Neues Lernmodell von Google soll katastrophales Vergessen in KI-Systemen stoppen

Google Research hat ein neues Lernparadigma namens "Nested Learning" entwickelt, das KI-Modelle als verschachtelte Optimierungsprobleme betrachtet. Der Ansatz zielt darauf ab, das "katastrophale Vergessen" zu mindern oder sogar ganz zu vermeiden, und liefert Prinzipien für kontinuierliches Lernen.
Die Google-Forscher beschreiben in ihrer auf der NeurIPS 2025 vorgestellten Studie ein fundamentales Problem aktueller KI-Modelle. Große Sprachmodelle können nach ihrem Training keine neuen Langzeiterinnerungen bilden, ähnlich wie Patienten mit bestimmten Hirnverletzungen.
Das Wissen bleibt auf den unmittelbaren Kontext oder die während des Trainings erworbenen Informationen beschränkt. Größere Kontextfenster oder häufigeres Nachtrainieren sind dafür nur ein Notbehelf; so, als würde man Amnesie mit einem größeren Notizblock behandeln.
Der Grund: Aktuelle Modelle haben primär eine einzige „Lerngeschwindigkeit“. Alle Parameter werden so behandelt, als müssten sie bei jeder neuen Information gleichzeitig und gleich schnell angepasst werden. Es fehlt eine explizite Hierarchie von Update‑Zeitskalen.
Dieses kontinuierliche Aktualisieren führe zum katastrophalen Vergessen. Wenn Modelle neue Aufgaben erlernen, verschlechtert sich ihre Leistung bei bereits erlernten Aufgaben. Das kontinuierliche Aktualisieren der Modellparameter mit neuen Daten löst das Problem nicht, sondern verstärkt es oft.
Menschliches Gehirn dient als Inspiration
Die Forscher orientierten sich wie auch andere KI-Konzepte an der menschlichen Gedächtnisbildung. Unser Gehirn arbeitet nicht mit einer einheitlichen Geschwindigkeit, sondern mit mehreren Zeitskalen: Es gibt schnelle, flüchtige Prozesse für den aktuellen Moment (Kurzzeitgedächtnis) und langsamere, selektive Prozesse, die wichtige Informationen in ein dauerhaftes Langzeitgedächtnis überführen.
Wichtig ist: Nicht alles wird laufend umgeschrieben – langsamere Ebenen wachen nur gelegentlich auf, um aus vielen kurzlebigen Eindrücken die wirklich relevanten Muster zu destillieren. Das menschliche Gehirn kann durch Neuroplastizität seine Struktur als Reaktion auf neue Erfahrungen verändern und dabei Erinnerungen beibehalten. Diese Fähigkeit – gleichzeitig anpassungsfähig und stabil zu sein – fehlt aktuellen KI-Modellen weitgehend, weil ihnen eine vergleichbare Hierarchie von Lern- und Gedächtnisgeschwindigkeiten fehlt.

Trainingsalgorithmen als Gedächtnissysteme
Das Nested-Learning-Paradigma betrachtet alle Elemente eines KI-Modells als Gedächtnissysteme. Diese Sichtweise umfasst auch die Trainingsalgorithmen selbst. Die Forscher zeigen, dass der Backpropagation-Prozess als Gedächtnissystem verstanden werden kann, das Datenpunkte auf ihre Fehlerwerte abbildet. Selbst der Optimierer wird damit zu einem eigenen „Speicher“: Sein interner Zustand (etwa Momentum) gilt als Gedächtnis vergangener Updates, nicht nur als technisches Hilfsmittel.

Auch Optimierungsalgorithmen funktionieren nach diesem Prinzip. Sie speichern Informationen über vergangene Trainingsschritte und nutzen diese für zukünftige Anpassungen. Diese Erkenntnis ermöglicht es, Trainingsalgorithmen gezielter zu entwickeln.
Nested Learning führt dafür das Continuum Memory System (CMS) ein, das über die traditionelle Aufteilung in Kurz- und Langzeitgedächtnis hinausgeht. Statt nur zwei Gedächtnistypen gibt es verschiedene Gedächtnismodule, die mit unterschiedlichen Frequenzen aktualisiert werden – von sehr schnell (für den aktuellen Kontext) bis sehr langsam (für dauerhaftes Wissen).
