ob eine zitierte Quelle überhaupt existiert. Content Grounding prüft, ob die Quelle den behaupteten Inhalt tatsächlich stützt.
Diese Unterscheidung offenbart ein subtiles, aber häufiges Versagen: Ein Modell kann eine passende Quelle zitieren und dennoch Details fabrizieren, die diese Quelle gar nicht belegt. Die Forscher nennen als Beispiel eine Behauptung über den SimpleQA-Benchmark, bei der die Referenz zwar korrekt war, der Inhalt aber teilweise erfunden.

Die Daten aus dem Forschungsfragen-Setting zeigen, dass Websuche vor allem Reference-Fehler reduziert. Bei Claude Opus 4.5 sank die Reference-Fehlerrate mit Websuche von 38,6 auf 7 Prozent. Die Content-Grounding-Fehler gingen dagegen deutlich weniger zurück: von 83,9 auf 29,5 Prozent. Ähnlich bei GPT-5.2 Thinking: Die Reference-Fehler sanken mit Websuche auf 6,4 Prozent, die Content-Grounding-Fehler lagen aber weiterhin bei 51,6 Prozent.
Längere Chats können zu mehr Halluzinationen führen
Ein zentraler Befund betrifft die Dynamik über mehrere Gesprächsrunden hinweg: In späteren Runden stieg die Halluzinationsrate an. Die Forscher erklären das damit, dass Modelle die gesamte bisherige Konversation als Kontext erhalten und dabei auf ihre eigenen früheren Fehler aufbauen. Zwischen 3 und 20 Prozent der falschen Referenzen aus der ersten Runde tauchten in späteren Runden erneut auf. Schon frühere Studien zeigten, dass lange Chats und zugemüllte Kontextfenster die Leistung von KI-Modellen verschlechtern.
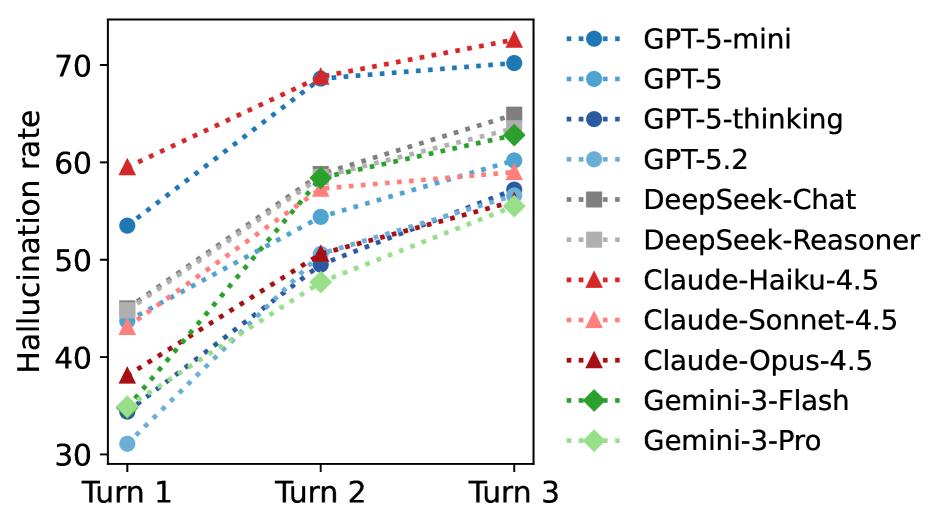
Bei Coding-Aufgaben zeigte sich ein umgekehrter Trend: Die Halluzinationsrate sank in späteren Runden. Die Forscher vermuten, dass sich die Aufgaben im Gesprächsverlauf verengen – von breiten Anforderungen wie "baue X" zu spezifischen Fragen wie "behebe diese Funktion". Engere Aufgaben lassen weniger Raum für kreative, aber falsche Lösungen.
Modelle kämpfen mit Nischenwissen
In einem kontrollierten Experiment mit 350 Kurzfragen untersuchten die Forscher, wann Modelle halluzinieren und wann sie sich enthalten. Bei komplett erfundenen Entitäten neigten Modelle eher dazu, keine Antwort zu geben. Bei Nischenwissen, etwa wenig zitierten Forschungsarbeiten oder Kunstwerken aus lokalen Galerien, halluzinierten sie hingegen deutlich häufiger.
