Neues Adobe-Modell "MultiFoley" generiert passende Geräusche für Filme

Forschende der University of Michigan und Adobe Research haben ein KI-System entwickelt, das Geräusche für Filme, sogenannte Foley-Sounds, für Videos generieren kann.
MultiFoley ermöglicht es Nutzer:innen, die generierten Sounds über Textprompts, Referenzaudio oder Videobeispiele zu steuern. In Beispielen lassen die Forschenden das System das Miauen einer Katze in ein Löwengebrüll verwandeln oder Schreibmaschinengeräusche wie ein Klavier klingen lassen. Die generierten Sounds synchronisieren sich dennoch auf beeindruckende Weise mit dem Bildinhalt.
Video: Adobe
Eine Besonderheit des Systems ist laut den Forschenden die Fähigkeit, hochwertige Audioausgaben in voller Bandbreite (48kHz) zu erzeugen. Dies wurde durch ein spezielles Trainingsverfahren erreicht, bei dem sowohl Internet-Videos als auch professionelle Soundeffekt-Bibliotheken verwendet wurden.
Laut dem Paper ist es außerdem das erste System, das mehrere Steuerungsmöglichkeiten - also Text, Audio und Video als Referenz - in einem einzigen Modell vereint.
Die exakte zeitliche Abstimmung zwischen Video und generiertem Audio erreicht MultiFoley durch einen speziellen Synchronisationsmechanismus: Das System analysiert zunächst die visuellen Merkmale des Videos mit einer Bildrate von 8 Frames pro Sekunde. Diese werden dann auf die höhere Audioabtastrate von 40 Hz hochgerechnet und mit den Audiolatenzmerkmalen kombiniert.

Laut dem Paper ermöglicht diese Technik eine durchschnittliche Synchronisationsgenauigkeit von 0,8 Sekunden - deutlich besser als bisherige Systeme, die meist über einer Sekunde Versatz lägen.
Bessere Ergebnisse als bisherige Systeme
In quantitativen Tests übertraf MultiFoley die Leistung bestehender Systeme in mehreren wichtigen Metriken. Besonders bei der Audio-Video-Synchronisation und der semantischen Übereinstimmung zwischen Text und generiertem Audio schnitt das System deutlich besser ab als die Vergleichsmodelle.
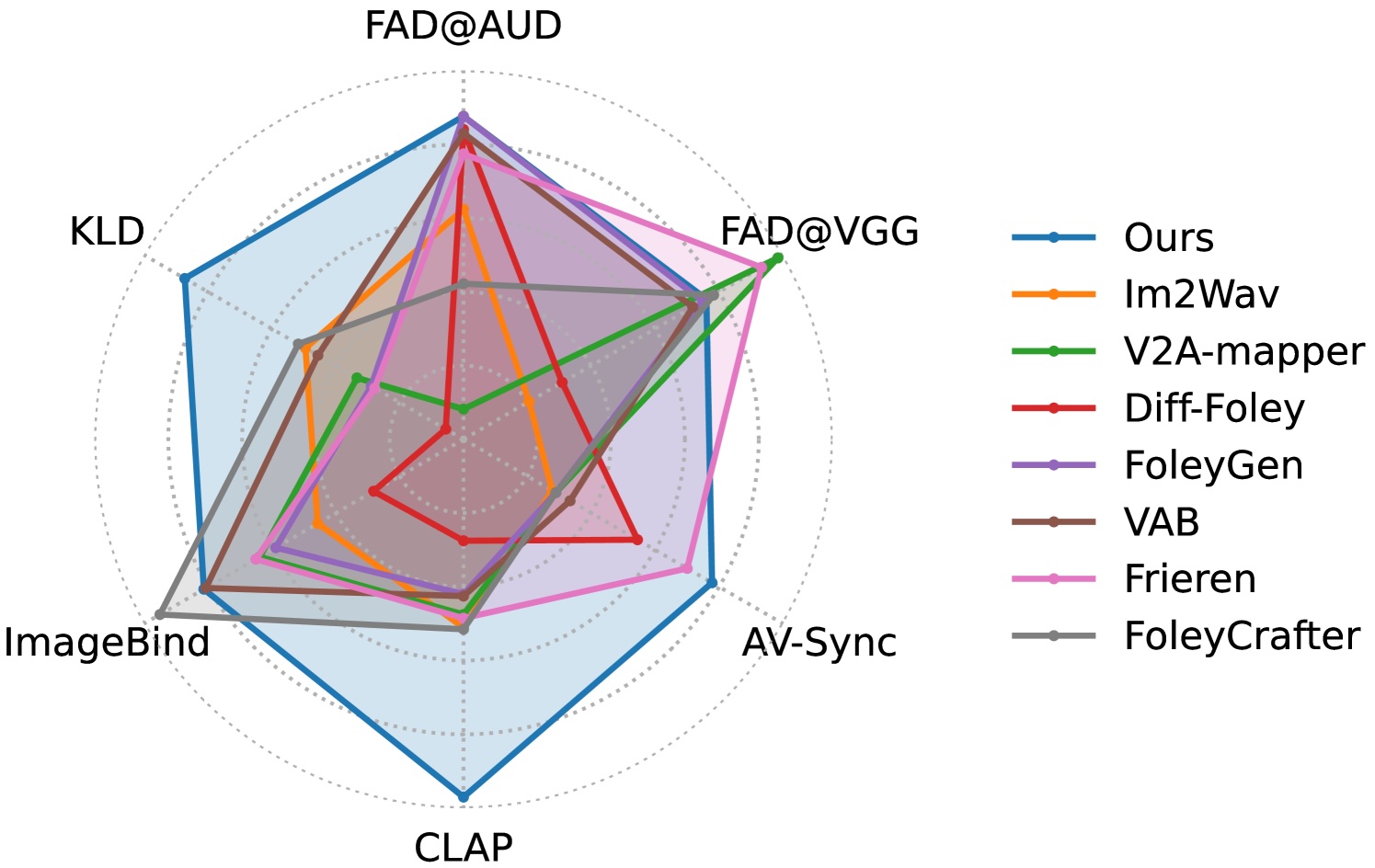
Eine Nutzer:innenstudie bestätigte diese Ergebnisse: 85,8 Prozent der Teilnehmer bewerteten die semantische Übereinstimmung der von MultiFoley generierten Sounds als besser im Vergleich zum nächstbesten System. Bei der Synchronisation waren es sogar 94,5 Prozent.
Die Forschenden weisen darauf hin, dass das System derzeit noch Einschränkungen hat. So wurde es nur mit einem relativ kleinen Datensatz trainiert, was die Vielfalt der möglichen Soundeffekte begrenzt. Auch bei der gleichzeitigen Verarbeitung mehrerer Soundereignisse stößt das System noch an seine Grenzen.
Das Team arbeitet bereits an Verbesserungen und sieht großes Potenzial für den Einsatz in der Filmproduktion, Spieleentwicklung und anderen kreativen Bereichen, wo bisher aufwendige manuelle Foley-Arbeit nötig war.
Veröffentlichung steht noch aus
Der Quellcode und die Modelle sollen in Kürze öffentlich zugänglich gemacht werden. Ob und wann diese Forschung in einem kommerziellen Produkt landet, bleibt abzuwarten.
Angesichts bereits zahlreicher generativer KI-Fähigkeiten in Adobes Schnittprogramm Premiere Pro würde es sich jedoch gut in die Funktionspalette einfügen. Neben Einzelanwender:innen dürfte die Foley-Sound-Generation außerdem bei Produktionsfirmen auf offene Ohren stoßen, die zunehmend mit KI-Unternehmen kooperieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.