Die Forscher erklären, dass jede Ebene ihre eigene Update-Frequenz und ihren eigenen Zuständigkeitsbereich hat. Schnelle Ebenen reagieren nahezu in Echtzeit auf neue Eingaben, langsame Ebenen integrieren nur gelegentlich verdichtete Muster aus den schnelleren Schichten. Parameter werden je nach ihrer Funktion unterschiedlich oft angepasst. Dadurch entsteht eine Art „zeitliche Tiefe“ des Modells, anstatt eines flachen Systems, das nur in einem Takt lernt.
HOPE-Architektur als praktische Umsetzung
Als Proof-of-Concept entwickelten die Forscher die HOPE-Architektur. Sie basiert auf sogenannten Titans: Langzeitgedächtnis-Modulen, die Informationen danach priorisieren, wie unerwartet sie für das Modell sind. Je größer die Abweichung zwischen der Vorhersage des Modells und den tatsächlichen Daten ist (technisch als „Surprise“ oder Vorhersagefehler bezeichnet), desto stärker wird die Information im Gedächtnis verankert.
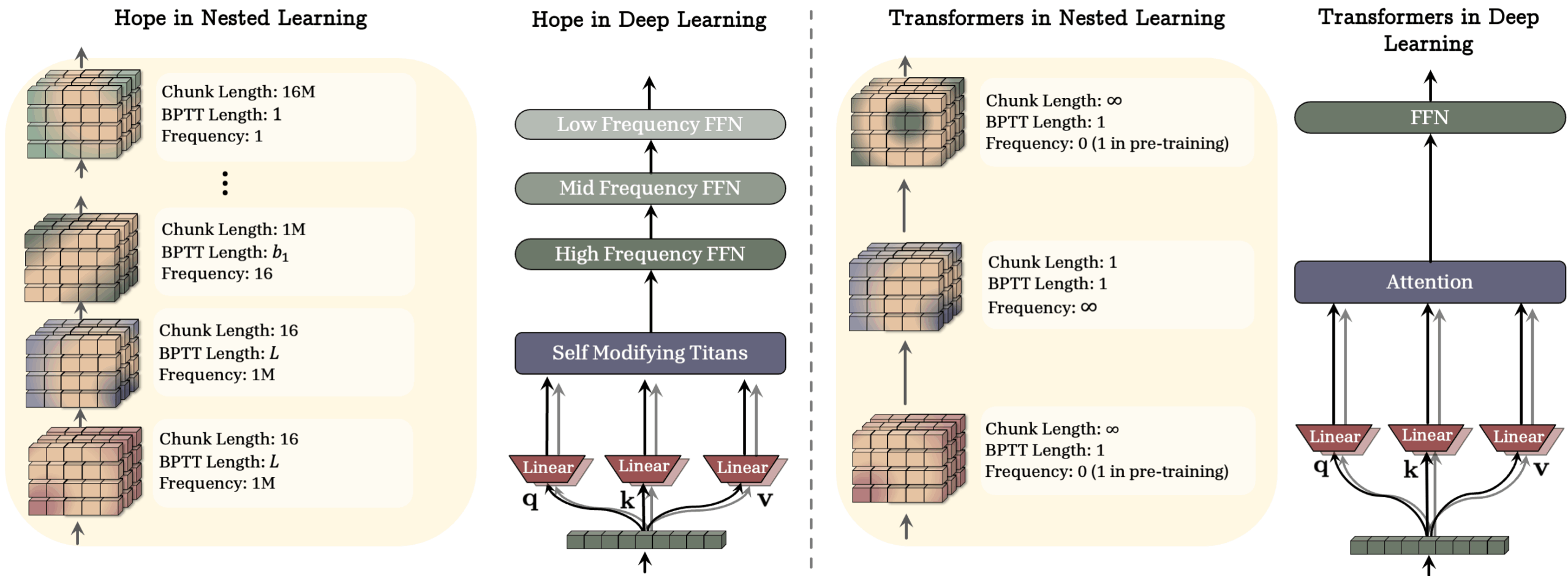
HOPE erweitert dieses Konzept um mehrere Ebenen des kontextbezogenen Lernens und nutzt Continuum-Memory-System-Blöcke für größere Kontextfenster. Die schnelleren Ebenen verarbeiten laufend den aktuellen Input, langsamere Ebenen fassen in größeren Abständen zusammen, was davon langfristig relevant ist. Das System kann seine eigenen Gedächtnisstrukturen anpassen und sich selbst modifizieren.
Damit stellt HOPE die gängige Pipeline „einmal vortrainieren, dann einfrieren und nur noch anwenden“ infrage. Statt eines Modells, das praktisch mit einem Wissensstand „eingesperrt“ wird, zielt Nested Learning auf Modelle, die während ihres gesamten Einsatzes weiterlernen und Erfahrungen aus dem laufenden Betrieb in dauerhaftes Wissen überführen können.