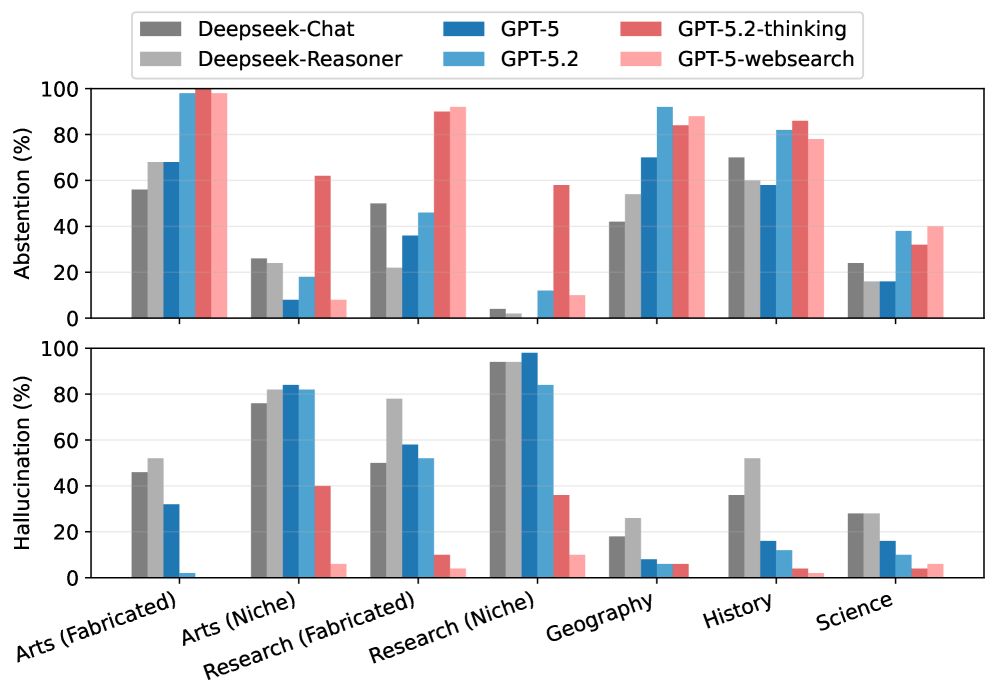
Die Forscher erklären das damit, dass Nischeninformationen nur bruchstückhaft in den Trainingsdaten auftauchen. Diese Bruchstücke reichen aus, um eine Antwort auszulösen, aber nicht für eine korrekte. Bei gänzlich unbekannten Themen besteht zumindest die Chance, dass ein Modell seine Unwissenheit eingesteht.
Bestehende Benchmarks stoßen an ihre Grenzen
Die Forscher begründen die Notwendigkeit eines neuen Benchmarks damit, dass bestehende Tests kaum noch Unterscheidungskraft bieten. Bei SimpleQA erreichte GPT-4o mit Search Preview bereits 90 Prozent Genauigkeit, GPT-5 Thinking mit Websuche sogar 95,1 Prozent. Bei einer geschätzten Benchmark-Fehlerrate von etwa 3 Prozent sei die Obergrenze damit praktisch erreicht.
"Halluhard" soll durch die Kombination aus mehreren Gesprächsrunden, sensiblen Wissensgebieten und Nischenwissen auch für künftige Modellgenerationen anspruchsvoll bleiben. Der Benchmark und der Code sind auf GitHub verfügbar, die Ergebnisse wurden außerdem auf einer Projektseite veröffentlicht.
Der Benchmark zeigt: KI-Modelle halluzinieren noch immer häufig – auch wenn Nvidia-CEO Jensen Huang das Gegenteil behauptet. Wie sich Halluzinationen dennoch reduzieren lassen, erfahrt ihr in unserem Einstiegsvideo und im Deep Dive zum Thema (beides heise KI Pro).
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.