Tests zeigen Verbesserungen bei verschiedenen Aufgaben
Die Tests umfassten Sprachmodellierung und Common-Sense-Reasoning-Aufgaben. HOPE erreichte bei Modellen mit 1,3 Milliarden Parametern, die auf 100 Milliarden Token trainiert wurden, bessere Werte als Transformer++ und andere moderne Architekturen wie RetNet und DeltaNet.
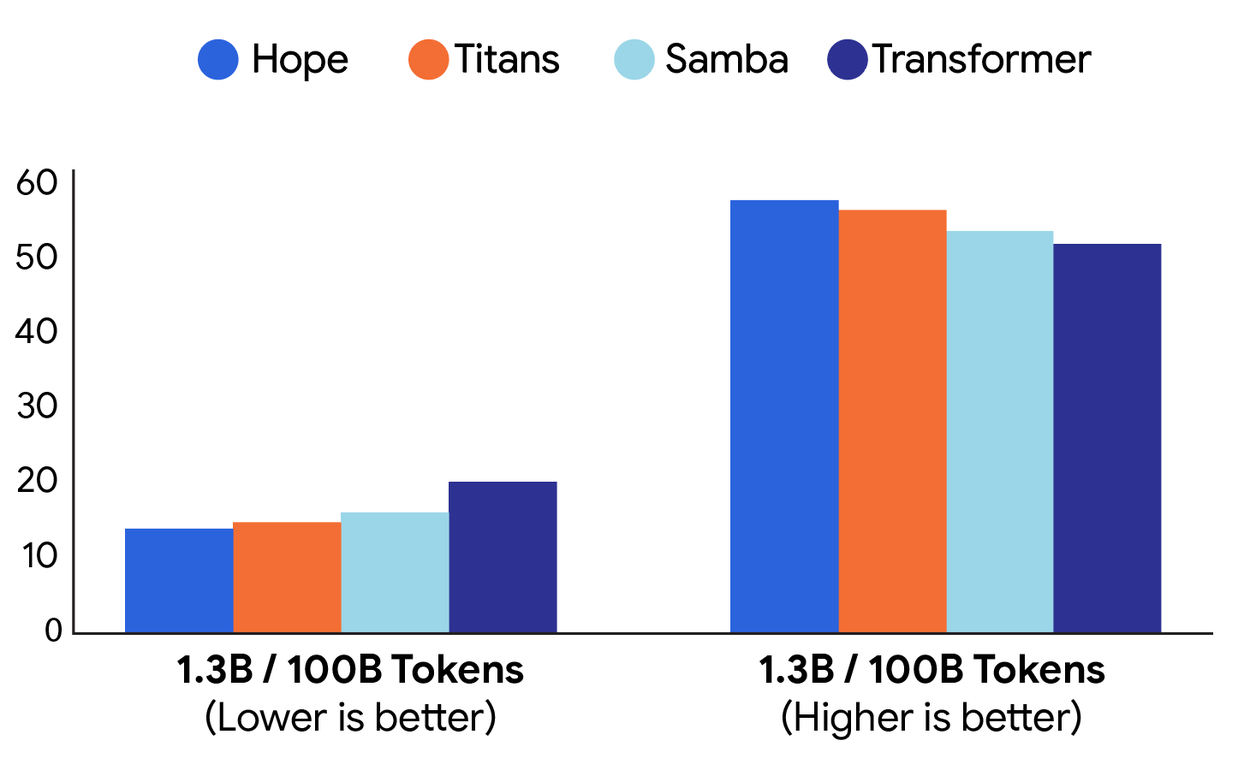
Bei Long-Context-Aufgaben zeigte HOPE Verbesserungen bei der Gedächtnisverwaltung. In Needle-in-Haystack-Tests, bei denen spezifische Informationen in großen Textmengen gefunden werden müssen, schnitt das System besser ab als Vergleichsmodelle.
Die Forscher testeten verschiedene Modellgrößen von 340 Millionen bis 1,3 Milliarden Parametern. Die Verbesserungen waren konsistent über verschiedene Benchmarks hinweg, wobei die Unterschiede je nach Aufgabe variierten. Insgesamt stützt die Studie die These, dass der nächste große Schritt für KI nicht nur in noch mehr Parametern liegt, sondern in Architekturen mit einer reicheren Hierarchie von Lern- und Gedächtnisgeschwindigkeiten. Eine Reproduktion des Papers ist bei Github verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.